Release 2 (9.2)
Part Number A96656-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Java Developer's Guide Release 2 (9.2) Part Number A96656-01 |
|
This chapter gives you an overview and examples of how to invoke Java within the database.
In Oracle9i, you utilize Java in one of the following ways:
We recommend that you approach Java development in Oracle9i incrementally, building on what you learn at each step.
Java is a simple, general purpose language for writing stored procedures. JDBC and SQLJ allow Java to access SQL data. They support SQL operations and concepts, variable bindings between Java and SQL types, and classes that map Java classes to SQL types. You can write portable Java code that can execute on a client or a server without change. With JDBC and SQLJ, the dividing line between client and server is usually obvious--SQL operations happen in the server, and application program logic resides in the client.
As you write more complex Java programs, you can gain performance and scalability by controlling the location where the program logic executes. You can minimize network traffic and maximize locality of reference to SQL data. JDBC and SQLJ furnish ways to accomplish these goals. However, as you tend to leverage the object model in your Java application, a more significant portion of time is spent in Java execution, as opposed to SQL data access and manipulation. It becomes more important to understand and specify where Java objects reside and execute in an Internet application.
The way your client calls a Java method depends on the type of Java application. The following sections discuss each of the Java APIs available for creating a Java class that can be loaded into the database and accessed by your client:
You execute Java stored procedures similarly to PL/SQL. Normally, calling a Java stored procedure is a by-product of database manipulation, because it is usually the result of a trigger or SQL DML call.
To invoke a Java stored procedure, you must publish it through a call specification. The following example shows how to create, resolve, load, and publish a simple Java stored procedure that echoes "Hello world".
Define a class, Hello, with one method, Hello.world(), that returns the string "Hello world".
public class Hello { public static String world () { return "Hello world"; } }
javac, as follows:
javac Hello.java
Normally, it is a good idea to specify your CLASSPATH on the javac command line, especially when writing shell scripts or make files. The Java compiler produces a Java binary file--in this case, Hello.class.
Keep in mind where this Java code will execute. If you execute Hello.class on your client system, it searches the CLASSPATH for all supporting core classes it must execute. This search should result in locating the dependent class in one of the following:
In this case, you load Hello.class in the server, where it is stored in the database as a Java schema object. When you execute the world() method of the Hello.class on the server, it finds the necessary supporting classes, such as String, using a resolver--in this case, the default resolver. The default resolver looks for classes in the current schema first and then in PUBLIC. All core class libraries, including the java.lang package, are found in PUBLIC. You may need to specify different resolvers, and you can force resolution to occur when you use loadjava, to determine if there are any problems earlier, rather than at runtime. Refer to "Resolving Class Dependencies" or Chapter 7, "Schema Object Tools" for more details on resolvers and loadjava.
loadjava. You must specify the username and password.
loadjava -user scott/tiger Hello.class
To invoke a Java static method with a SQL CALL, you must publish it with a call specification. A call specification defines for SQL which arguments the method takes and the SQL types it returns.
In SQL*Plus, connect to the database and define a top-level call specification for Hello.world():
SQL> connect scott/tiger connected SQL> create or replace function HELLOWORLD return VARCHAR2 as 2 language java name 'Hello.world () return java.lang.String'; 3 / Function created.
SQL> variable myString varchar2[20]; SQL> call HELLOWORLD() into :myString; Call completed. SQL> print myString; MYSTRING --------------------------------------- Hello world SQL>
The call HELLOWORLD() into :myString statement performs a top-level call in Oracle9i. The Oracle-specific select HELLOWORLD from DUAL also works. Note that SQL and PL/SQL see no difference between a stored procedure that is written in Java, PL/SQL, or any other language. The call specification provides a means to tie inter-language calls together in a consistent manner. Call specifications are necessary only for entry points invoked with triggers or SQL and PL/SQL calls. Furthermore, JDeveloper can automate the task of writing call specifications.
For more information on Java stored procedures, using Java in triggers, call specifications, rights models, and inter-language calls, refer to the Oracle9i Java Stored Procedures Developer's Guide.
Oracle9i supports Java Remote Method Invocation (RMI). All RMI classes and java.net support are in place. In general, RMI is not useful or scalable in Oracle9i Java applications. While the RMI Server that Sun Microsystems supplies does function on the Oracle9i JVM platform, it is useful only within the context of a single call. This is because the RMI Server forks daemon threads, which are killed off at the end of call (that is, when all non-deamon threads return). If the RMI server session is reentered in a subsequent call, these daemon threads aren't restarted and the RMI server won't function properly.
