Sun HPC ClusterTools 5 Software Performance Guide 5 Software Performance Guide
|
| Sun HPC ClusterTools 5 Software Performance Guide
|
| A P P E N D I X A |
|
Sun MPI Implementation |
This appendix discusses various aspects of the Sun MPI implementation that affect program performance:
Many of these characteristics of the Sun MPI implementation can be tuned at runtime with environment variables, as discussed in Appendix B.
In many programs, too much time in MPI routines is spent waiting for particular conditions, such as the arrival of incoming data or the availability of system buffers. This busy waiting costs computational resources, which could be better spent servicing other users' jobs or necessary system daemons.
Sun MPI has a variety of provisions for mitigating the effects of busy waiting. This feature allows MPI jobs to run more efficiently, even when the load of a cluster node exceeds the number of processors it contains. Two methods of avoiding busy waiting are yielding and descheduling:
Yielding is less disruptive to a process than descheduling, but descheduling helps free resources for other processes more effectively. As a result of these policies, processes that are tightly coupled can become coscheduled. Yielding and coscheduling can be tuned with Sun MPI environment variables, as described in Appendix B.
When a process enters an MPI call, Sun MPI might act on a variety of messages. Some of the actions and messages might not pertain to the call at all, but might relate to past or future MPI calls.
To illustrate, consider the following code sequence:
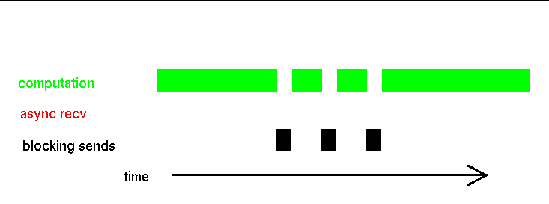
computation CALL MPI_SEND() computation CALL MPI_SEND() computation CALL MPI_SEND() computation |
Sun MPI behaves as one would expect. That is, the computational portion of the program is interrupted to perform MPI blocking send operations, as illustrated in FIGURE A-1.
Now, consider the following code sequence:
computation CALL MPI_IRECV(REQ) computation CALL MPI_WAIT(REQ) computation |
In this case, the nonblocking receive operation conceptually overlaps with the intervening computation, as in FIGURE A-2.
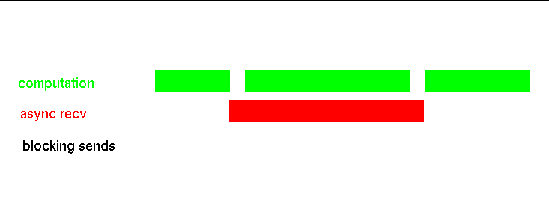
In fact, however, progress on the nonblocking receive is suspended from the time the MPI_Irecv() routine returns until the instant Sun MPI is once again invoked, with the the MPI_Wait() routine. No actual overlap of computation and communication occurs, and the situation is as depicted in FIGURE A-3.

Nevertheless, reasonably good overlap between computation and nonblocking communication can be realized, given that the Sun MPI library is able to progress a number of message transfers within one MPI call. Consider the following code sequence, which combines the previous examples:
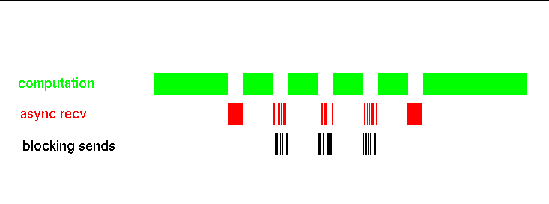
computation CALL MPI_IRECV(REQ) computation CALL MPI_SEND() computation CALL MPI_SEND() computation CALL MPI_SEND() computation CALL MPI_WAIT(REQ) computation |
Now, there is effective overlap of computation and communication, because the intervening, blocking sends also progress the nonblocking receive, as depicted in FIGURE A-4. The performance payoff is not due to computation and communication happening at the same time. Indeed, a CPU still only computes or else moves data--never both at the same time. Rather, the speed-up results because scheduling of computation with the communication of multiple messages is better interwoven.
