| Oracle® OLAP Application Developer's Guide 10g Release 1 (10.1) Part Number B10333-02 |
|






|
View PDF |
| Oracle® OLAP Application Developer's Guide 10g Release 1 (10.1) Part Number B10333-02 |
|
|
View PDF |
Oracle OLAP provides data acquisition facilities so that you can create a standard form analytic workspace, or add data to an existing workspace, from sources other than a star or snowflake schema. This chapter introduces those facilities. It contains the following topics:
Oracle Warehouse Builder can transform a wide variety of data sources into a star schema and, from the star schema, into an analytic workspace. As an alternative method, you can create an analytic workspace containing empty standard form objects, and populate these objects directly from the data sources using the facilities of the OLAP DML.
Even if you have successfully built your analytic workspace using either Analytic Workspace Manager or Oracle Warehouse Builder, you may want to add measures from other sources, such as syndicated data or government business statistics. In that case, you can use the information provided in Chapter 8, " Exploring a Standard Form Analytic Workspace ", and Chapter 9, " Adding Measures to a Standard Form Analytic Workspace " to define and register the standard form workspace objects. Then you can use one of the methods introduced in this chapter to populate the objects.
This chapter shows how to use OLAP tools to generate a standard form analytic workspace, then how to populate it manually from various sources using the OLAP DML.
The OLAP DML has facilities to load data from these sources:
Flat files. The file reader commands load data from flat files, so that you can use data from spreadsheets, syndicated and government sources, or legacy database systems.
Relational tables. The OLAP DML SQL command enables you to issue most SQL commands from an analytic workspace. Using the SQL command, you can fetch data with appropriate data types from any relational table or view into an analytic workspace. OLAP tools, such as the DBMS_AWM package, use the SQL command to populate analytic workspaces.
EIF files. The IMPORT and EXPORT commands enable you to create standard form analytic workspaces from legacy Express databases. A conversion program is available for those containing Oracle Express Objects metadata. Refer to
The steps that you take to create a standard form analytic workspace from alternative sources is basically the same as from a star or snowflake schema. There are two primary differences:
Instead of loading your data into the star or snowflake schema of a data warehouse, you simply create the empty tables. These tables provide the basis for defining the OLAP Catalog metadata required by the DBMS_AWM package to create an analytic workspace. The data remains in its original form until it is loaded directly into an analytic workspace.
The DBMS_AWM package uses characteristics of the data in the initial load to make default choices such as dimension order and segment size. Since there is no data from which it can make appropriate choices, you must specify the correct values. Using the DBMS_AWM package directly provides you with the most control. However, you can still use Analytic Workspace Manager or Oracle Warehouse Builder if you wish, and modify the results where necessary before loading the data.
Take these steps to generate a standard form analytic workspace from flat files, relational tables, or an Express database with no Oracle Express Objects metadata. (If you are converting an Oracle Express Objects database, skip these instructions and go to Appendix B.)
Identify the dimensions, attributes, measures, and cubes for your data, and use this information to design a star schema.
You can use pencil and paper, a database design software package, or any other method that suites you.
Implement your design by creating the dimension tables and fact tables.
You can issue SQL CREATE TABLE statements directly in SQL*Plus, or use a graphical interface such as Oracle Enterprise Manager to create the tables. Note that you are creating the tables, but not populating them.
Create OLAP Catalog metadata for the star schema.
Use any of these methods for creating either CWM1 or CWM2 metadata: the OLAP Management tool in Oracle Enterprise Manager; the OLAP Bridge in Oracle Warehouse Builder; or the CWM2 PL/SQL package.
Create a standard form analytic workspace from the OLAP Catalog metadata.
Use any of these methods: the Create Analytic Workspace wizard in Analytic Workspace Manager; the OLAP Bridge in Oracle Warehouse Builder; or the DBMS_AWM PL/SQL package. Specify a full load, even though the tables do not contain data, so that all catalogs are populated correctly in the analytic workspace.
Review the analytic workspace and make any changes to the object definitions. In particular, look at the dimension order for composites and data variables, and set an appropriate segment size on the target variables.
Refer to "Case Study: Creating the GLOBALX Workspace From Alternative Sources" for examples of these types of changes.
Load data into the dimensions, relations, and variables of the standard form analytic workspace.
Use any of the methods described in this chapter.
Make any additional changes to the workspace metadata.
You now have a standard form analytic workspace, and you can use any of the tools for aggregation and deployment provided for standard form workspaces. However, you must refresh the data using whatever OLAP DML programs you created for that purpose.
