Troubleshooting Fenced Configurations
The following information provides describes network partitioning in a fenced environment. For a more comprehensive explanation of this topic, see the chapter on VCS communications in the VERITAS Cluster Server User's Guide.
Example of a Preexisting Network Partition (Split-Brain)
The scenario illustrated below shows a two-node cluster in which the severed cluster interconnect poses a potential split-brain condition.
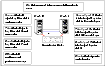
Click the thumbnail above to view full-sized image.
Because the fencing module operates identically on each system, both nodes assume the other is failed, and carry out fencing operations to confirm. The VCS GAB module on each node determines the peer has failed due to loss of heartbeats and passes the membership change to the fencing module.
Each side "races" to gain control of the coordinator disks. Only a registered node can eject the registration of another node, so only one side successfully completes the command on each disk.
The side that successfully ejects the peer from a majority of the coordinator disks wins. The fencing module on the winning side then passes the membership change up to VCS and other higher-level packages registered with the fencing module, allowing VCS to invoke recovery actions. The losing side forces a kernel panic and reboots.
Recovering from a Preexisting Network Partition (Split-Brain)
The fencing module vxfen prevents a node from starting up after a network partition and subsequent panic and reboot of a node.
Example Scenario I
Another scenario that could cause similar symptoms would be a two-node cluster with one node shut down for maintenance. During the outage, the private interconnect cables are disconnected.
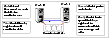
Click the thumbnail above to view full-sized image.
In this scenario:
 Node 0 wins a coordinator race following to a network failure.
Node 0 wins a coordinator race following to a network failure.
Node 1 panics and reboots.
Node 0 has keys registered on the coordinator disks. When node 1 boots up, it sees the Node 0 keys, but cannot see node 0 in the current GAB membership. It senses a potential preexisting split brain and causes the vxfen module to print an error message to the console. The vxfen module prevents fencing from starting, which, in turn, prevents VCS from coming online.
Suggested solution: Shut down Node 1, reconnect the cables, and restart Node 1.
Example Scenario II
Similar to scenario I, if private interconnect cables are disconnected in a two-node cluster, Node 1 is fenced out of the cluster, panics, and reboots. If before the private interconnect cables are fixed and Node 1 rejoins the cluster, Node 0 panics and reboots (or just reboots). No node can write to the data disks until the private networks are fixed. This is because GAB membership cannot be formed, therefore the cluster cannot be formed.
Suggested solution: Shut down both nodes, reconnect the cables, restart the nodes.
Example Scenario III
Similar to scenario II, if private interconnect cables are disconnected in a two-node cluster, Node 1 is fenced out of the cluster, panics, and reboots. If before the private interconnect cables are fixed and Node 1 rejoins the cluster, Node 0 panics due to hardware failure and cannot come back up, Node 1 cannot rejoin.
Suggested solution: Shut down Node 1, reconnect the cables, restart the node. You must then clear the registration of Node 0 from the coordinator disks.
-
On Node 1, type:
# /opt/VRTSvcs/vxfen/bin/vxfenclearpre
-
Restart the node.
|