| Oracle® Data Guard Concepts and Administration 10g Release 1 (10.1) Part Number B10823-01 |
|






|
View PDF |
| Oracle® Data Guard Concepts and Administration 10g Release 1 (10.1) Part Number B10823-01 |
|
|
View PDF |
A Data Guard configuration contains a primary database and up to nine associated standby databases. This chapter describes the following considerations for getting started with Data Guard:
A standby database is a transactionally consistent copy of an Oracle production database that is initially created from a backup copy of the primary database. Once the standby database is created and configured, Data Guard automatically maintains the standby database by transmitting primary database redo data to the standby system, where the redo data is applied to the standby database.
A standby database can be one of two types: a physical standby database or a logical standby database. If needed, either type of standby database can assume the role of the primary database and take over production processing. A Data Guard configuration can include physical standby databases, logical standby databases, or a combination of both types.
The following sections describe standby databases in more detail. See Oracle High Availability Architecture and Best Practices for information that can help you determine which type is most appropriate for your business.
A physical standby database is physically identical to the primary database, with on disk database structures that are identical to the primary database on a block-for-block basis. The database schema, including indexes, are identical.
Data Guard maintains a physical standby database by performing Redo Apply. When it is not performing recovery, a physical standby database can be open in read-only mode.
The physical standby database is maintained by applying redo data from the archived redo log files or directly from standby redo log files on the standby system using the Oracle recovery mechanism. The recovery operation applies changes block for block using the data block address. The database cannot be opened while redo is being applied.
The physical standby database can be open in read-only mode so that you can execute queries on the database. While opened in read-only mode, the standby database can continue to receive redo data, but application of the redo data from the log files is deferred until the database resumes Redo Apply.
Although the physical standby database cannot perform both Redo Apply and be opened in read-only mode at the same time, you can switch between them. For example, you can run a physical standby database to perform Redo Apply, then open it in read-only mode for applications to run reports, and then change it back to perform Redo Apply to apply any outstanding archived redo log files. You can repeat this cycle, alternating between Redo Apply and read-only, as necessary.
In either case, the physical standby database is available to perform backups. Furthermore, the physical standby database will continue to receive redo data even if archived redo log files or standby redo log files are not being applied at that moment.
A physical standby database provides the following benefits:
A physical standby database enables a robust and efficient disaster recovery and high availability solution. Easy-to-manage switchover and failover capabilities allow easy role reversals between primary and physical standby databases, minimizing the downtime of the primary database for planned and unplanned outages.
Using a physical standby database, Data Guard can ensure no data loss, even in the face of unforeseen disasters. A physical standby database supports all datatypes, and DDL and DML operations that the primary database can support. It also provides a safeguard against data corruptions and user errors. Storage level physical corruptions on the primary database do not propagate to the standby database. Similarly, logical corruptions or user errors that cause the primary database to be permanently damaged can be resolved. Finally, the redo data is validated when it is applied to the standby database.
Oracle Recovery Manager (RMAN) can use physical standby databases to off-load backups from the primary database saving valuable CPU and I/O cycles. The physical standby database can also be opened in read-only mode for reporting and queries.
The Redo Apply technology used by the physical standby database applies changes using low-level recovery mechanisms, which bypass all SQL level code layers; therefore, it is the most efficient mechanism for applying changes. This makes the Redo Apply technology an efficient mechanism to propagate changes among databases.
A logical standby database is initially created as an identical copy of the primary database, but it later can be altered to have a different structure. The logical standby database is updated by executing SQL statements. This allows users to access the standby database for queries and reporting at any time. Thus, the logical standby database can be used concurrently for data protection and reporting operations.
Data Guard automatically applies information from the archived redo log file or standby redo log file to the logical standby database by transforming the data in the log files into SQL statements and then executing the SQL statements on the logical standby database. Because the logical standby database is updated using SQL statements, it must remain open. Although the logical standby database is opened in read/write mode, its target tables for the regenerated SQL are available only for read-only operations. While those tables are being updated, they can be used simultaneously for other tasks such as reporting, summations, and queries. Moreover, these tasks can be optimized by creating additional indexes and materialized views on the maintained tables.