The Java Native Interface (JNI) is a standard programming interface for writing Java native methods and embedding the Java virtual machine into native applications. The primary goal of JNI is to provide binary compatibility of Java applications that use platform-specific native libraries.
Oracle does not support the use of JNI in Oracle9i Java applications. If you use JNI, your application is not 100% pure Java, and the native methods require porting between platforms. Native methods have the potential for crashing the server, violating security, and corrupting data.
You can use one of two protocols for querying the database from a Java client. Both protocols establish a session with a given username/password to the database and execute SQL queries against the database.
JDBC is an industry-standard API developed by Sun Microsystems that allows you to embed SQL statements as Java method arguments. JDBC is based on the X/Open SQL Call Level Interface and complies with the SQL92 Entry Level standard. Each vendor, such as Oracle, creates its JDBC implementation by implementing the interfaces of the Sun Microsystems java.sql package. Oracle offers three JDBC drivers that implement these standard interfaces:
For the developer, using JDBC is a step-by-step process of creating a statement object of some type for your desired SQL operation, assigning any local variables that you want to bind to the SQL operation, and then executing the operation. This process is sufficient for many applications but becomes cumbersome for any complicated statements. Dynamic SQL operations, where the operations are not known until runtime, require JDBC. In typical applications, however, this represents a minority of the SQL operations.
SQLJ offers an industry-standard way to embed any static SQL operation directly into Java source code in one simple step, without requiring the individual steps of JDBC. Oracle SQLJ complies with ANSI standard X3H2-98-320.
SQLJ consists of a translator--a precompiler that supports standard SQLJ programming syntax--and a runtime component. After creating your SQLJ source code in a .sqlj file, you process it with the translator, which translates your SQLJ source code to standard Java source code, with SQL operations converted to calls to the SQLJ runtime. In the Oracle SQLJ implementation, the translator invokes a Java compiler to compile the Java source. When your Oracle SQLJ application runs, the SQLJ runtime calls JDBC to communicate with the database.
SQLJ also allows you to catch errors in your SQL statements before runtime. JDBC code, being pure Java, is compiled directly. The compiler has no knowledge of SQL, so it is unaware of any SQL errors. By contrast, when you translate SQLJ code, the translator analyzes the embedded SQL statements semantically and syntactically, catching SQL errors during development, instead of allowing an end-user to catch them when running the application.
The following is an example of a simple operation, first in JDBC code and then SQLJ code.
JDBC:
// (Presume you already have a JDBC Connection object conn) // Define Java variables String name; int id=37115; float salary=20000; // Set up JDBC prepared statement. PreparedStatement pstmt = conn.prepareStatement ("select ename from emp where empno=? and sal>?"); pstmt.setInt(1, id); pstmt.setFloat(2, salary); // Execute query; retrieve name and assign it to Java variable. ResultSet rs = pstmt.executeQuery(); while (rs.next()) { name=rs.getString(1); System.out.println("Name is: " + name); } // Close result set and statement objects. rs.close() pstmt.close();
name, id, and salary.prepareStatement() method of the connection object).
You can use a prepared statement whenever values within the SQL statement must be dynamically set. You can use the same prepared statement repeatedly with different variable values. The question marks in the prepared statement are placeholders for Java variables and are given values in the pstmt.setInt() and pstmt.setFloat() lines of code. The first "?" is set to the int variable id (with a value of 37115). The second "?" is set to the float variable salary (with a value of 20000).
By comparison, here is some SQLJ code that performs the same task. Note that all SQLJ statements, both declarations and executable statements, start with the #sql token.
SQLJ:
String name; int id=37115; float salary=20000; #sql {select ename into :name from emp where empno=:id and sal>:salary}; System.out.println("Name is: " + name);
SQLJ, in addition to allowing SQL statements to be directly embedded in Java code, supports Java host expressions (also known as bind expressions) to be used directly in the SQL statements. In the simplest case, a host expression is a simple variable as in this example, but more complex expressions are allowed as well. Each host expression is preceded by ":" (colon). This example uses Java host expressions name, id, and salary. In SQLJ, because of its host expression support, you do not need a result set or equivalent when you are returning only a single row of data.
