Sun S3L 4.0 Software Programming Guide S3L 4.0 Software Programming Guide
|
| Sun S3L 4.0 Software Programming Guide
|
| C H A P T E R 4 |
|
Multiple Instance |
Most Sun S3L routines support multiple instances. That is, they enable you to perform multiple independent operations on different data sets concurrently. The multiple instance discussions in this chapter are organized into the following sections:
To perform a Sun S3L operation on multiple independent data sets in parallel, you must embed the multiple independent instances of each operand or result argument in a parallel array.
The shape of the parallel array is defined by two kinds of axes:
FIGURE 4-1 illustrates this with an example of a matrix-vector multiplication operation in which four independent products are computed simultaneously. It shows how the destination and source vectors and the source matrix are organized with respect to the data and instance axes:
The instances within each variable are labeled 0 through 3.
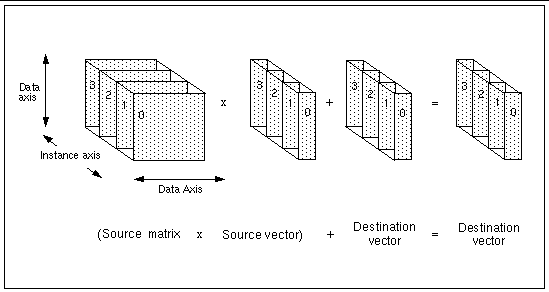
The logical unit on which the routine operates--sometimes called a cell--is defined by the data axes. The instance axes define the geometry of the frame in which the cells are embedded. The 3D parallel array shown in FIGURE 4-1 is a frame containing four 2-dimensional cells.
The product of the lengths of the instance axes is the total number of instances. The product of the lengths of the data axes is the size of the cell.
When you organize your data to form cells and frames for a multiple-instance operation, apply the following rules:
In most cases, however, performance is best when the cells (that is, all of the data axes) are local to a processing element. Instance axes are typically defined as nonlocal axes. Some man pages for Sun S3L routines contain specific information about optimizing layouts.
Specifying Single-Instance vs. Multiple-Instance Operations illustrates these rules being applied in a matrix-vector multiplication example.
|
Note - Most Sun S3L routines impose few or no restrictions on where the instance axes can occur in a parallel array. |
Sun S3L routines that support multiple instances have the same calling sequence for single-instance and multiple-instance operations. The methods for specifying single-instance and multiple-instance operations depend on which routine you are calling. The man pages for routines that are capable of multiple-instance operation contain specific information for their respective routines.
Example 1: Matrix-Vector Multiplication explains the differences between single- and multiple-instance operation for the matrix-vector-multiplication routine.
Example 2: Fast Fourier Transforms discusses use of multiple instances in FFTs.
When you call the matrix-vector-multiplication routine, S3L_mat_vec_mult, the dimensionality of the arguments you supply determines whether the routine performs a single-instance or multiple-instance operation. The F77 form of this Sun S3L function is:
S3L_mat_vec_mult(y, a, x, y_vector_axis, row_axis, col_axis, x_vector_axis, ier) |
|
Note - The S3L_mat_vec_mult routine requires you to specify which axes you are using as data axes for each matrix or vector argument. |
To perform a single-instance operation, specify each vector argument as a 1D parallel array and each matrix argument as a 2D parallel array. (Alternatively, you can declare these arguments to have more dimensions, but all instance axes must have length 1.)
For example, a single-instance operation in F77 can be performed by first defining the block-distributed arrays:
call S3L_mat_vec_mult(y, a, x, 1, 1, 2, 1, ier) |
Arrays x and y are 1D. The definitions of x_vector_axis = 1 and col_axis = 2 indicate that the product a(i, j) * x(j) will be evaluated for all values of j. These products will be summed over the first index of a (row_axis = 1), and the result added to the corresponding element in y. The equivalent code is
do i = 1, p sum = 0.0 do j = i, q sum = sum + a(i, j) * x(j) enddo enddo |
To perform a multiple-instance operation, embed the multiple instances of each vector argument in a parallel array of rank greater than 1, and embed the multiple instances of each matrix argument in a parallel array of rank greater than 2.