You can use file reader OLAP DML commands to acquire data from external files in various formats: binary, packed decimal, or text. While you can use some of the file reader commands individually, it is best to place them in a program. You can thereby minimize mistakes in typing and test your commands on smaller sets of data. A program also enables you to perform operations in which several commands are used together to loop over many records in a file. Afterward, you can use the program to refresh your data.
Table 11-1 describes the OLAP DML file reader commands. Refer to the Oracle OLAP DML Reference for the complete syntax, usage notes, and examples of these commands and functions.
Table 11-1 OLAP DML File Reader Commands
| Command | Description |
|---|---|
FILECLOSE command |
Closes an open file. |
FILEERROR function |
Returns information about the first error that occurred when you are processing a record from an input file with the FILEREAD and FILEVIEW commands. |
FILEGET function |
Returns text from a file that has been opened for reading. |
FILENEXT function |
Makes a record available for processing by the FILEVIEW command. It returns YES when it is able to read a record and NO when it reaches the end of the file. |
FILEOPEN function |
Opens a file, assigns it a fileunit number (an arbitrary integer), and returns that number. |
FILEPUT command |
Writes data that is specified in a text expression to a file that is opened in WRITE or APPEND mode. |
FILEQUERY function |
Returns information about one or more files. |
FILEREAD command |
Reads records from an input file, processes the data, and stores the data in workspace dimensions, composites, relations, and variables, according to descriptions of the fields in the input record. |
FILESET command |
Sets the paging attributes of a specified fileunit |
FILEVIEW command |
Works in conjunction with the FILENEXT function to read one record at a time of an input file, process the data, and store the data in workspace dimensions and variables according to the descriptions of the fields. |
RECNO function |
Reports the current record number of a file opened for reading. |
While reading from a file, you can format the data from each field individually, and use DML functions to process the information before assigning it to a workspace object. Reading a file generally involves the following steps.
Open the data file.
Read data from the file one record or line at a time.
Process the data and assign it to one or more workspace objects.
Close the file.
The FILEREAD and FILEVIEW commands have the same attributes and can do the same processing on your data. However, they differ in important ways:
The FILEREAD command loops automatically over all records in the file and processes them automatically. Use FILEREAD when all records that you wish to read in the file are the same. FILEREAD is easier to use and faster than FILEVIEW.
Because FILEREAD is able to process most files, it is shown in the examples in this chapter.
The FILEVIEW command processes one record at a time. FILEVIEW is the more powerful of the two file-reading commands; it can process all of files that FILEREAD can, plus process different types of records.
Example 11-1 provides a template for a developing a file-reading program in the OLAP DML. Refer to "Fetching Dimensions Members From Tables" for strategies for reading dimension members.
Example 11-1 Template for Reading Flat Files
VARIABLE funit INTEGER "Define local variable for file handle
TRAP ON CLEANUP "Divert processing on error to CLEANUP label
funit = FILEOPEN('directory/datafile' READ) "Open the file
"Read the file with FILEREAD
FILEREAD funit
.
.
.
CLEANUP: "Cleanup label
IF funit NE na "Close the file
THEN FILECLOSE funit
The FILEREAD command maps fields to workspace objects. A source file can be structured with records in any of the following ways:
Ruled files contain data in columns, with fields defined by a starting position and a width.
Structured PRN files contain strings of text or numbers. A text field is enclosed in quotation marks. A number field can contain periods (.) in addition to numbers, but any other character, including spaces and commas, terminates the field.
CSV files (for Comma-Separated Values) use a special character, the delimiter, to separate the fields in a record.
The target for the data in an analytic workspace is either a dimension, a relation, or a variable. Dimensions can either be maintained by adding new members, or they can be used just to align incoming data with existing dimension members. In standard form analytic workspaces, a variable is typically an attribute or a measure.
The basic syntax of FILEREAD for mapping the data in ruled files is:
COLUMN n WIDTH n workspace_object
The following is an example of four records from a data file. From left to right, the columns are channels, products, customers, time periods, and units. The first column (channels) is 10 characters wide, and the other columns are 11 characters wide.
2 13 51 54 2
2 13 51 56 2
2 13 51 57 2
2 13 51 58 2
The following FILEREAD command reads the data from the last column into the UNITS_VARIABLE variable, aligning the values in the other four columns with existing dimension members. The RULED keyword is optional, since it is the default record format.
