Sun HPC ClusterTools 5 Software Performance Guide 5 Software Performance Guide
|
| Sun HPC ClusterTools 5 Software Performance Guide
|
| C H A P T E R 4 |
|
Performance Programming |
This chapter discusses approaches to consider when you are writing new message-passing programs.
The general rules of good programming apply to any code, serial or parallel. This chapter therefore focuses primarily on optimizing MPI interprocess communications and concludes with an extended example.
When you are working with legacy programs, you need to consider the costs of recoding in relation to the benefits.
The general rules of good programming apply when your goal is to achieve top performance along with robustness and, perhaps, portability.
The first rule of good performance programming is to employ "clean" programming. Good performance is more likely to stem from good algorithms than from clever "hacks." While tweaking your code for improved performance might work well on one hardware platform, those very tweaks might be counterproductive when the same code is deployed on another platform. A clean source base is typically more useful than one laden with many small performance tweaks. Ideally, you should emphasize readability and maintenance throughout the code base. Use performance profiling to identify any hot spots, and then do low-level tuning to fix the hot spots.
One way to garner good performance while simplifying source code is to use library routines. Advanced algorithms and techniques are available to users simply by issuing calls to high-performance libraries. In certain cases, calls to routines from one library might be speeded up simply by relinking to a higher-performing library. As examples,the following table show selected operations and suggests how these operations might be speeded up,
The most dramatic impact on scalability in distributed-memory programs comes from optimizing the data decomposition and communication. Aside from parallelization issues, a great deal of performance enhancement can be achieved by optimizing local (on-node) computation. Common techniques include loop rewriting and cache blocking. Compilers can be leveraged by exploring compilation switches (see Chapter 7).
For the most part, the important topic of optimizing serial computation within a parallel program is omitted here. To learn more about this and other areas of performance optimization, consult Techniques For Optimizing Applications: High Performance Computing, by Rajat Garg and Ilya Shapov, Prentice-Hall, 2001, ISBN:
0-13-093476-3. That volume covers serial optimization and various parallelization models. It deals with programming, compilation, and runtime issues and provides numerous concrete examples.
The default behavior of Sun MPI accommodates many programming practices efficiently. Tuning environment variables at runtime can result in even better performance. However, best performance will typically stem from writing the best programs. This section describes good programming practices under the following headings:
These topics are all interwoven. Clearly, reducing the number and volume of messages can reduce communication overheads, but such overheads are inherent to parallelization of serial computation. Serialization is one extreme of load balancing. Load imbalances manifest themselves as performance issues only because of synchronization. Synchronization, in turn, can be mitigated with message buffering, nonblocking operations, or general polling.
Following the general discussion of these issues, this chapter illustrates them in a case study.
An obvious way to reduce message-passing costs is to reduce the amount of message passing. One method is to reduce the total amount of bytes sent among processes. Further, because a latency cost is associated with each message, aggregating short messages can also improve performance.
Serialization can take many different forms. In multithreaded programming, contention for a lock might induce serialization. In multiprocess programming, serialization might be induced, for example, in I/O operations through a particular process that gathers or scatters data accordingly.
Serialization can also appear as operations that are replicated among all the processes.
Generally, the impediment to great scalability is not as blatant as serialization, but simply a matter of poor work distribution or load balancing among the processes. A multiprocess job completes only when the process with the most work has finished.
More so than for multithreaded programming, load balancing is an issue in message-passing programming because work distribution or redistribution is expensive in terms of programming and communication costs.
Temporally or spatially localized load imbalances sometimes balance against one another. Imagine, for example, a weather simulation in which simulation of daytime weather typically is more computationally demanding than that of nighttime weather because of expensive radiation calculations. If different processes compute on different geographical domains, then over the course of a simulation day each process should see daytime and nighttime. Such circadian imbalances would average out.
As the degree of synchronization in the simulation is increased, however, the extent to which localized load imbalances degrade overall performance magnifies. In our weather example, this means that if MPI processes are synchronized many times over the course of a simulation day, then all processes will run at the slower, day-time rate, even if this forces night-time processes to sit idle at synchronization points.