A logical standby database has some restrictions on datatypes, types of tables, and types of DDL and DML operations. Section 4.1.1 describes the unsupported datatypes and storage attributes for tables.
A logical standby database provides similar disaster recovery, high availability, and data protection benefits as a physical standby database. It also provides the following specialized benefits:
A logical standby database can be used for other business purposes in addition to disaster recovery requirements. It can host additional database schemas beyond the ones that are protected in a Data Guard configuration, and users can perform normal DDL or DML operations on those schemas any time. Because the logical standby tables that are protected by Data Guard can be stored in a different physical layout than on the primary database, additional indexes and materialized views can be created to improve query performance and suit specific business requirements.
A logical standby database can remain open at the same time its tables are updated from the primary database, and those tables are simultaneously available for read access. This makes a logical standby database an excellent choice to do queries, summations, and reporting activities, thereby off-loading the primary database from those tasks and saving valuable CPU and I/O cycles.
You can use the following interfaces to configure, implement, and manage a Data Guard configuration:
Enterprise Manager provides a GUI interface for the Data Guard broker that automates many of the tasks involved in creating, configuring, and monitoring a Data Guard environment. See Oracle Data Guard Broker and the Oracle Enterprise Manager online help for information about the GUI and its wizards.
Several SQL*Plus statements use the STANDBY keyword to specify operations on a standby database. Other SQL statements do not include standby-specific syntax, but they are useful for performing operations on a standby database. See Chapter 13 for a list of the relevant statements.
Several initialization parameters are used to define the Data Guard environment. See Chapter 11 for a list of the relevant initialization parameters.
The Data Guard broker command-line interface is an alternative to using the Enterprise Manager GUI. The command-line interface is useful if you want to use the broker to manage a Data Guard configuration from batch programs or scripts. See Oracle Data Guard Broker for complete information.
The following sections describe operational requirements for using Data Guard:
The following list describes hardware and operating system requirements for using Data Guard:
For example, this means a Data Guard configuration with a primary database on a 32-bit Solaris system must have a standby database that is configured on a 32-bit Solaris system. Similarly, a primary database on a 64-bit HP-UX system must be configured with a standby database on a 64-bit HP-UX system, and a primary database on a 32-bit Linux on Intel system must be configured with a standby database on a 32-bit Linux on Intel system, and so forth.
If the standby system is smaller than the primary system, you may have to restrict the work that can be done on the standby system after a switchover or failover. The standby system must have enough resources available to receive and apply all redo data from the primary database. The logical standby database requires additional resources to translate the redo data into SQL statements and then execute the SQL on the logical standby database.
The following list describes Oracle software requirements for using Data Guard:
Using Data Guard SQL Apply, you will be able to perform a rolling upgrade of the Oracle database software from patchset release 10.1.0.n to the next database 10.1.0.(n+1) patchset release. During a rolling upgrade, you can run different releases of the Oracle database (10.1.0.1 and higher) on the primary and logical standby databases while you upgrade them, one at a time. For complete information, see Section 9.2 and the ReadMe file for the applicable Oracle Database 10g patchset release.
FORCE LOGGING at the primary database before performing datafile backups for standby creation. Keep the database in FORCE LOGGING mode as long as the standby database is required.SYSDBA system privileges.The directory structure of the various standby databases is important because it determines the path names for the standby datafiles, archived redo log files, and standby redo log files. If possible, the datafiles, log files, and control files on the primary and standby systems should have the same names and path names and use Optimal Flexible Architecture (OFA) naming conventions. The archival directories on the standby database should also be identical between sites, including size and structure. This strategy allows other operations such as backups, switchovers, and failovers to execute the same set of steps, reducing the maintenance complexity.