In general, when Sun MPI is used to perform a communication call, a variety of other activities might also take place during that call, as we have just discussed. Specifically:
1. A process might progress any outstanding, nonblocking sends, depending on the availability of system buffers.
2. A process might progress any outstanding, nonblocking receives, depending on the availability of incoming data.
3. A process might generally poll for any messages whatsoever, to drain system buffers.
4. A process must periodically watch for message cancellations from other processes, in case another process issues an MPI_Cancel() call for a send.
5. A process might choose to yield its computational resources to other processes, if no useful progress is being made.
6. A process might choose to deschedule itself, if no useful progress is being made.
A nonblocking MPI communication call will return whenever there is no progress to be made. For example, system buffers might be too congested for a send to proceed, or there might not yet be any more incoming data for a receive.
In contrast, a blocking MPI communication call might not return until its operation has completed, even when there is no progress to be made. Such a call will repeatedly try to make progress on its operation, also checking all outstanding nonblocking messages for opportunities to perform constructive work (items 1-4). If these attempts prove fruitless, the process will periodically yield its CPU to other processes (item 5). After multiple yields, the process will attempt to deschedule itself by using the spind daemon (item 6).
Sun MPI uses a variety of algorithms for passing messages from one process to another over shared memory. The characteristics of the algorithms, as well as the ways in which algorithms are chosen at runtime, can largely be controlled by Sun MPI environment variables, which are described in Appendix B. This section describes the background concepts.
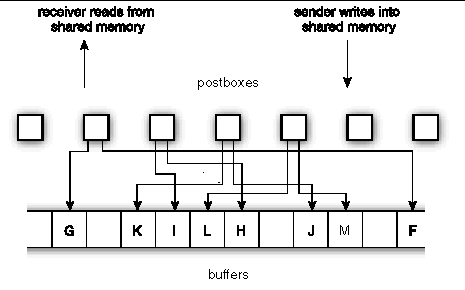
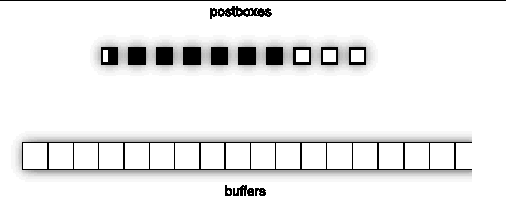
For on-node, point-to-point message passing, the sender writes to shared memory and the receiver reads from there. Specifically, the sender writes a message into shared-memory buffers, depositing pointers to those buffers in shared-memory postboxes. As soon as the sender finishes writing any postbox, that postbox, along with any buffers it points to, might be read by the receiver. Thus, message passing is pipelined--a receiver might start reading a long message, even while the sender is still writing it.
FIGURE A-5 depicts this behavior. The sender moves from left to right, using the postboxes consecutively. The receiver follows. The buffers F, G, H, I, J, K, L, and M are still "in flight" between sender and receiver, and they appear out of order. Pointers from the postboxes are required to keep track of the buffers. Each postbox can point to multiple buffers, and the case of two buffers per postbox is illustrated here. Message data is buffered in the labeled areas.
Pipelining is advantageous for long messages. For medium-size messages, only one postbox is used, and there is effectively no pipelining, as suggested in FIGURE A-6. Message data is buffered in the shaded areas.
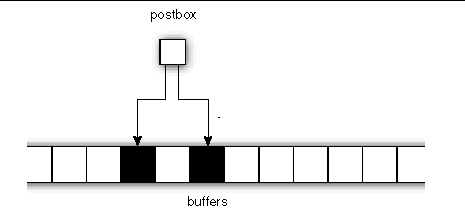
Further, for extremely short messages, data is squeezed into the postbox itself, in place of pointers to buffers that would otherwise hold the data, as illustrated in FIGURE A-7. Message data is buffered in the shaded area.
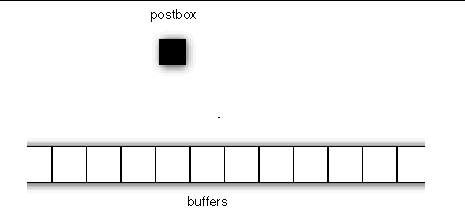
For very long messages, it might be desirable to keep the message from overrunning the shared-memory area. In that limit, the sender is allowed to advance only one postbox ahead of the receiver. Thus, the footprint of the message in shared memory is limited to at most two postboxes at any one time, along with associated buffers. Indeed, the entire message is cycled through two fixed sets of buffers.