The cost of interprocess synchronization is often overlooked. Indeed, the cost of interprocess communication is often due not so much to data movement as to synchronization. Further, if processes are highly synchronized, they tend to congest shared resources such as a network interface or SMP backplane, at certain times and leave those resources idle at other times. Sources of synchronization can include:
Typically, synchronization should be minimized for best performance. You should:
If a send can be posted very early and the corresponding receive much later, then there would be no problem with data dependency, because the data would be available before it was needed. If internal system buffering is not provided to hold the in-transit message, however, the completion of the send will in some way become synchronized with the receive. This consideration brings up the topics of buffering and nonblocking operations.
In most MPI point-to-point communication, for example, using MPI_Send and MPI_Recv calls, data starts in a user buffer on the sending process and ends up in a user buffer on the receiving process. In transit, that data might also be buffered internally multiple times by an MPI implementation.
There are performance consequences to such buffering. Among them:
The MPI standard does not require any particular amount of internal buffering for standard MPI_Send operations. Specifically, the standard warns against issuing too many MPI_Send calls without receiving any messages, as this can lead to deadlock. (See Example 3.9 in the MPI 1.1 standard.) MPI does, however, allow users to provide buffering with MPI_Buffer_attach and then to use such buffering with MPI_Bsend or MPI_Ibsend calls.
Sun MPI, as a particular implementation of the standard, allows users to increase internal buffering in two ways. One way, of course, is with the standard, portable MPI_Buffer_attach call. Another is with Sun MPI-specific runtime environment variables, as discussed in Chapter 8.
There are several drawbacks to using MPI_Buffer_attach. They stem from the fact that a buffered send copies data out of the user buffer into a hidden buffer and then issues a non-blocking send (like MPI_Isend) without giving the user access to the request handle. Non-blocking sends (like MPI_Isend) should be used in preference to buffered sends (like MPI_Bsend) because of these effects of buffered sends:
Typically, performance will benefit more if internal buffering is increased by setting Sun MPI environment variables. This is discussed further in Chapter 8.
Sun MPI environment variables might not be a suitable solution in every case. For example, you might want finer control of buffering or a solution that is portable to other systems. (Beware that the MPI standard provides few, if any, performance portability guarantees.) In such cases, it might be preferable to using nonblocking MPI_Isend sends in place of buffered MPI_Bsend calls. The nonblocking calls give finer control over the buffers and better decouple the senders and receivers.
Other examples of internal MPI buffering include MPI_Sendrecv_replace calls and unexpected in-coming messages (that is, messages for which no receive operation has yet been posted).
The MPI standard offers blocking and nonblocking operations. For example, MPI_Send is a blocking send. This means that the call will not return until it is safe to reuse the specified send buffer. On the other hand, the call might well return before the message is received by the destination process.
Nonblocking operations enable you to make message passing concurrent with computation. Basically, a nonblocking operation might be initiated with one MPI call (such as MPI_Isend, MPI_Start, MPI_Startall, and so on) and completed with another (such as MPI_Wait, MPI_Waitall, and so on). Still other calls might be used to probe status, for example, MPI_Test.
Nonblocking operations might entail a few extra overheads. Indeed, use of a standard MPI_Send and MPI_Recv provides the best performance with Sun MPI for highly synchronized processes, such as in simple ping-pong tests. Generally, however, the benefits of nonblocking operations far outweigh their performance shortcomings.
The way these benefits derive, however, can be subtle. Though nonblocking communications are logically concurrent with user computation, they do not necessarily proceed in parallel. That is, typically, either computation or else communication is being affected at any instant by a CPU. How performance benefits derive from nonblocking communications is discussed further in the case study at the end of this chapter
To maximize the benefits of nonblocking operations:
Polling is the activity in which a process searches incoming connections for arriving messages whenever the user code enters an MPI call. Two extremes are:
General polling helps deplete system buffers, easing congestion and allowing senders to make the most progress. On the other hand, it requires receiver buffering of unexpected messages and imposes extra overhead for searching connections that might never have any data.
Directed polling focuses MPI on user-specified tasks and keeps MPI from rebuffering or otherwise unnecessarily handling messages the user code has not yet asked to receive. On the other hand, it does not aggressively deplete buffers, so improperly written codes might deadlock.