This section presents a complete example of a simple SQLJ program:
import java.sql.*; import sqlj.runtime.ref.DefaultContext; import oracle.sqlj.runtime.Oracle; #sql iterator MyIter (String ename, int empno, float sal); public class MyExample { public static void main (String args[]) throws SQLException { Oracle.connect ("jdbc:oracle:thin:@oow11:5521:sol2", "scott", "tiger"); #sql { insert into emp (ename, empno, sal) values ('SALMAN', 32, 20000) }; MyIter iter; #sql iter={ select ename, empno, sal from emp }; while (iter.next()) { System.out.println (iter.ename()+" "+iter.empno()+" "+iter.sal()); } } }
#sql iterator MyIter (String ename, int empno, float sal);
This declaration results in SQLJ creating an iterator class MyIter. Iterators of type MyIter can store results whose first column maps to a Java String, whose second column maps to a Java int, and whose third column maps to a Java float. This definition also names the three columns--ename, empno, and sal, respectively--to match the table column names in the database. MyIter is a named iterator. See Chapter 3 of the Oracle9i SQLJ Developer's Guide and Reference to learn about positional iterators, which do not require column names.
Oracle.connect("jdbc:oracle:thin:@oow11:5521:sol2","scott", "tiger");
Oracle SQLJ furnishes the Oracle class, and its connect() method accomplishes three important things:
scott, password tiger) at the specified URL (host oow11, port 5521, SID so12, "thin" JDBC driver).while (iter.next()){ System.out.println(iter.ename()+" "+iter.empno()+" "+iter.sal()); }
The next() method is common to all iterators and plays the same role as the next() method of a JDBC result set, returning true and moving to the next row of data if any rows remain. You access the data in each row by calling iterator accessor methods whose names match the column names (this is a characteristic of all named iterators). In this example, you access the data using the methods ename(), empno(), and sal().
SQLJ uses strong typing--such as iterators--instead of result sets, which allows your SQL instructions to be checked against the database during translation. For example, SQLJ can connect to a database and check your iterators against the database tables that will be queried. The translator will verify that they match, allowing you to catch SQL errors during translation that would otherwise not be caught until a user runs your application. Furthermore, if changes are subsequently made to the schema, you can determine if this affects the application simply by re-running the translator.
Integrated development environments such as Oracle JDeveloper, a Windows-based visual development environment for Java programming, can translate, compile, and customize your SQLJ program for you as you build it. If you are not using an IDE, then use the front-end SQLJ utility, sqlj. Run it as follows:
%sqlj MyExample.sqlj
The SQLJ translator checks the syntax and semantics of your SQL operations. You can enable online checking to check your operations against the database. If you choose to do this, you must specify an example database schema in your translator option settings. It is not necessary for the schema to have identical data to the one the program will eventually run against; however, the tables should have columns with corresponding names and datatypes. Use the user option to enable online checking and specify the username, password, and URL of your schema, as in the following example:
%sqlj -user=scott/tiger@jdbc:oracle:thin:@oow11:5521:sol2 MyExample.sqlj
Many SQLJ applications run on a client; however, SQLJ offers an advantage in programming stored procedures--which are usually SQL-intensive--to run in the server.
There is almost no difference between coding for a client-side SQLJ program and a server-side SQLJ program. The SQLJ runtime packages are automatically available on the server, and there are just the following few considerations:
System.out in a deployed server application.To run a SQLJ program in the server, presuming you developed the code on a client, you have two options:
.jar file first.In either case, use the Oracle loadjava utility to load the file or files to the server. See the Oracle9i SQLJ Developer's Guide and Reference for more information.
The steps in converting an existing SQLJ client-side application to run in the server are as follows. Assume this is an application that has already been translated on the client:
.jar file for your application components.loadjava utility to load the .jar file to the server.MyExample application in the server:
create or replace procedure SQLJ_MYEXAMPLE as language java
name `MyExample.main(java.lang.String[])';
You can then execute SQLJ_MYEXAMPLE, as with any other stored procedure.
All the Oracle JDBC drivers communicate seamlessly with Oracle SQL and PL/SQL, and it is important to note that SQLJ interoperates with PL/SQL. You can start using SQLJ without having to rewrite any PL/SQL stored procedures. Oracle SQLJ includes syntax for calling PL/SQL stored procedures and also allows PL/SQL anonymous blocks to be embedded in SQLJ executable statements, just as with SQL operations.
Oracle9i furnishes a debugging capability that is useful for developers who use the JDK's jdb debugger. Two interfaces are supported.
DebugProxy makes remote Java programs appear to be local. It lets any debugger that supports the sun.tools.debug.Agent protocol connect to a program as if the program were local. The proxy forwards requests to the server and returns results to the debugger.
For detailed instructions, see the Oracle9i Java Developer's Guide.
http://java.sun.com/j2se/1.3/docs/guide/jpda/, http://java.sun.com/j2se/1.4/docs/guide/jpda/.) The use of this interface is documented on OTN. The JDWP protocol supports many new features, including the ability to listen for connections (no more DebugProxy), change the values of variables while debugging, and evaluate arbitrary Java expressions, including method evaluation.