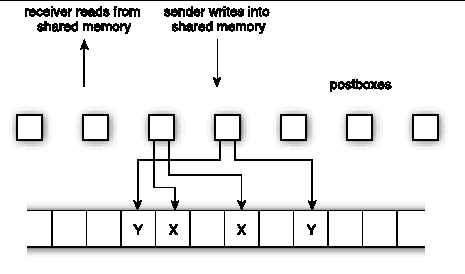
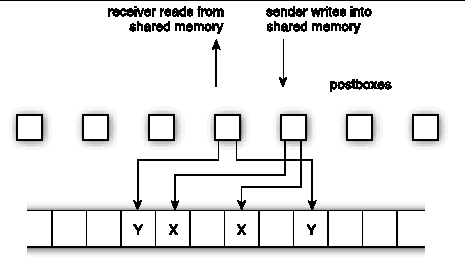
FIGURE A-8 and FIGURE A-9 show two consecutive snapshots of the same cyclic message. The two sets of buffers, through which all the message data is being cycled, are labeled X and Y. The sender remains only one postbox ahead of the receiver. Message data is buffered in the labeled areas.
In the following example, we consider n processes that are collocal to a node.
A connection is a sender-receiver pair. Specifically, for n processes, there are n x (n-1) connections. That is, A sending to B uses a different connection than B sending to A, and any process sending to itself is handled separately.
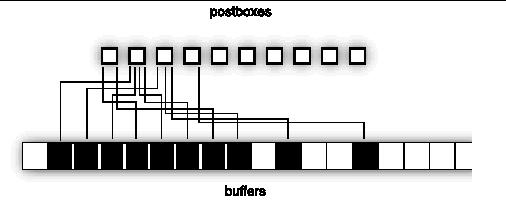
Each connection has its own set of postboxes. For example, in FIGURE A-10, there are two unidirectional connections for each pair of processes. There are 5x4=20 connections in all for the 5 processes. Each connection has shared-memory resources, such as postboxes, dedicated to it. The shared-memory resources available to one sender are shown.
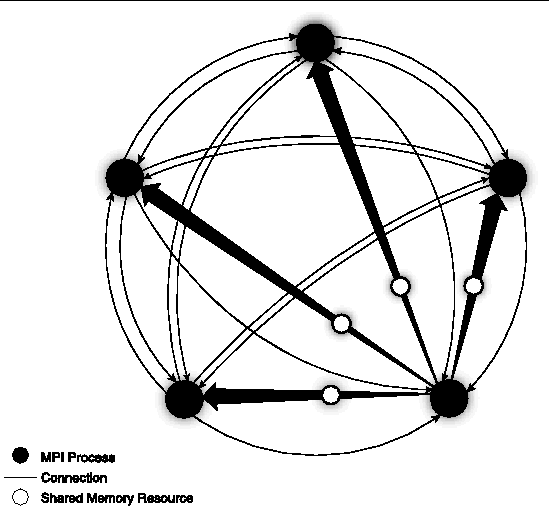
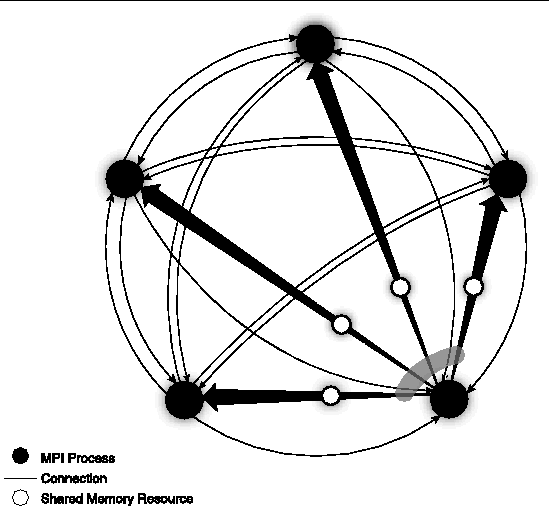
By default, each connection also has its own pool of buffers. Users might override the default use of connection pools, however, and cause buffers to be collected into n pools, one per sender, with buffers shared among a sender's n-1 connections. An illustration of n send-buffer pools is shown in FIGURE A-11. The send-buffer pool available to one sender is shown.
