Sun HPC ClusterTools 5 Software Performance Guide 5 Software Performance Guide
|
| Sun HPC ClusterTools 5 Software Performance Guide
|
| A P P E N D I X B |
|
Sun MPI Environment Variables |
This appendix describes some Sun MPI environment variables and their effects on program performance. It covers the following topics:
Prescriptions for using MPI environment variables for performance tuning are provided in Chapter 8. Additional information on these and other environment variables can be found in the Sun MPI Programming and Reference Guide.
These environment variables are closely related to the details of the Sun MPI implementation, and their use requires an understanding of the implementation. More details on the Sun MPI implementation can be found in Appendix A.
A blocking MPI communication call might not return until its operation has completed. If the operation has stalled, perhaps because there is insufficient buffer space to send or because there is no data ready to receive, Sun MPI will attempt to progress other outstanding, nonblocking messages. If no productive work can be performed, then in the most general case Sun MPI will yield the CPU to other processes, ultimately escalating to the point of descheduling the process by means of the spind daemon.
Setting MPI_COSCHED=0 specifies that processes should not be descheduled. This is the default behavior.
Setting MPI_SPIN=1 suppresses yields. The default value, 0, allows yields.
By default, Sun MPI polls generally for incoming messages, regardless of whether receives have been posted. To suppress general polling, use MPI_POLLALL=0.
The size of each shared-memory buffer is fixed at 1 Kbyte. Most other quantities in shared-memory message passing are settable with MPI environment variables.
For any point-to-point message, Sun MPI will determine at runtime whether the message should be sent via shared memory, remote shared memory, or TCP. The flowchart in FIGURE B-1 illustrates what happens if a message of B bytes is to be sent over shared memory.
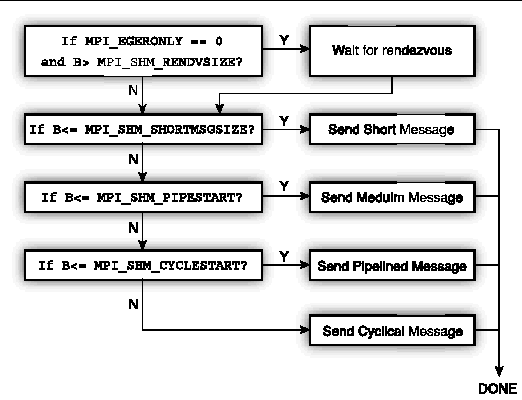
For pipelined messages, MPI_SHM_PIPESIZE bytes are sent under the control of any one postbox. If the message is shorter than 2 x MPI_SHM_PIPESIZE bytes, the message is split roughly into halves.
For cyclic messages, MPI_SHM_CYCLESIZE bytes are sent under the control of any one postbox, so that the footprint of the message in shared memory buffers is 2 x MPI_SHM_CYCLESIZE bytes.
The postbox area consists of MPI_SHM_NUMPOSTBOX postboxes per connection.
By default, each connection has its own pool of buffers, each pool of size MPI_SHM_CPOOLSIZE bytes.
By setting MPI_SHM_SBPOOLSIZE, users can specify that each sender has a pool of buffers, each pool having MPI_SHM_SBPOOLSIZE bytes, to be shared among its various connections. If MPI_SHM_CPOOLSIZE is also set, then any one connection might consume only that many bytes from its send-buffer pool at any one time.
In all, the size of the shared-memory area devoted to point-to-point messages is
n x ( n - 1 ) x ( MPI_SHM_NUMPOSTBOX x ( 64 + MPI_SHM_SHORTMSGSIZE ) + MPI_SHM_CPOOLSIZE )
bytes when per-connection pools are used (that is, when MPI_SHM_SBPOOLSIZE is not set), and
n x ( n - 1 ) x MPI_SHM_NUMPOSTBOX x ( 64 + MPI_SHM_SHORTMSGSIZE ) + n x MPI_SHM_SBPOOLSIZE
bytes when per-sender pools are used (that is, when MPI_SHM_SBPOOLSIZE is set).
A sender should be able to deposit its message and complete its operation without waiting for any other process. You should typically:
In theory, rendezvous can improve performance for long messages if their receives are posted in a different order than their sends. In practice, the right set of conditions for overall performance improvement with rendezvous messages is rarely met.
Send-buffer pools can be used to provide reduced overall memory consumption for a particular value of MPI_SHM_CPOOLSIZE. If a process will only have outstanding messages to a few other processes at any one time, then set MPI_SHM_SBPOOLSIZE to the number of other processes times MPI_SHM_CPOOLSIZE. Multithreaded applications might suffer, however, since then a sender's threads would contend for a single send-buffer pool instead of for multiple, distinct connection pools.
Pipelining, including for cyclic messages, can roughly double the point-to-point bandwidth between two processes. This is a secondary performance effect, however, since processes tend to get considerably out of step with one another, and since the nodal backplane can become saturated with multiple processes exercising it at the same time.
Collective operations in Sun MPI are highly optimized and make use of a general buffer pool within shared memory. MPI_SHM_GBPOOLSIZE sets the amount of space available on a node for the "optimized" collectives in bytes. By default, it is set to 20971520 bytes. This space is used by MPI_Bcast(), MPI_Reduce(), MPI_Allreduce(), MPI_Reduce_scatter(), and MPI_Barrier(), provided that two or more of the MPI processes are on the node.