Oracle's JDeveloper provides a user-friendly integration with these debugging features. See the JDeveloper documentation for more information on how to debug your Java application through JDeveloper. Other independent IDE vendors will be able to integrate their own debuggers with Oracle9i.
The Sun Microsystems jdb debugger attaches itself to an executing process, and helps you debug the executing process. The application that you are debugging must have been compiled with the debug option (-g).
In Oracle9i, your Java program executes remotely on a server. The server can reside on the same physical machine, but it typically resides on a separate machine. Oracle9i provides a method for jdb to debug a Java application loaded into Oracle9i.
This method involves an debug agent that is executing on the Oracle9i server and communicating with the executing Java application, a debug proxy that exists on the client and communicates with the Oracle9i server, and a way for jdb to attach itself to the debug proxy. Figure 3-1 shows the relationship between the debug agent, the debug proxy, and the jdb debugger.
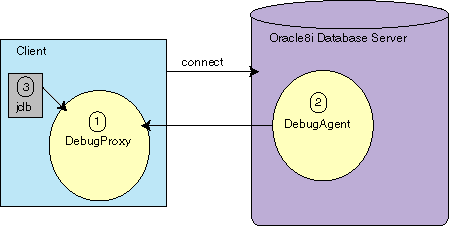
Text description of the illustration debug.gif
As shown in Figure 3-1, the steps for remotely debugging your Java application are as follows:
DebugProxy. The DebugProxy waits for a DebugAgent to attach to it from the server.DebugAgent giving it the debug proxy address. This starts the communication between the debug agent and the debug proxy.jdb debugger to the debug proxy. Once attached, use the regular jdb commands.The code must be compiled with the -g option and the source must be made available for the debug agent to locate.
You can cause your application to be compiled with the debug option (-g) in one of the two following ways:
set_compiler_option procedure, as follows:
SQL> call dbms_java.set_compiler_option('myPackage.myCode','debug','true');
|
Note: The |
Then, you must load the source code using loadjava, as follows:
% loadjava -u SCOTT/TIGER -v -f -r myCode.java
The server will compile this class with the debug option. Also, the server now has access to both the source and the compiled binary, which the debug agent needs for showing the breakpoints.
g option, load the compiled class into the server, and copy the Java source file to the file system where Oracle9i exists, as follows:
% javac -g MyCode.java % loadjava -u SCOTT/TIGER -v -f -r myCode.class % ftp dbhost > cd /private/sourcecode > put myCode.java
When jdb starts, set the location of the source code with jdb's 'use' command. This enables the debug agent to find the source code.
> use /private/sourcecode
The DebugProxy class enables your remote Java application appear to be local. The debug proxy forwards all jdb requests to the debug agent on the server and returns the results to the attached jdb debugger.
Once started, the debug proxy waits for the debug agent to attach itself. Assuming the aurora_client.jar file is part of your CLASSPATH, start the debug proxy as follows:
debugproxy
You can also specify a particular port to wait on.
debugproxy -port 2286
The proxy prints out its name, its address, and the port it is waiting on.
Proxy Name: yourmachinename Proxy Address: aaa.bbb.ccc.ddd Proxy Port: 2286
However, the easiest method to start the DebugProxy is to append a command to start up the jdb debugger at the end of the debugproxy command. The debugproxy command takes in any option given, beyond the optional port, as a command to execute after it has started. If you choose this method, you do not need to execute step 4.
For UNIX, provide the following within an executable shell script called startjdb:
#!/bin/sh xterm -e jdb -password &1 &
Then, you can automatically start up the jdb debugger within the debugproxy command, as follows:
debugproxy -port 1638 startjdb
For all Windows NT environments, provide the following within a batch file called startjdb.bat:
start jdb -password %1
Then, you can automatically start up the jdb debugger within the debugproxy command, as follows:
debugproxy -port 1638 startjdb.bat
After you connect to the server (starting a session) and start a debug proxy, start a debug agent on the server that will connect to the proxy. When the DebugAgent starts, the DebugProxy displays a password to use when attaching the debugger in step 4.
|
Note: You must have the debug permission, JAVADEBUGPRIV, granted to your user to run a debug agent. See "Debugging Permissions" in the Oracle9i Java Developer's Guide for more information. |
Once a proxy is running, you can start a debug agent to connect to the proxy from SQL*Plus. You must specify the IP address or URL for a machine running a debug proxy, the port the proxy is waiting on, and a timeout in seconds. You start and stop the debug agent using methods specified within the DBMS_JAVA package.