Thus, user code is most efficient when the following criteria are all met:
Collective operations, such as MPI_Barrier(), MPI_Bcast(), MPI_Reduce(), MPI_Alltoall(), and the like, are highly optimized in Sun MPI for UltraSPARC servers and clusters of servers. User codes can benefit from the use of collective operations, both to simplify programming and to benefit automatically from the optimizations, which include:
For Sun MPI programming, you need only keep in mind that the collective operations are optimized and that you should use them. The details of the optimizations used in Sun MPI to implement collective operations are available in Appendix A.
While interprocess data movement is considered expensive, data movement within a process can also be costly. For example, interprocess data movement via shared memory consists of two bulk transfers. Meanwhile, if data has to be packed at one end and unpacked at the other, then these steps entail just as much data motion, but the movement will be even more expensive because it is slow and fragmented.
Sun MPI supports message passing over any network that runs TCP. While TCP offers reliable data flow, it does so by retransmitting data as necessary. If the underlying network becomes loss-prone under load, TCP might retransmit a runaway volume of data, causing MPI performance to suffer.
For this reason, applications running over TCP might benefit from throttled communications. The following suggestions are likely to increase synchronization and degrade performance. Nonetheless, they might be needed when running over TCP if the underlying network is losing too much data.
To throttle data transfers, you might:
The following examples illustrate many of the issues raised in the preceding conceptual discussion. These examples use a highly artificial test code to look at the performance of MPI communication and its interplay with computational load imbalance.
The main lessons to draw from this series of example are:
In these examples, each MPI process computes on some data and then circulates that data among the other processes in a ring pattern. That is, 0 sends to 1, 1 sends to 2, 2 sends to 3, and so on, with process np-1 sending to 0. An artificial load imbalance is induced in the computation.
The basic algorithm of this series of examples is illustrated in FIGURE 4-1 for four processes.
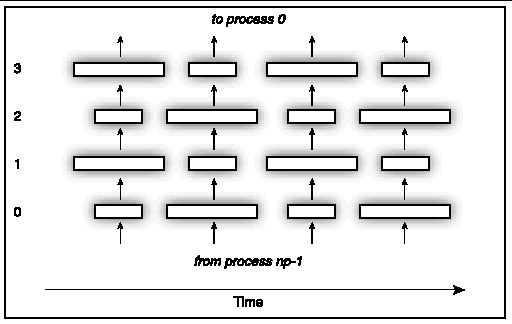
In this figure, time advances to the right, and the processes are labeled vertically from 0 to 3. Processes compute, then pass data in a ring upward. There are temporal and spatial load imbalances, but in the end all processes have the same amount of work on average.
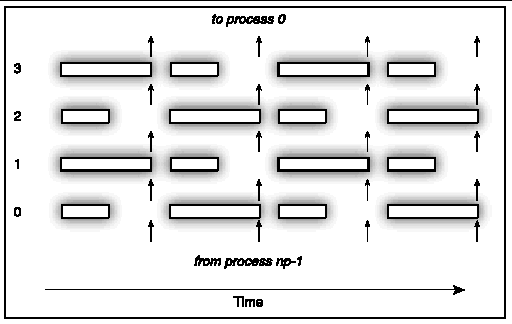
Even though the load imbalance in the basic algorithm averages out over time, performance degradation results if the communication operations are synchronized, as illustrated in FIGURE 4-2.
Several variations on this basic algorithm are used in the following timing experiments, each of which is accompanied by a brief description.
This algorithm causes all processes to send data and then all to receive data. Because no process is receiving when they are all sending, the MPI_Send call must buffer the data to prevent code deadlock. This buffering requirement explicitly violates the MPI 1.1 standard. See Example 3.9, along with associated discussion, in the MPI 1.1 standard.
Nevertheless, Sun MPI can progress messages and avoid deadlock if the messages are sufficiently small or if the Sun MPI environment variable MPI_POLLALL is set to 1, which is the default. (See Appendix A for information on progressing messages.)
The amount of computation to be performed in any iteration on any MPI process is dictated by the variable ncompute and is passed in by the parent subroutine. The array x is made multidimensional because subsequent algorithms will use multibuffering.
This algorithm should not deadlock on any compliant MPI implementation, but it entails unneeded overheads for extra buffering and data copying to "replace" the user data.