Another issue in passing messages is the use of the rendezvous protocol. By default, a sender will be eager and try to write its message without explicitly coordinating with the receiver (FIGURE A-12). Under the control of environment variables, Sun MPI can employ rendezvous for long messages. Here, the receiver must explicitly indicate readiness to the sender before the message can be sent, as seen in FIGURE A-13.
To force all connections to be established during initialization, set the MPI_FULLCONNINIT environment variable:
% setenv MPI_FULLCONNINIT 1
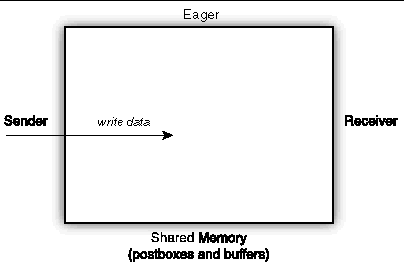
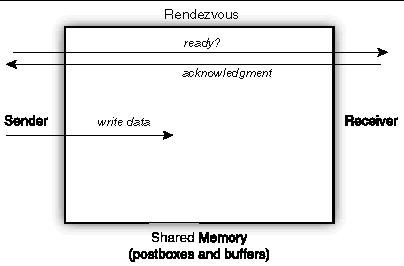
The principal performance consideration is that a sender should be able to deposit its message and complete its operation without coordination with any other process. A sender might be kept from immediately completing its operation if:
Using send-buffer pools, rather than connection pools, helps pool buffer resources among a sender's connections. For a fixed total amount of shared memory, this process can deliver effectively more buffer space to an application, improving performance. Multithreaded applications can suffer, however, because a sender's threads would contend for a single send-buffer pool instead of for (n-1) connection pools.
Rendezvous protocol tends to slow performance of short messages, not only because extra handshaking is involved, but especially because it makes a sender stall if a receiver is not ready. Long messages can benefit, however, if there is insufficient memory in the send-buffer pool, or if their receives are posted in a different order than they are sent.
Pipelining can roughly double the point-to-point bandwidth between two processes. It might have little or no effect on overall application performance, however, if processes tend to get considerably out of step with one another, or if the nodal backplane becomes saturated by multiple processes exercising it at once.
Sun MPI, in default mode, starts up connections between processes on different nodes only as needed. For example, if a 32-process job is started across four nodes, eight processes per node, then each of the 32 processes has to establish 32-8=24 remote connections for full connectivity. If the job relied only on nearest-neighbor connectivity, however, many of these 32x24=768 remote connections would be unneeded.
On the other hand, when remote connections are established on an "as needed" basis, startup is less efficient than when they are established en masse at the time of the MPI_Init() call.
Timing runs typically exclude warmup iterations and, in fact, specifically run several untimed iterations to minimize performance artifacts in start-up times. Hence, both full and lazy connections perform equally well for most interesting cases.
Sun MPI supports high-performance message passing by means of the remote shared memory (RSM) protocol, running on the Sun Fire series high-performance cluster interconnect. Sun MPI over RSM attains:
The RSM protocol has some similarities with the shared-memory protocol, but it also differs substantially, and environment variables are used differently.
Messages are sent over RSM in one of two fashions:
Short-message transfer is illustrated in FIGURE A-14. The first 23 bytes of a short message are sent in one postbox, and 63 bytes are sent in each of the subsequent postboxes. No buffers are used. For example, a 401-byte message travels as 23+63+63+63+63+63+63=401 bytes and requires 7 postboxes. Message data is buffered in the shaded areas.
Pipelining is illustrated in FIGURE A-15. Postboxes are used in order, and each postbox points to multiple buffers. Message data is buffered in the shaded areas.
