Sun HPC ClusterTools 5 Software Performance Guide 5 Software Performance Guide
|
| Sun HPC ClusterTools 5 Software Performance Guide
|
| C H A P T E R 5 |
|
One-Sided Communication |
This chapter describes performance issues related to MPI-2 standard one-sided communication:
The most common use of MPI calls is for two-sided communication. That is, if data moves from one process address space to another, the data movement has to be specified on both sides: the sender's and the receiver's. For example, on the sender's side, it is common to use MPI_Send() or MPI_Isend() calls. On the receiver's side, it is common to use MPI_Recv() or MPI_Irecv() calls. An MPI_Sendrecv() call specifies both a send and a receive.
Even collective calls, such as MPI_Bcast(), MPI_Reduce(), and MPI_Alltoall(), require that every process that contributes or receives data must explicitly do so with the correct MPI call.
The MPI-2 standard introduces one-sided communication. Notably, MPI_Put() and MPI_Get() allow a process to access another process address space without any explicit participation in that communication operation by the remote process.
In selected circumstances, one-sided communication offers several advantages:
Observe two principles to get good performance with one-sided communication with Sun MPI:
1. When creating a window (choosing what memory to make available for one-sided operations), use memory that has been allocated with the MPI_Alloc_mem routine. This suggestion in the MPI-2 standard benefits Sun MPI users:
2. Use one-sided communication over the shared memory (SHM) or remote shared memory (RSM) protocol module. That is, use one-sided communication between MPI ranks that either share the same shared-memory node or communicate via the Sun Fire Link interconnect. Protocol modules are chosen by Sun MPI at runtime and can be checked by setting the environment variable MPI_SHOW_INTERFACES=2 before launching your MPI job.
Further one-sided performance considerations for Sun MPI are discussed in Appendix A and Appendix B.
This section illustrates some of the advantages of one-sided communication with a particular example: matrix transposition. While one-sided communication is probably best suited for dynamic, unstructured computations, matrix transposition offers a relatively simple illustration.
Matrix transposition refers to the exchange of the axes of a rectangular array, flipping the array about the main diagonal. For example, in , after a transposition the array shown on the left side becomes the array shown on the right:

There are many ways of distributing elements of a matrix over the address spaces of multiple MPI processes. Perhaps the simplest is to distribute one axis in a block fashion. For example, our example transposition might appear distributed over two MPI processes (process 0 (p 0), and process 1 (p 1)) such as in :
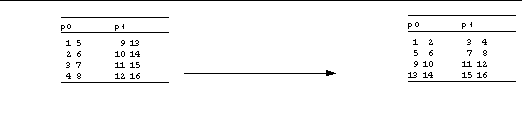
The ordering of multidimensional arrays within a linear address space varies from one programming language to another. A Fortran programmer, though, might think of the preceding matrix transposition as looking like :
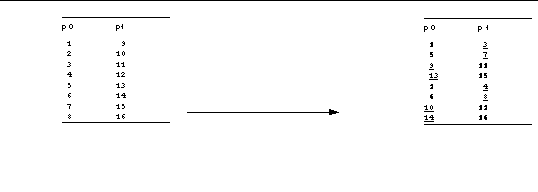
In the final matrix, as shown in , elements that have stayed on the same process show up in bold font, while elements that have moved between processes are underlined.
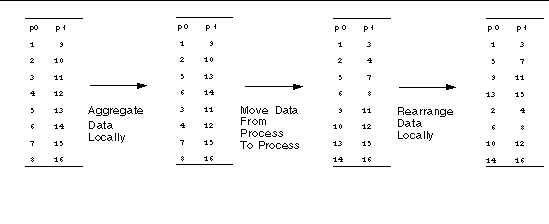
These transpositions move data between MPI processes. Note that no two matrix elements that start out contiguous end up contiguous. There are several strategies to effecting the interprocess data movement:
is an example of maximal aggregation for our 4x4 transposition:
Program A, shown in CODE EXAMPLE 5-1:
Program B, shown in CODE EXAMPLE 5-2:
Test program B should outperform test program A because one-sided interprocess communication can write more directly to a remote process address space.
Program C, shown inCODE EXAMPLE 5-3:
Test program C should outperform test program B because program C eliminates aggregation before the interprocess communication. Such a strategy would be more difficult to implement with two-sided communication, which would have to make trade-offs between programming complexity and increased interprocess synchronization.
Program D, shown in CODE EXAMPLE 5-4:
Test program D eliminates all local data movement before and after the interprocess step, but it is slow because it moves all the data one matrix element at a time.
Test programs A, B, C, and D use the utility routines shown in CODE EXAMPLE 5-5, CODE EXAMPLE 5-6, and CODE EXAMPLE 5-7 to initialize parameters, initialize the test matrix, and check the transposition.
Here are sample timings for the three factors on an (older-generation) Sun Enterprise 6000 server. An 8192x8192 matrix of 8-byte (64-bit) elements is transposed using 16 CPUs (that is, distributed over MPI processes).
Note that test program B is twice as fast in interprocess communication as test program A. This increased speed is because two-sided communication on a shared-memory server, while efficient, still moves data into a shared-memory area and then out again. In contrast, one-sided communication moves data directly from the address space of one process into that of the other. The aggregate bandwidth of the interprocess communication step for the one-sided case is:
8192 x 8192 x 8 byte / 0.466 seconds = 1.1 Gbyte/second
which is very close to the maximum theoretical value supported by this server (half of 2.6 Gbyte/second).
Further, the cost of aggregating data before the interprocess communication step can be eliminated, as demonstrated in test program C. This change adds a modest amount of time to the interprocess communication step, presumably due to the increased number of MPI_Put() calls that must be made. The most important advantage of this technique is that it eliminates the task of balancing the extra programming complexity and interprocess synchronization that two-sided communication requires.
Test program D allows complete elimination of the two local steps, but at the cost of moving data between processes one element at a time. The huge increase in runtime is evident in the timings. The issue here is not just overheads in interprocess data movement, but also the prohibitive cost of accessing single elements in memory rather than entire cache lines.
| Sun HPC ClusterTools 5 Software Performance Guide
| 817-0090-10 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.