This algorithm removes the "replace" overheads by introducing double buffering.
This algorithm attempts to overlap communication with computation. That is, nonblocking communication is initiated before the computation is started, then the computation is performed, and finally the communication is completed. It employs three buffers: one for data being sent, another for data being received, and another for data used in computation.
Sun MPI does not actually overlap communication and computation, as the ensuing discussion makes clear. The real benefit of this approach is in decoupling processes for the case of computational load imbalance.
This algorithm is like Algorithm 4 except that it includes calls to MPI_Testall during computation. (The purpose of this is explained in Use of MPI_Testall.)
To make a functioning example, one of the preceding subroutines should be combined with other source code and compiled using
% mpf90 -fast source-files -lmpi
CODE EXAMPLE 4-6 shows a sample Fortran 90 program that serves as the driver.
Note the following features of the driver program in CODE EXAMPLE 4-6:
You can construct a functioning test code by choosing one of the preceding algorithms and then compiling and linking it together with the driver code.
This section shows sample results for the various algorithms running as 4 MPI processes on a Sun Fire 6800 server with 900-MHz CPUs and a 8-Mbyte L2 cache. The command line for program execution is:
FIGURE 4-3 shows bandwidth as a function of message size for Algorithms 1 and 2.
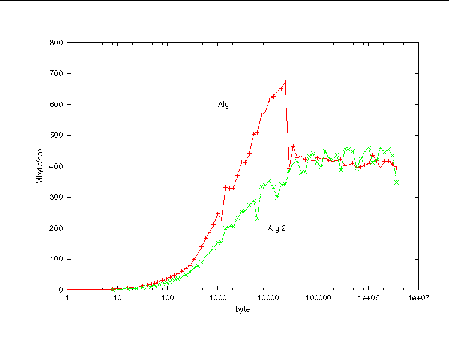
Algorithm 2 proves to be slower than Algorithm 1. This is because MPI_Sendrecv_replace entails extra copying to "replace" data into a single buffer. Further, Sun MPI has special optimizations that cut particular overheads for standard MPI_Send and MPI_Recv calls, which is especially noticeable at small message sizes.
For Algorithm 1, the program reports about 700 Mbytes/s bandwidth for reasonably long messages. Above roughly 24 Kbyte, however, messages complete only due to general polling and the performance impact of processing unexpected messages can be seen in the figure.
Now, let us rerun this experiment with directed polling. This is affected by turning general polling off:
% setenv MPI_POLLALL 0 % mprun -np 4 a.out % unsetenv MPI_POLLALL |
It is generally good practice to unset environment variables after each experiment so that settings do not persist inadvertently into subsequent experiments.
FIGURE 4-4 shows the resulting bandwidth as a function of message size.
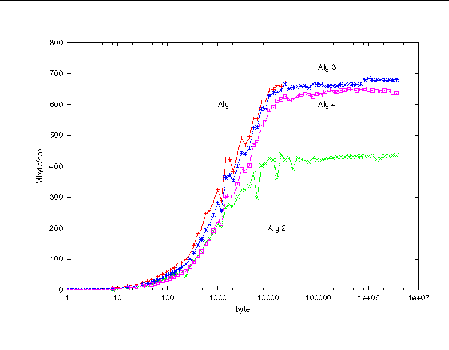
Although it is difficult to make a direct comparison with the previous figure, it is clear that direct polling has improved the bandwidth values across the range of message sizes. This is because directed polling leads to more efficient message passing. Time is not used up in searching all connections needlessly.
The highest bandwidth is delivered by Algorithm 1, but it deadlocks when the message size reaches 24 Kbytes. At this point, the standard send MPI_Send no longer is simply depositing its message into internal buffers and returning. Instead, the receiver is expected to start reading the message out of the buffers before the sender can continue. With general polling (see Baseline Results), processes drained the buffers even before receives were posted.
Algorithm 2 also benefits in performance from directed polling, and it provides an MPI-compliant way of passing the messages. That is, it proceeds deadlock-free even as the messages are made very large. Nevertheless, due to extra internal buffering and copying to effect the "replace" behavior of the MPI_Sendrecv_replace operation, this algorithm has the worst performance of the four.