SQL> call dbms_java.start_debugging('yourmachinename', 2286, 66);
There is no way to cause server-resident code to execute and break, that is, execute and remain indefinitely in a halted mode. Instead, when you start the DebugAgent, you must specify a timeout period for the DebugAgent to wait before terminating. The start call waits until the timeout expires or until the main thread is suspended and resumed before it completes. Calculate a timeout that includes enough time for your debugger to start up, but not so much as to delay your session if you cannot connect a debugger.
Stop the debug agent explicitly through the stop_debugging method.
SQL> call dbms_java.stop_debugging();
Once a debug agent starts, it runs until you stop it, the debugger disconnects, or the session ends.
Restart a stopped agent with any breakpoints still set with the restart_debugging method. The call waits until the timeout expires before it completes. You can also restart a running agent just to buy some seconds to suspend threads and set breakpoints.
SQL> call dbms_java.restart_debugging(66);
The DBMS_JAVA debug agent and proxy calls are published entry points to static methods that reside in oracle.aurora.debug.OracleAgent class. Start, stop, and restart the debug agent in Java code, using the class oracle.aurora.debug.OracleAgent directly, through the following methods:
public static void start(String host, int port, long timeout_seconds); public static void stop(); public static void restart(long timeout_seconds);
Start jdb and attach it to the debug proxy using the password provided by the DebugProxy when the DebugAgent connected to it. In order to preserve your timeout, suspend all threads through jdb, set your breakpoints, and then resume.
Each time a debug agent connects to a debug proxy, the debug proxy starts a thread to wait for connections from a debugger. The thread prints out the number, name, and address of the connecting agent, the port it is waiting on, and the port encoded as a password. Here, a specific port and password are provided for illustration only:
Agent Number: 1 Agent Name: servername Agent Address: eee.fff.jjj.kkk Agent Port: 2286 Agent Password: 3i65bn
Then, pass the password to a jdb-compatible debugger (JDK 1.1.6 or later):
jdb -password 3i65bn
The first thing you should do in the debugger is suspend all threads. Otherwise, your start_debugging call might time out and complete before you get your breakpoints set.
If your code writes to System.out or System.err, then you may also want to use the dbgtrace flag to jdb, which redirects these streams to the debugging console:
jdb -dbgtrace -password 3i65bn
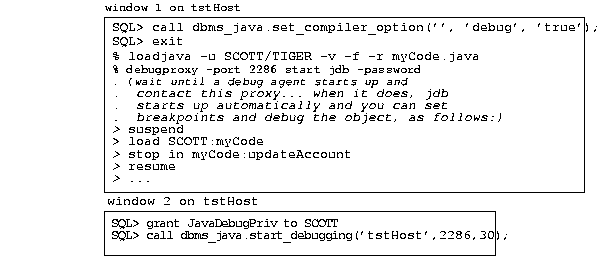
The following example shows how to debug an object that exists on the server. First, you need to start a proxy through the debugproxy command-line tool. This example starts up the proxy on the server, tstHost, and informs the debugproxy to start up the jdb debugger when contacted by the debug agent.
In another window, make sure that the debug agent user has the correct privileges and then start up the debug agent. Once the agent starts, the debugproxy starts up the jdb debugger and allows you to set your breakpoints. Since you have a specified amount of time before the agent times out, the first thing you should do is suspend all threads. Then, set all of your breakpoints before resuming. This suspends the timeout until you are ready to execute.
You might want to write Java code that executes in a certain way in the server and another way on the client. In general, Oracle does not recommend this. In fact, JDBC and SQLJ go to some trouble to enable you to write portable code that avoids this problem, even though the drivers used in the server and client are different.
If you must determine whether your code is executing in the server, use the System.getProperty method, as follows:
System.getProperty ("oracle.jserver.version")
The getProperty method returns the following:
String that represents the Oracle9i database release.System.out and System.err print to the current trace files. To redirect output to the SQL*Plus text buffer, use this workaround:
SQL> SET SERVEROUTPUT ON SQL> CALL dbms_java.set_output(2000);
The minimum (and default) buffer size is 2,000 bytes; the maximum size is 1,000,000 bytes. In the following example, the buffer size is increased to 5,000 bytes:
SQL> SET SERVEROUTPUT ON SIZE 5000 SQL> CALL dbms_java.set_output(5000);
Output prints at the end of the call.
For more information about SQL*Plus, see the SQL*Plus User's Guide and Reference.
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