Many MPI implementations effect collective operations in terms of individual point-to-point messages. In contrast, Sun MPI exploits special, collective, algorithms to exploit the industry-leading size of Sun servers and their high-performance symmetric interconnects to shared memory. These optimizations are employed for one-to-many (broadcast) and many-to-one (reduction) operations, including barriers. To a great extent, users need not be aware of the implementation details, since the benefits are realized simply by utilizing MPI collective calls. Nevertheless, a flavor for the optimizations is given here through an example.
Consider a broadcast operation on 8 processes. The usual, distributed-memory broadcast uses a binary fan-out, as illustrated in FIGURE A-16.
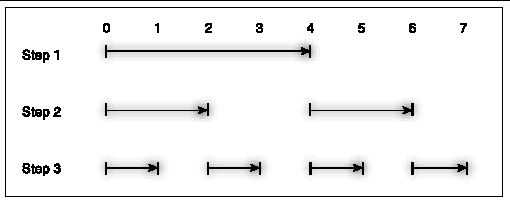
In Step 1, the root process sends the data halfway across the cluster. In Step 2, each process with a copy of the data sends a distance one fourth of the cluster. For 8 processes, the broadcast is completed in Step 3. More generally, the algorithm runs somewhat as
log2(NP) X time to send the data point-to-point
There are several problems with this algorithm. They are explored in the following sections, and the solutions used in Sun MPI are briefly mentioned. For more information, see the paper Optimization of MPI Collectives on Clusters of Large-Scale SMPs, by Steve Sistare, Rolf vandeVaart, and Eugene Loh of Sun Microsystems, Inc. This paper is available at:
http://www.supercomp.org/sc99/proceedings/papers/vandevaa.pdf
In a cluster of SMP nodes, the message-passing performance on a node is typically far better than that between nodes.
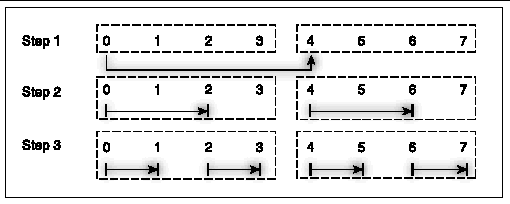
For a broadcast operation, message passing between nodes in a cluster can be minimized by having each participating node receive the broadcast exactly once. In our example, this optimal performance might be realized if, say, processes 0-3 are on one node of a cluster, while processes 4-7 are on another. This is illustrated in FIGURE A-17.
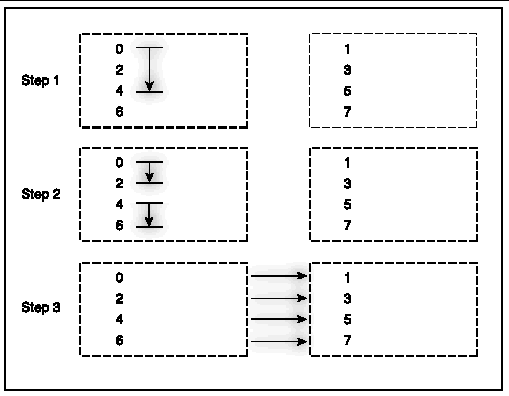
Unless the broadcast algorithm is network aware, however, nodes in the cluster might receive the same broadcast data repeatedly. For instance, if the 8 processes in our example were mapped to two nodes in a round-robin fashion, Step 3 would entail four identical copies of the broadcast data being sent from one node to the other at the same time, as in FIGURE A-18.
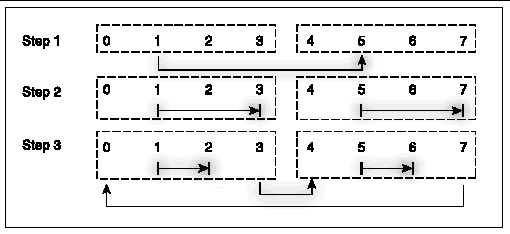
Or, even if the processes were mapped in a block fashion, processes 0-3 to one node and 4-7 to another, if the root process for the broadcast were, say, process 1, excessive internodal data transfers would occur, as in FIGURE A-19.
In Sun MPI, processes are aware of which other processes in their communication groups are collocal with them. This information is used so that collective operations on clusters do not send redundant information over the internodal network.
Communication between two processes on the same node in a cluster is typically effected with high performance by having the sender write data into a shared-memory area and the receiver read the data from that area.
