| Oracle Data Mining Concepts 10g Release 1 (10.1) Part Number B10698-01 |
|






|
View PDF |
| Oracle Data Mining Concepts 10g Release 1 (10.1) Part Number B10698-01 |
|
|
View PDF |
This chapter describes the principal objects in the Oracle Data Mining Java interface.
A physical data specification (PDS) object specifies the characteristics of the physical data to be used for mining, for example, whether the data is in multi-record case format (transactional) or single-record case (non transactional) format and the roles the various data columns play. The data referenced by a physical data specification object can be used as input to various tasks: model building, testing, computing lift, scoring, transformations, etc.
ODM physical data must be in one of two formats:
These formats describe how to interpret each case as stored in a given database table. See Chapter 2.
A mining function settings (MFS) object contains the high-level parameters for building a mining model.
The mining function settings allow a user to specify the type of problem to solve (for example, classification) without having to specify a particular algorithm. The ODM interface allows a user to override the default algorithm. For example, if the user specifies clustering, the system may select k-means as the algorithm to build the model.
Each MFS object consists of the following:
ODM supports the persistence of mining function settings as independent, named entities in the Data Mining Server (DMS).
Table 6-1 displays function-level parameter settings and their default values.
A mining algorithm settings object contains the parameters associated with a particular algorithm for building a model. It allows expert data miners to fine-tune the behavior of the algorithm. Generally, not all parameters must be specified. Missing parameters are replaced with system default values. Algorithm parameters are algorithm-specific, along with their corresponding default values.
ODM's design, which separates mining algorithm settings from mining function settings, enables non-expert data miners to use ODM effectively, while expert data miners can have the control they need.
Table 6-2 displays the algorithm-level parameters and their default values. The default algorithm for a function appears in boldface type.
A logical data specification (LDS) object is a set of mining attribute (see Section 6.5, "Mining Attributes") instances that describes the logical nature of the data used as input for model building. This set of mining attributes is the basis for producing the signature of the model. Each mining attribute specified in a logical data specification must have a unique name.
As stored in the DMS, each MFS has its own copy of the LDS, even if references are shared in the interface client process.
A mining attribute is a logical concept that describes a domain of data used as input to an ODM data mining operation. Mining attributes are either categorical or numerical. For example, domains of data include "age" ranging from 0 to 100, "buyer" with values true and false. A mining attribute specifies the name, data type, and attribute type (categorical or numeric).
A data usage specification (DUS) object specifies how the attributes in a logical data specification (LDS) instance are used for building a model. A specification contains at most one data usage entry instance for each mining attribute in the LDS. If no data use is specified for an attribute, the default usage is active, implying that the attribute is used in building a model.
Usage includes specifying:
ODM's treatment of attribute names differs from that of Oracle SQL. Oracle SQL can treat attribute names in a case-insensitive manner; ODM attribute names, however, are case-sensitive. The implications of this for ODM users are:
A mining model object is the result of building a model based on a mining function settings object. The representation of the model depends on the algorithm specified by the user or selected by the DMS. Some models can be used for direct inspection, for example, to examine the rules produced from association models or clusters, others to generate predictions, for example, using a classification model.
ODM supports the persistence of mining models as independent, named entities in the DMS. A mining model contains a copy of the mining function settings (MFS) used to build it. Models cannot be stored by the user.
A mining result object contains the end products of one of the following mining tasks: build, test, compute lift, or apply. ODM supports the persistence of mining results as independent, named entities in the DMS.
A mining result object contains the operation start time and end time, the name of the model used, input data location, and output data location (if any) for the data mining operation.
A build result contains the model details. It provides the function and algorithm name of the model.
An apply result names the destination table (schema and table name) for the result.
A test result, for classification models, contains the model accuracy and references the confusion matrix.
A lift result of the lift elements is calculated on a per-quantile basis.
The row indexes of a confusion matrix correspond to actual values observed and used for model testing; the column indexes correspond to predicted values produced by applying the model to the test data. For any pair of actual/predicted indexes, the value indicates the number of records classified in that pairing. For example, a value of 25 for an actual value index of "buyer" and a predicted value index of "nonbuyer" indicates that the model incorrectly classified a "buyer" as a "nonbuyer" 25 times. A value of 516 for an actual/predicted value index of "buyer" indicates that the model correctly classified a "buyer" 516 times.
The predictions were correct 516 + 725 = 1241 times, and incorrect 25 + 10 = 35 times. The sum of the values in the matrix is equal to the number of scored records in the input data table. The number of scored records is the sum of correct and incorrect predictions, which is 1241 + 35 = 1276. The error rate is 35/1276 = 0.0274; the accuracy rate is 1241/1276 = 0.9725.
A confusion matrix provides a quick understanding of model accuracy and the types of errors the model makes when scoring records. It is the result of a test task for classification models.
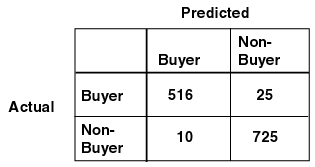
Text description of the illustration confmtrx.gif
A mining apply output instance contains several items that allow users to tailor the results of a model apply operation. Output can be in one or more of the following forms:
Through the mining apply object, ODM supports specifying names for the resulting data columns.
There are two types of input to the apply mining operation: a database table for batch scoring and an individual record for record scoring. Apply input data must contain the same attributes that were used to build the model. However, the input data may contain additional attributes, which may appear in the output to describe the output (see source attribute, below).
Batch scoring using an input database table results in a table called the apply output table. An input record is represented as an instance of RecordInstance that contains a set of AttributeInstance objects, each of which describes the name of the attribute, the data type, and the value. The result of record scoring is also an instance of RecordInstance. The output of the apply mining operation is specified by MiningApplyOutput.
An instance of MiningApplyOutput is a specification of the data to be included in the apply output (either a table or a record) created as the result of the apply mining operation. The columns (or attributes) in the apply output are described by a combination of multiple ApplyContentItem objects. Each item can be one of the following:
Typically, users select "top" with n = 1 for obtaining the top likely prediction for each case from, for example, a classification model. However, other users may require seeing the top three predictions, for example, for recommending products to a customer.
The number of columns in the apply output table varies depending on the combination of items. When multiple target values are specified by MiningApplyOutput (if n > 1), n rows of output table correspond to the prediction for an input row.
Consider an input table of 15 rows. If the top 2 predictions (n = 2) with probabilities are specified in MiningApplyOutput with one source attribute from the input table, there will be 3 columns in the output table: the source attribute, the prediction, and its probability.The number of rows in the output table is 30 because the result of apply for each input row will be 2 rows (top 2) in the output table.
If the input data is multi-record case (transactional), the sequence ID is automatically included in the output table. However, explicit inclusion of source attributes is required for nontransactional data.
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

