Configuration Concepts
This section describes some failure scenarios and provides guidelines on how to configure the agent.
Individual Component Failure
In a replicated data cluster, you can prevent unnecessary SRDF failover or failback by configuring hosts attached to an array as part of the same system zone. VCS attempts to fail over applications within the same system zone before failing them over across system zones.
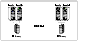
Click the thumbnail above to view full-sized image.
In this sample, hosta and hostb are in one system zone, and hostc and hostd are in another system zone. The SystemZones attribute enables you to create these zones. You can modify the SystemZones attribute using the following command:
# hagrp -modify grpname SystemZones hosta 0 hostb 0 hostc 1 hostd 1
The variable grpname represents the service group in the cluster.
This command creates two system zones: zone 0 with hosta and hostb, zone 1 with hostc and hostd.
Global clusters do not require system zones because failover occurs on a remote cluster if all local targets have been exhausted.
While running on R2 devices, SRDF does not synchronize data back to the R1 automatically. You must update out-of-synch tracks manually. Monitor the number of out-of-synch tracks by viewing the ResourceInfo attribute of an online SRDF resource. If the value is too high, update tracks to the R1 using the update action, which is defined as a supported action in the SRDF resource type.
All Host or All Application Failure
If all hosts on the R1 side are disabled or if the application cannot start successfully on any R1 hosts, but both arrays are operational, the service group fails over.
In replicated data cluster environments, the failover can be automatic, whereas in global cluster environments, failover requires user confirmation by default. In both environments, multiple device groups may fail over in parallel. VCS serializes symrdf commands to ensure that SRDF does not lock out a command while another command is running.
Set the OnlineTimeout and RestartLimit attributes for the SRDF resource to make sure that its entry points do not time out, or that they are automatically restarted if they time out.
 To set the OnlineTimeout attribute
To set the OnlineTimeout attribute
Use the following formula to calculate an appropriate value for the OnlineTimeout attribute:
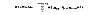
Click the thumbnail above to view full-sized image.
- ndevices represents the number of devices in a device group.
- dfailovertime represents the value of the DevFOTime attribute.
- ndevicegroups represents the total number of device groups managed by VCS that might fail over simultaneously.
- The additional epsilon is for the command instantiation overhead.
If the resulting value seems excessive, divide it by two for every increment in the value of the RestartLimit. However, the OnlineTimeout must be at least the time taken for the largest device group to fail over, otherwise the group will never be able to complete its operation, regardless of the value of RestartLimit.
Run the perl script /opt/VRTSvcs/bin/SRDF/sigma to get recommendations for VCS attribute values.
Run the script on a node where VCS is running and has the SRDF agent configured. Note that the sigma calculator adds 10 seconds to the value for each device group to compensate for the overhead of launching an symrdf command. Specify another value to the sigma script if you feel the instantiation takes shorter or longer.
The script assumes that all devices in the Symmetrix array are managed by VCS. Other operations outside of VCS that hold the array lock might delay the online operation unexpectedly.
Total Site Disaster
In a total site failure, all hosts and the Symmetrix array are completely disabled.
In a replicated data cluster, VCS detects site failure and total host failure by the loss of all LLT heartbeats.
In a global cluster, VCS detects site failure by the loss of both the ICMP and Symm heartbeats. In order not to confuse a site failure with an all-host failure, the AYARetryLimit for the Symm heartbeat must be shorter than the ICMP retry limit, so that the failure of the Symmetrix array is detected first.
A total disaster renders the devices on the surviving array in the PARTITIONED state. If the AutoTakeover attribute is set to its default value of 1, the online entry point runs the symrdf_rw command. If the attribute is set to 0, no takeover occurs and the online entry point times out and faults.
The online entry point detects whether any synchronization was in progress when the source array was lost. Since synchronization renders the target SRDF devices inconsistent until the synchronization completes, write-enabling the devices would be futile since the data stored on them is unusable. In this case, the agent does not enable the devices and instead times out and faults. In such a scenario, you must restore consistent data from a BCV or tape backup.
Replication Link Failure
SRDF detects link failures, monitors changed tracks on devices, and resynchronizes R2 devices if the R1 was active at the time of the link failure.
If the two arrays are healthy and the link fails and is restored, and if a failover is initiated while one or more devices are in the SYNCINPROG state, the SRDF agent waits for the synchronization to complete before running the symrdf failover command. If the agent times out before the synchronization completes, the resource faults.
If a failover is initiated due to a disaster at the R1 site, and if a synchronization was in progress, the R2 devices are rendered inconsistent and unusable. In this case, even if the AutoTakeover attribute of the agent is set to 1, the agent does not enable read-write access to the devices and instead it faults. You must restore consistent data to these devices, either from BCV or from a tape backup, and then enable read-write access to the devices manually before they can be used.
If the AutoTakeover attribute is set to 0, the agent does not attempt a symrdf rw_enable, but it times out and faults. If you write-enable the devices manually, the agent can come online after it is cleared.
Split-brain
Split-brain occurs when all heartbeat links between the R1 and R2 hosts are cut and each side mistakenly thinks the other side is down. To minimize the effects of split-brain, it is best if the cluster heartbeat links pass through similar physical infrastructure as the replication links so that if one breaks, so does the other.
In a replicated data cluster, VCS attempts to start the application assuming a total disaster because the R1 hosts and array are unreachable. Once the heartbeats are restored, VCS stops the applications on one side and restarts the VCS engine (HAD) to eliminate concurrency violation of the same group being online at two places simultaneously. You must resynchronize the volumes manually using the symrdf merge or symrdf restore commands.
In a global cluster, you can confirm the failure before failing over the service groups. You can check with the site administrator to identify the cause of the failure. If you do mistakenly fail over, the situation is similar to the replicated data cluster case; however, when the heartbeat is restored, VCS does not stop HAD at either site. VCS forces you to choose which group to take offline. You must resynchronize data manually.
If it is physically impossible to place the heartbeats alongside the replication links, there is a possibility that the cluster heartbeats are disabled, but the replication link is not. A failover transitions the original R2 volumes to R1 volumes and vice-versa. In this case, the application faults because its underlying volumes become write-disabled. VCS tries to fail the application over to another host, causing the same consequence in the reverse direction. This phenomenon continues until the group comes online on the final node. This situation can be avoided by setting up your infrastructure such that the loss of heartbeat links also means the loss of replication links.
Dynamic Swap
The agent supports the SRDF dynamic swap capability. If all devices are configured for dynamic swap, when a service group fails over between arrays, the agent performs a swap if both arrays are healthy. If one array is down, a unilateral read-write enable occurs. The agent fails over device groups that are not configured for dynamic swap using the symrdf failover command, which read-write enables the R2.
The agent checks the following criteria before determining if a swap will occur:
 All devices in the device group are configured as dynamic devices.
All devices in the device group are configured as dynamic devices.
Dynamic RDF is configured on the local Symmetrix array.
The SYMCLI version is 5.4 or above.
The microcode is level 5567 or above.
Dynamic swap does not affect the ability to perform fire drills.
|