Otherwise, you must set the filename conversion parameters (as shown in Table 2-1) or rename the datafile. Nevertheless, if you need to use a system with a different directory structure or place the standby and primary databases on the same system, you can do so with a minimum of extra administration.
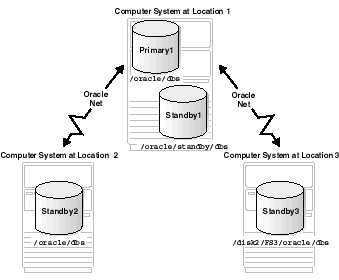
The three basic configuration options are illustrated in Figure 2-1. These include:
Standby1.
If you have a standby database on the same system as the primary database, you must use a different directory structure. Otherwise, the standby database attempts to overwrite the primary database files.
Standby2. This is the recommended method.Standby3.
|
Note: if any database in the Data Guard configuration uses ASM, OMF, or both, then every database in the configuration should use ASM, OMF, or both, respectively. See Chapter 10 for a scenario describing how to set up OMF in a Data Guard configuration. |
Text description of the illustration sbr81097.gif
Table 2-1 describes possible configurations of primary and standby databases and the consequences of each. In the table, note that the service name defaults to the global database name, which is a concatenation of the database name (DB_NAME) and domain name (DB_DOMAIN) parameters. If you do not explicitly specify unique service names when the primary and standby databases reside on the same system, the same default global database name will be in effect for both the primary and standby databases.
| Standby System | Directory Structure | Consequences |
|---|---|---|
|
Same as primary system |
Different than primary system (required) |
|
|
Separate system |
Same as primary system |
|
|
Separate system |
Different than primary system |
|
The most crucial structures for Data Guard recovery operations are online redo logs, archived redo logs, and standby redo logs. Redo data transmitted from the primary database is received by the remote file server (RFS) process on the standby system where the RFS process writes the redo data to archived log files or standby redo log files. Redo data can be applied either after the redo is written to the archived redo log file or standby redo log file, or, if real-time apply is enabled, directly from the standby redo log file as it is being filled.
This documentation assumes that you already understand the concepts behind online redo logs and archived redo logs. Section 2.5.1 supplements the basic concepts by providing information that is specific to Data Guard configurations. Section 2.5.2 provides detailed information about using standby redo log files.
See Oracle Database Administrator's Guide for more information about redo logs and archive logs, and Section 6.2.1 for information about real-time apply.
Both online redo logs and archived redo logs are required in a Data Guard environment:
Every instance of an Oracle primary database and logical standby database has an associated online redo log to protect the database in case of an instance failure. Physical standby databases do not have an associated online redo log, because physical standby databases are never opened for read/write I/O; changes are not made to the database and redo data is not generated.
An archived redo log is required because archiving is the method used to keep standby databases transactionally consistent with the primary database. Primary databases, and both physical and logical standby databases each have an archived redo log. Oracle databases are set up, by default, to run in ARCHIVELOG mode so that the archiver (ARCn) process automatically copies each filled online redo log file to one or more archived redo log files.
Both the size of the online redo log files and the frequency with which a log switch occurs can affect the generation of the archived redo log files at the primary site. The Oracle High Availability Architecture and Best Practices provides recommendations for log group sizing.
An Oracle database will attempt a checkpoint at each log switch. Therefore, if the size of the online redo log file is too small, frequent log switches lead to frequent checkpointing and negatively affect system performance on the standby database.
A standby redo log is similar in all ways to an online redo log, except that a standby redo log is used only when the database is running in the standby role to store redo data received from the primary database.
A standby redo log is required to implement:
Configuring standby redo log files is highly recommended on all standby databases in a Data Guard configuration, because they provide a number of advantages:
Section 5.6.2 describes how to configure standby redo log files.
|
 Copyright © 1999, 2003 Oracle Corporation All Rights Reserved. |
|

