I/O Fencing Operational Concepts
I/O fencing performs two important functions in a VCS cluster: membership arbitration and data protection.
Membership Arbitration
I/O fencing uses the fencing module and coordinator disks for membership control in a VCS cluster. With fencing, when a membership change occurs, members of any surviving cluster race for exclusive control of the coordinator disks to lock out any other potential cluster. This ensures that only one cluster is allowed to survive a membership arbitration in the event of an interconnect failure.
Let us take the example of a two-node cluster. If node 0 loses heartbeat from node 1, node 1 attempts to gain exclusive control of the coordinator disks. Node 0 makes no assumptions that node 1 is down, and races to gain control of the coordinator disks. Each node attempts to eject the opposite cluster from membership on the coordinator disks. The node that ejects the opposite member and gains control over a majority of the coordinator disks wins the race. The other node loses and must shut down.
The following illustration depicts the sequence in which these operations take place.
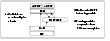
Click the thumbnail above to view full-sized image.
First, on node 0, LLT times out the heartbeat from node 1 (16 seconds by default), GAB is informed of a heartbeat failure. GAB then determines that a membership change is occurring. After the "GAB Stable Timeout" (5 seconds), GAB delivers the membership change to all registered clients. In this case, HAD and I/O fence.
HAD receives the membership change and requests the fencing module to arbitrate in case of a split-brain scenario and waits for the race to complete.
The registration function of SCSI-III PR handles races. During normal startup, every cluster member registers a unique key with the coordinator disks. To win a race for the coordinator disks, a node has to eject the registration key of the node in question from a majority of the coordinator disks.
If the I/O fencing module gains control of the coordinator disks, it informs HAD of success. If the fencing module is unsuccessful, the node panics and reboots.
Data Protection
Simple membership arbitration does not guarantee data protection. If a node is hung or suspended and comes back to life, it could cause data corruption before GAB and the fencing module determine the node was supposed to be dead. VCS takes care of this situation by providing full SCSI-III PR based data protection at the data disk level.
Failover Disk Groups
With fencing activated, the VCS DiskGroup agent imports shared storage using SCSI-III registration, and a WERO reservation. This means only the registered node can write. When taking over a disk group in a failover, the existing registration is ejected and the storage is imported.
Cluster Volume Manager Disk Groups
Shared disk groups managed using Cluster Volume Manager (CVM) are fenced by CVM during the import process. The CVM module on each node registers with data disks as they are imported. After registering with data disks, the master node sets a reservation on the disks in the WERO mode.
If a membership change occurs, the fencing module races to gain control over the coordinator disks. If successful, it informs the CVM module of the membership change. The CVM module then uses multiple kernel threads to eject departed members from all shared data drives in parallel. Once this operation complete, the fencing module passes the cluster reconfiguration information to higher software layers like the Cluster File System.
Membership Arbitration Operating Examples
This section describes membership arbitration scenarios in two-node and multi-node clusters.
Two-Node Scenario: Node Failure
In this scenario, node 1 fails.
Node 0 races to gain control over a majority of the coordinator disks by ejecting the key registered by node1 from each disk. The ejection takes place one by one, in the order of the coordinator disk's serial number.

Click the thumbnail above to view full-sized image.
When the I/O fencing module successfully completes the race for the coordinator disks, HAD can carry out recovery actions with assurance the node is down.
Two-Node Scenario: Split-brain Avoidance
In this scenario, the severed cluster interconnect poses a potential split-brain condition.
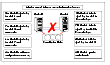
Click the thumbnail above to view full-sized image.
Because the fencing module operates identically on each system, both nodes assume the other is failed, but carry out fencing operations to verify the same.
The GAB module on each node determines the peer has failed due to loss of heartbeat and passes the membership change to the fencing module.
Each side races to gain control of the coordinator disks. Only a registered node can eject the registration of another node, so only one side successfully completes the preempt/abort command on each disk.
The fence driver is designed to delay if it loses a race for any coordinator disk. Since node 0 wins the first race, unless another failure occurs, it also wins the next two races.
The side that successfully ejects the peer from a majority of the coordinator disks wins. The fencing module on the winning side then passes the membership change up to VCS and other higher level packages registered with the fencing module. VCS can then take recovery actions. The losing side calls kernel panic and reboots.
Multi-Node Scenario: Fencing with Majority Cluster
In clusters with more than two nodes, the member with the lowest LLT ID races on behalf of other surviving members in its current membership.
Consider a four-node cluster, in which severed communications have separated node 3 from nodes 0, 1 and 2.
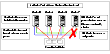
Click the thumbnail above to view full-sized image.
-
Node 3 gets cut off from the heartbeat network.
-
Nodes 0 and 3 must race on behalf of members of their respective "sub-clusters."
The fencing algorithm gives priority to the larger cluster, that is, the cluster representing at least 51% of members of the previous stable membership. Nodes 0, 1, and 2 represent the majority in this case. Node 0 is the lowest member (of 0, 1, and 2) and begins the race before node 3 does.
Node 3 delays its race by reading all keys on the coordinator disks a number of times before it can start racing for control.
-
Unless node 0 fails mid-race, it wins and gains control over the coordinator disks. The three-node cluster remains running and node 3 shuts down.
Multi-Node Scenario: Fencing with Equal Sub-Clusters
In this scenario, each side has half the nodes, that is, there are two minority clusters.
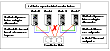
Click the thumbnail above to view full-sized image.
-
The interconnect failure leads to nodes 0 and 1 being separated from nodes 2 and 3. The cluster splits into two sub-clusters of the same size.
-
Both clusters wait for the same amount of time and begin racing. In this situation, either side can win control of the first coordinator disk. In this example, node 0 wins the first disk. Node 2 then delays by rereading the coordinator disks after losing the first race. Consequently, node 0 gains control over all three coordinator disks.
-
After winning the race, node 0 broadcast its success to its peers. On the losing side, node 2 panics because it has lost the race. The remaining members of the losing side time out waiting for a success message and panic.
Multi-Node Scenario: Complete-Split Cluster
In this scenario, a cluster is split into multiple one-node clusters due to interconnect failure or improper interconnect design.
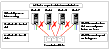
Click the thumbnail above to view full-sized image.
-
All nodes lose heartbeats to all other nodes. Each LLT declares heartbeat loss to GAB, and all GAB modules declare a membership change.
-
Each node is the lowest member of its own sub-cluster; each node races to acquire control over the coordinator disks.
-
Node 0 acquires control over the first disk. Other nodes lose the race for the first disk and reread the coordinator disks to pause before participating in the next race.
-
Node 0 acquires control over all three coordinator disks. Other nodes lose the race and panic.
 Note
In the example, node 0 wins the race, and all other nodes panic. If no node gets a majority of the coordinator disks, all nodes panic.
Note
In the example, node 0 wins the race, and all other nodes panic. If no node gets a majority of the coordinator disks, all nodes panic.
|