| Oracle Data Mining Concepts 10g Release 1 (10.1) Part Number B10698-01 |
|






|
View PDF |
| Oracle Data Mining Concepts 10g Release 1 (10.1) Part Number B10698-01 |
|
|
View PDF |
Data mining tasks include model building, model testing, computing test metrics, and model applying (scoring).
This chapter describes how these tasks are performed using the Java interface for Oracle Data Mining. The objects used by the Java interface are described in Chapter 6.
Table 5-1 compares data mining tasks performed using the Java interface for the different ODM functions.
Your data mining application may require that you export a model to another database or schema. ODM imports and exports PMML models for Naive Bayes classification models and Association models.
Models are built in the Oracle debase. After a model is built, it is persisted in the database and can be accessed by its user-specified unique name. Model build is asynchronous in the Java interface. After a model is built, there is single-user, multi-session access to the model.
The typical steps for model building are as follows:
Seethe Oracle Data Mining Application Developer's Guide.
ODM supports two levels of settings: function and algorithm. When the function level settings do not specify particular algorithm settings, ODM chooses an appropriate algorithm and provides defaults for the relevant parameters. In general, model building at the function level eliminates many of the technical details of data mining.
Figure 5-1 illustrates the build process. Data for building the model may be preprocess for by the user before the build takes place; alternatively, data preparation may take place during the build process. This figure assumes that the algorithm requires binned data. (SVM and NMF do not bin data.) The resulting data table, that is, the build data table, is fed to the appropriate ODM algorithm, along with mining function settings. The algorithm may performs binning or normalization, and then performs the build. The resulting model includes bin boundary tables internal to the algorithm, i.e., the ones that resulted from automatic binning, if the algorithm requires binning. They are not part of the model if you did not choose automatic binning or if the algorithm does not perform binning.
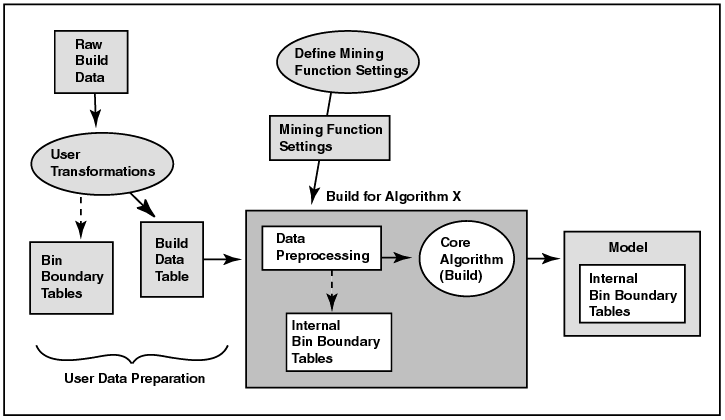
Text description of the illustration build2.gif
Classification and regression models can be tested to get an estimate of their accuracy.
After a model is built, model testing estimates the accuracy of a model's predictions by applying the model to a new data table that has the same format as the build data table. The test results are stored in a mining test result object. A classification test result includes a confusion matrix (see Chapter 6) that allows a user to understand the type and number of classification errors made by the model.
The regression test results provide measures of model accuracy: root mean square error and mean absolute error of the prediction.
Producing a lift calculation is a way to asses a model. ODM supports computing lift for a classification model. Lift can be computed for both binary (2 values) target fields and multiclass (more than 2 values) target fields. Given a designated positive target value (that is, the value of most interest for prediction, such as "buyer," or "has disease"), test cases are sorted according to how confidently they are predicted to be positive cases. Positive cases with highest confidence come first, followed by positive cases with lower confidence. Negative cases with lowest confidence come next, followed by negative cases with highest confidence. Based on that ordering, they are partitioned into quantiles, and the following statistics are calculated:
Cumulative targets can be computed from the quantities that are available in the LiftRresultElement using the following formula:
Applying a classification model such as Naive Bayes or Adaptive Bayes Network to data produces scores or predictions with an associated probability or cost. Applying a clustering model to new data produces, for each case, a predicted cluster identifier and the probability that the case belongs to that cluster. Applying an NMF model to data produces a predicted feature identifier and the match quality of the feature for each case.
The apply data must be in the same format and preprocessing as the data used to build the model.
Figure 5-2 shows the apply process for an algorithm that requires binned data. Note that the input data for the apply process must undergo the same preprocessing undergone by the build data table. The data to be scored must have attributes compatible with those of the build data, that is, it must have the same attributes with the same names and respective data types or there must be a suitable mapping of one to the other. The apply data table can have attributes not found in the build data table. The result of the apply operation is placed in the schema specified by the user.
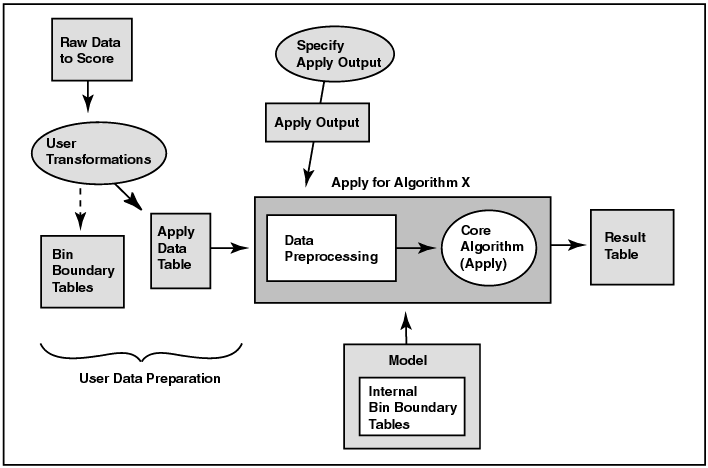
Text description of the illustration apply2.gif
The ODM user specifies the result content. For example, a user may want the customer identifier attribute, along with the score and probability, to be output into a table for each record in the provided mining data. This is specified using the MiningApplyOutput class.
ODM supports the apply operation for a table (a set of cases) or a single case (represented by a RecordInstance Java object). ODM supports multicategory apply, obtaining multiple class values with their associated probabilities for each case.
A data mining application may deploy a model to several database instances so that the scoring can be done at the location where the data resides. In addition, users of different schemas may wish to share models. In both cases it is necessary to export the model from the original schema and then import it into the destination schema. Support for model export and import in the Java interface is provided by PMML.
The deployed models can score using the ODM Scoring Engine, described in.
The Predictive Model MParkup Language (PMML) specifies data mining models using an XML DTD (document type definition). PMML provides a standard representation for data mining models to facilitate model interchange among vendors. PMML is specified by the Data Mining Group (http://www.dmg.org).
The ODM Java interface is both a producer and consumer of PMML models. That is, ODM can produce (generate) a PMML model that can be used by other software that can consume PMML. ODM can also consume PMML models, that is, ODM can convert certain PMML model representations to valid ODM models. ODM is a producer and consumer of two model types: Association models and Naive Bayes classification models.
For more information about model export and import, see Chapter 9.
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