For example, the simplest multiple-instance matrix-vector multiplication involves the definition of one instance axis.
In this code, all three arrays contain an instance axis of length r. In addition, each instance axis is the rightmost axis in the array declaration. In other words, the order of data axes and instance axes is the same in all three arrays. These axis definitions produce arrays whose geometries are outlined in FIGURE 4-1. In the illustration, r = 4.
Multiplication using these arrays is then performed by:
call S3L_mat_vec_mult(y, a, x, 1, 1, 2, 1, ier) |
In analyzing the operations performed in this call, it is useful to define s0, the index along the instance axis. For a given value of s0, the following operations will be done:
These two operations will be performed for all 1 <= s0 <= r. In other words, the matrix-vector multiplication will be evaluated for all instances:
y(:, s0) * a(:, :, s0) * x(:, s0) |
The order in which these instances are evaluated depends on the layouts of the arrays. Since all arrays are block-distributed along all axes, it is possible for one set of processes to work on the first instance:
y(:, 1) = a(:, :, 1) * x(:, 1) |
while another set of processes evaluates the N-th instance at the same time--that is, in parallel:
y(:, N) = a(:, :, N) * x(:, N) |
The extent of parallelism depends on the details of the data layouts, particularly on the mapping of the data and instance axes to the underlying process grid axes. The highest degree of parallelism is achieved when all data axes are local and all instance axes are distributed.
The use of local data axes forces each cell (that is, all data axes) to reside entirely in just one process. The use of distributed instance axes spreads the collection of cells over the process grid, resulting in better load-balancing among processes.
Multiple-instance operations are usually most efficient when each cell (all of the data axes) resides on one process. Local distribution of data axes is illustrated below, using a Sun S3L array of rank 5, with the first two axes being the data axes and the other three being instance axes.
The data axes are defined to be local to a process. Each array has three block-distributed instance axes. Note that the order of instance axes is the same in all three arrays.
Multiplication using these arrays is then performed by
call S3L_mat_vec_mult(y, a, x, 1, 1, 2, 1, ier) |
The following is an analysis of the results of this multiple-instance matrix-vector operation. In this analysis, s0, s1, and s2 are used to denote the index along each of the three instance axes. For a given value of s0, the following operations will be done:
These two operations will be performed for all 1 <= s0 <= k, 1 <= s1 <= m, and
1 <= s2 <= n. In other words, the matrix-vector multiplication will be evaluated for all instances:
y(:, s0, s1, s2) = A(:, :, s0, s1, s2) * x(:, s0, s1, s2) |
However, unlike the previous example, the data axes in this case are local. This means that the evaluation of each instance does not involve any interprocess communication. Each process independently works on its own set of instances, using a purely local matrix-vector multiplication algorithm. These local algorithms are usually faster than their global counterparts, since no communication between processes is involved.
Source code for these operations is in the file mat_vec_mult.f. This can be found in the Sun S3L examples directory:
/opt/SUNWhpc/examples/s3l/dense_matrix_ops-f. |
|
Note - /opt/SUNWhpc is the default location for the examples directory. If you cannot find the directory, it may be that your site is not using the default path. |
When calling the detailed complex-to-complex FFT routine, S3L_fft_detailed, you can supply a multidimensional parallel array and specify whether you want to perform a forward transform, an inverse transform, or no transform along each axis. The axes that are transformed are the data axes and define the cell. The axes along which no transformation is performed are the instance axes.
|
Note - The simple FFT routine, S3L_fft, performs a transform along each axis of the supplied parallel array. Consequently, it does not support multiple instances. |
| Sun S3L 4.0 Software Programming Guide
| 817-0086-10 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.