Algorithm 3 employs MPI_Sendrecv and double buffering to eliminate the extra internal buffering and copying. Algorithm 4 employs nonblocking operations. These are fast and avoid deadlock..
Now, let us examine how Algorithm 4, employing nonblocking operations, fares once processes have drifted out of tight synchronization because of computational load imbalances.
% setenv MPI_POLLALL 0 % mprun -np 4 a.out 1 200 % unsetenv MPI_POLLALL |
The driver routine shown earlier (CODE EXAMPLE 4-6) picks up the command-line arguments (1 200) to induce an artificial load imbalance among the MPI processes.
CODE EXAMPLE 4-5 shows bandwidth as a function of message size when nonblocking operations are used.
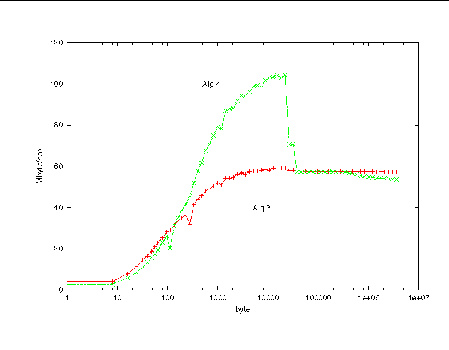
While Algorithm 3 (MPI_Sendrecv) is comparable to Algorithm 4 (MPI_Isend, MPI_Irecv, MPI_Waitall) for synchronized processes, the nonblocking operations in Algorithm 4 offer the potential to decouple the processes and improve performance when there is a computational load imbalance.
The reported bandwidths are substantially decreased because they now include non-negligible computation times.
The internal buffering of Sun MPI becomes congested at longest message sizes, however, making the two algorithms perform equally. This behavior sets in at 24 Kbytes.
Twice now, we have seen that the internal buffering becomes congested at 24 Kbytes. This leads to deadlock in the case of Algorithm 1 and directed polling. It also leads to synchronization of processes with Algorithm 4, even though that algorithm employs nonblocking operations.
Note that Sun MPI has access to multiple protocol modules (PMs) to send messages over different hardware substrates. For example, two processes on the same SMP node exchange messages via the SHM (shared-memory) PM. If the two processes were on different nodes of a cluster interconnected by some commodity network, they would exchange messages via the TCP (standard Transmission Control Protocol) PM. The 24-Kbyte limit we are seeing is specific to the SHM PM.
However, the 24-Kbyte SHM PM buffers can become congested. Buffer sizes might be controlled with MPI_SHM_CPOOLSIZE, whose default value is 24576, or MPI_SHM_SBPOOLSIZE. More information about cyclic message passing and SHM PM buffers might be found in Appendix A. More information about the associated environment variables might be found in Appendix B.
Here, we have set the environment variables not only to employ direct polling, but also to increase internal buffering.
FIGURE 4-6 shows bandwidth as a function of message size for the case of highly synchronized processes (the command line specifying a.out without additional arguments).
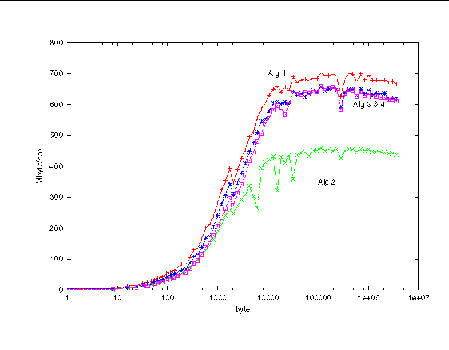
Having increased the buffering, we see that our illegal Algorithm 1 no longer deadlocks and is once again the performance leader. Strictly speaking, of course, it is still not MPI-compliant and its use remains nonrobust. Algorithm 2, using MPI_Sendrecv_replace, remains the slowest due to extra buffering and copying.