Memory is allocated from the general buffer pool in three different ways:
In essence, MPI_SHM_BCASTSIZE and MPI_SHM_REDUCESIZE set the pipeline sizes for broadcast and reduce operations on large messages. Larger values can improve the efficiency of these operations for very large messages, but the amount of time it takes to fill the pipeline can also increase. Typically, the default values are suitable, but if your application relies exclusively on broadcasts or reduces of very large messages, then you can try doubling or quadrupling the corresponding environment variable using one of the following:
% setenv MPI_SHM_BCASTSIZE 65536 % setenv MPI_SHM_BCASTSIZE 131072 % setenv MPI_SHM_REDUCESIZE 512 % setenv MPI_SHM_REDUCESIZE 1024 |
If MPI_SHM_GBPOOLSIZE proves to be too small and a collective operation happens to be unable to borrow memory from this pool, the operation will revert to slower algorithms. Hence, under certain circumstances, performance optimization could dictate increasing MPI_SHM_GBPOOLSIZE.
TCP ensures reliable dataflow, even over los-prone networks, by retransmitting data as necessary. When the underlying network loses a lot of data, the rate of retransmission can be very high, and delivered MPI performance will suffer accordingly. Increasing synchronization between senders and receivers by lowering the TCP rendezvous threshold with MPI_TCP_RENDVSIZE might help in certain cases. Generally, increased synchronization will hurt performance, but over a loss-prone network it might help mitigate performance degradation.
If the network is not lossy, then lowering the rendezvous threshold would be counterproductive and, indeed, a Sun MPI safeguard might be lifted. For reliable networks, use
to speed MPI_Gather() and MPI_Gatherv() performance.
The RSM protocol has some similarities with the shared-memory protocol, but it also differs substantially, and environment variables are used differently.
The maximum size of a short message is MPI_RSM_SHORTMSGSIZE bytes, with a default value of 3918 bytes. Short RSM messages can span multiple postboxes, but they still do not use any buffers.
The most data that will be sent under any one postbox using buffers for pipelined messages is MPI_RSM_PIPESIZE bytes.
There are MPI_RSM_NUMPOSTBOX postboxes for each RSM connection.
If MPI_RSM_SBPOOLSIZE is unset, then each RSM connection has a buffer pool of MPI_RSM_CPOOLSIZE bytes. If MPI_RSM_SBPOOLSIZE is set, then each process has a pool of buffers that is MPI_RSM_SBPOOLSIZE bytes per remote node for sending messages to processes on the remote node.
Unlike the case of the shared-memory protocol, values of the MPI_RSM_PIPESIZE, MPI_RSM_CPOOLSIZE, and MPI_RSM_SBPOOLSIZE environment variables are merely requests. Values set with the setenv command or printed when MPI_PRINTENV is used might not reflect effective values. In particular, only when connections are actually established are the RSM parameters truly set. Indeed, the effective values could change over the course of program execution if lazy connections are employed.
Striping refers to passing a message over multiple hardware links to get the speedup of their aggregate bandwidth. The number of hardware links used for a single message is limited to the smallest of these values:
When a connection is established between an MPI process and a remote destination process, the links that will be used for that connection are chosen. A job can use different links for different connections. Thus, even if MPI_RSM_MAXSTRIPE or rsm_maxstripe is set to 1, the overall job could conceivably still benefit from multiple hardware links.
Use of rendezvous for RSM messages is controlled with MPI_RSM_RENDVSIZE.
Memory is allocated on a node for each remote MPI process that sends messages to it over RSM. If np_local is the number of processes on a particular node, then the memory requirement on the node for RSM message passing from any one remote process is
np_local x ( MPI_RSM_NUMPOSTBOX x 128 + MPI_RSM_CPOOLSIZE )
bytes when MPI_RSM_SBPOOLSIZE is unset, and
np_local x MPI_RSM_NUMPOSTBOX x 128 + MPI_RSM_SBPOOLSIZE
bytes when MPI_RSM_SBPOOLSIZE is set.
The amount of memory actually allocated might be higher or lower than this requirement.
If less memory is allocated than is required, then requested values of MPI_RSM_CPOOLSIZE or MPI_RSM_SBPOOLSIZE (specified with a setenv command and echoed if MPI_PRINTENV is set) can be reduced at runtime. This can cause the requested value of MPI_RSM_PIPESIZE to be overridden as well.
Each remote MPI process requires its own allocation on the node as described previously.
If multi-way stripes are employed, the memory requirement increases correspondingly.
The pipe size should be at most half as big as the connection pool:
2 x MPI_RSM_PIPESIZE 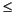 MPI_RSM_CPOOLSIZE
MPI_RSM_CPOOLSIZE
Otherwise, pipelined transfers will proceed slowly. The library adjusts MPI_RSM_PIPESIZE appropriately.
For pipelined messages, a sender must synchronize with its receiver to ensure that remote writes to buffers have completed before postboxes are written. Long pipelined messages can absorb this synchronization cost, but performance for short pipelined messages will suffer. In some cases, increasing the value of MPI_RSM_SHORTMSGSIZE can mitigate this effect.
If the short message size is increased, there must be enough postboxes to accommodate the largest size. The first postbox can hold 23 bytes of payload, while subsequent postboxes in a short messages can each take 63 bytes of payload. Thus, 23 + ( MPI_RSM_NUMPOSTBOX - 1 ) x 63 MPI_RSM_SHORTMSGSIZE.
|
The default value is 0x7fffffff for 32-bit and 0x7fffffffffffffff for 64-bit operating environments. That is, by default there is no cyclic message passing. |
|||
| Sun HPC ClusterTools 5 Software Performance Guide
| 817-0090-10 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.