While this provides good performance for point-to-point operations, even better performance is possible for collective operations.
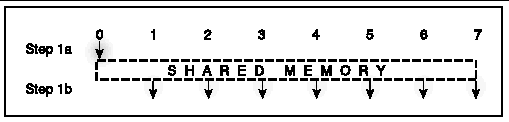
Consider, again, the 8-process broadcast example. The use of shared memory can be illustrated as in FIGURE A-20. The data is written to the shared-memory area 7 times and read 7 times.

In contrast, by using special collective shared-memory algorithms, the number of data transfers can be reduced and data made available much earlier to receiving processes, as illustrated in FIGURE A-21. With a collective implementation, data is written only once, and is made available much earlier to most of the processes.
Sun MPI uses such special collective shared-memory algorithms. Sun MPI also takes into account possible hot spots in the physical memory of an SMP node. Such hot spots can sometimes occur if, for example, a large number of processes are trying to read simultaneously from the same physical memory, or if multiple processes are sharing the same cache line.
Even in the optimized algorithms discussed in the previous section, there is a delay between the time when the collective operation starts and the time when receiving processes can start receiving data. This delay is especially pronounced when the time to transfer the data is long compared with other overheads in the collective operation.
Sun MPI employs pipelining in its collective operations. This means that a large message might be split into components and different components processed simultaneously. For example, in a broadcast operation, receiving processes can start receiving data even before all the data has left the broadcast process.
For example, in FIGURE A-21, the root (sender) writes into the shared-memory area and then the receiving processes read. If the broadcast message is sufficiently large, the receiving processes might well sit idle for a long time, waiting for data to be written. Further, a lot of shared memory would have to be allocated for the large message. With pipelining, the root could write a small amount of data to the shared area. Then, the receivers could start reading as the root continued to write more. This enhances the concurrency of the writer with the readers and reduces the shared-memory footprint of the operation.
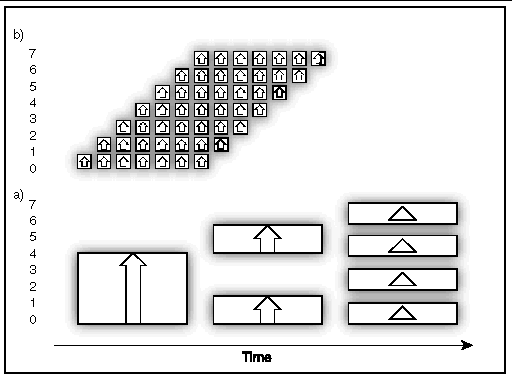
As another example, consider a broadcast among 8 different nodes in a cluster, so that shared-memory optimizations cannot be used. A tree broadcast, such as shown in FIGURE A-16, can be shown schematically as in FIGURE A-22, view a, for a large message. Again, the time to complete this operation grows roughly as
log2(NP) X time to send the data point-to-point
In contrast, if the data were passed along a bucket brigade and pipelined, as illustrated in FIGURE A-22, view b, then the time to complete the operation goes roughly as the time to send the data point-to-point. The specifics depend on the internodal network, the time to fill the pipeline, and so on. The basic point remains, however, that pipelining can improve the performance of operations involving large data transfers.
In practice, multiple algorithms are used to optimize any one particular collective operation. For example, network awareness is used to detect which processes are collocal on a node. Communications between a node might use a particular network algorithm, while collocal processes on a node would use a different shared-memory algorithm. Further, if the data volume is sufficiently large, pipelining might also be used.
Performance models for different algorithms are employed to make runtime choices among the algorithms, based on process group topology, message size, and so on.
An important performance advantage of MPI-2 one-sided communication is that the remote process does not need to be involved. Nevertheless, Sun MPI will invoke the remote process in various circumstances:
There are two ways that the remote process may provide services for one-sided operations:
The crossovers between short and long RSM puts and gets can be tuned with the Sun MPI environment variables MPI_RSM_GETSIZE and MPI_RSM_PUTSIZE. The use of an agent thread may be tuned with MPI_USE_AGENT_THREAD.
| Sun HPC ClusterTools 5 Software Performance Guide
| 817-0090-10 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.