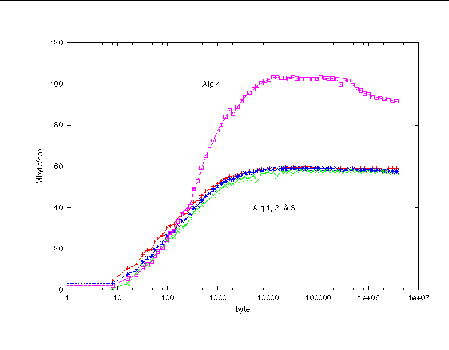
FIGURE 4-7 shows bandwidth as a function of message size for the case of load imbalance (the command line specifying a.out 1 200). Once a computational load imbalance is introduced, Algorithm 4, employing nonblocking operations, becomes the clear leader. All other algorithms are characterized by imbalanced processes advancing in lockstep.
In some cases, for whatever reason, it is not possible to increase Sun MPI internal buffering sufficiently to hold all in-transit messages. For such cases, we can use Algorithm 5, which employs MPI_Testall calls to progress these messages. (For more information on progressing messages, see Progress Engine in Appendix A.)
The third command-line argument to a.out specifies, in some way, the amount of computation to be performed between MPI_Testall calls.
This is a slightly unorthodox use of MPI_Testall. The standard use of MPI_Test and its variants is to test whether specified messages have completed. The use of MPI_Testall here, however, is to progress all in-transit messages, whether specified in the call or not.
FIGURE 4-8 plots bandwidth against message size for the various frequencies of MPI_Testall calls.
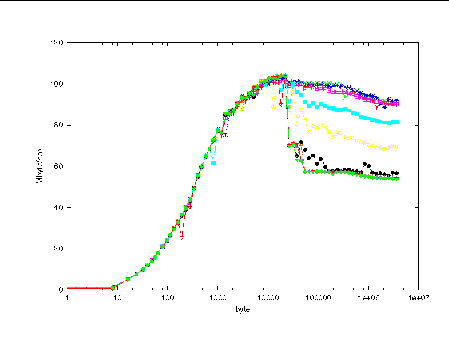
There are too many curves to distinguish individually, but the point is clear. While performance used to dip at 24 Kbytes, introducing MPI_Testall calls in concert with nonblocking message-passing calls has maintained good throughput, even as messages grow to be orders of magnitude beyond the size of the internal buffering. Below the 24-Kbyte mark, of course, the MPI_Testall calls are not needed and do not impact performance materially.
Another view of the data is offered in FIGURE 4-9. This figure plots bandwidth as a function of the amount of computation performed between MPI_Testall calls.
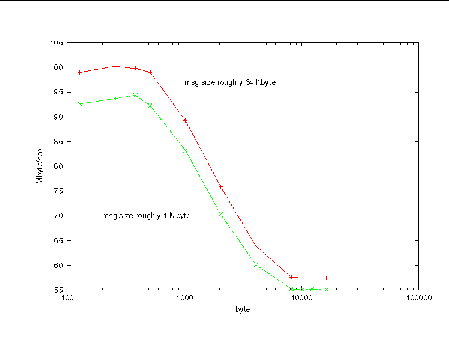
For clarity, FIGURE 4-9 shows only two message sizes: 64 Kbyte and 1 Mbyte. We see that if too little computation is performed, then slight inefficiencies are introduced. More drastic is what happens when too much computation is attempted between MPI_Testall calls. Then, messages are not progressed sufficiently and long wait times lead to degraded performance.
To generalize, if MPI_Testall is called too often, it becomes ineffective at progressing messages. So, the optimal amount of computation between MPI_Testall calls should be large compared with the cost of an ineffective MPI_Testall call, which is on order of roughly 1 microsecond.
When MPI_Testall is called too seldom, interprocess synchronization can induce a severe degradation in performance. As a rule of thumb, the time it takes to fill or deplete MPI buffers sets the upper bound for how much computation to perform between MPI_Testall calls. These buffers are typically on order of tens of Kbytes, memory bandwidths are on order of hundreds of Mbyte/sec. Thus, the upper bound is some fraction of a millisecond.
These are rough rules of thumb, but they indicate that there is a wide range of nearly optimal frequencies for MPI_Testall calls.
Nevertheless, such techniques can be difficult to employ in practice. Challenges include restructuring communication and computation to post nonblocking sends and receives as early as possible while completing them as late as possible and injecting progress-inducing calls effectively.
| Sun HPC ClusterTools 5 Software Performance Guide
| 817-0090-10 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.