FILEREAD funit RULED - COLUMN 1 WIDTH 10 channel - COLUMN 11 WIDTH 11 product - COLUMN 22 WIDTH 11 customer - COLUMN 33 WIDTH 11 time - COLUMN 44 WIDTH 11 units_variable
The basic syntax in FILEREAD for mapping structured data is:
FIELD n workspace_object
The same data file shown previously in "Reading Ruled Files" can be read with the following command:
FILEREAD funit STRUCTURED - FIELD 1 channel - FIELD 2 product - FIELD 3 customer - FIELD 4 time - FIELD 5 units_variable
The basic syntax for reading a CSV file is the same as for structured PRN files:
FIELD n workspace_object
The following is an example of four records from a CSV file, in which a comma is the delimiter. The fields are the same as the previous data file shown in "Reading Ruled Files": channels, products, customers, time periods, and units.
2,13,51,54,2 2,13,51,56,2 2,13,51,57,2 2,13,51,58,2
This file can be read with the following command; the DELIMITER clause is optional in this case, because a comma is the default delimiter.
FILEREAD funit CSV DELIMITER ',' - FIELD 1 channel - FIELD 2 product - FIELD 3 customer - FIELD 4 time - FIELD 5 units_variable
Whenever you read data values into a variable, you must set the status of each dimension. Typically, the incoming records contain a field for each dimension; when a record is processed in the analytic workspace, the dimensions are temporarily limited to these values so that data targeted at a variable or relation is stored in the correct cell. However, if the records omit one or more dimensions, then you must set them manually before reading the file.
For example, if your file contains data only for the Direct Sales channel for August 2003, and thus does not have fields specifying the channel or time, then your program must limit the CHANNEL and TIME dimensions before reading the file. Otherwise, the data is aligned with the first member of those dimensions (All Channels and Jan-98).
Your data will load fastest if the variables in your analytic workspace are defined with fastest and slowest varying dimensions that match the order of records in the source data file. If you have control over the order of records in the source data file, then you can create the data file to match the variables in your analytic workspace. Otherwise, you may need to choose between optimizing for loads and optimizing for queries when defining the dimension order of variables in your analytic workspace.
For example, a data file might have records sorted in this order:
Lists all records for the first channel, then all records for the second channel, and so forth.
Lists all products for the first channel, then all products for the second channel, and so forth.
Lists all customers for the first product, then lists all customers for the second product, and so forth.
Lists all time periods for the first customer, then all time periods for the second customer, and so forth.
In a workspace variable definition, the order of the dimensions identifies the way the data is stored. The fastest-varying dimension is listed first, and the slowest-varying dimension is listed last.
For this sample file, the data load will proceed fastest if the target variable is defined with TIME as the fastest varying dimension and CHANNEL as the slowest varying dimension, so the dimensions are listed in this order: TIME PRODUCT CUSTOMER CHANNEL. With a composite dimension, the definition looks like this:
DEFINE UNITS_VARIABLE VARIABLE DECIMAL <TIME UNITS_CUBE_COMPOSITE <CUSTOMER PRODUCT CHANNEL>>
Having the TIME dimension as the fastest varying dimension outside the composite also provides good run-time performance for time-based analysis, because the time periods are clustered together. This is a best-case scenario, in which the workspace variables are optimized for queries, and the data file is sorted correctly for the fastest loads.
However, if you have a separate data file for each time period, then TIME becomes the slowest-varying dimension for the load. In this case, there is a conflict between the dimension order that optimizes queries, and the dimension order that optimizes data loads. You need to choose which dimension order is best under these circumstances.
If you have a small batch window in which to load data, you may need to optimize for the data load by defining variables with TIME as the last dimension, as shown here:
DEFINE UNITS_VARIABLE VARIABLE DECIMAL <UNITS_CUBE_COMPOSITE <CUSTOMER PRODUCT CHANNEL> TIME>
The records in a data file typically contain fields for dimension values that identify the cell in which the data values should be stored. When all of the dimension values in the file already exist in your analytic workspace, you can use the default attribute MATCH in the dimension field description. MATCH accepts only dimension values that already are in the analytic workspace.
When an incoming value does not match, the command signals an error. Your file reader program can handle the error by skipping the record and continuing processing, or by halting the processing and letting you check the validity of the data file. The test for whether the error is caused by a new dimension member or another type of error is based on the transient value of the ERRORNAME option when the error is signaled.
Example 11-2 provides a template for error handling that permits processing to continue when a dimension value in the data file does not match a dimension value in the analytic workspace.
When your data file contains all new, or a mixture of new and existing dimension values, you can add the new values and all the associated data to the analytic workspace by using the APPEND attribute in the field description, as shown here:
FILEREAD funit -
COLUMN n APPEND WIDTH n dimension
Example 11-2 Template for Skipping Records With New Dimension Members
VARIABLE funit INTEGER "Define local variable for file handle
TRAP ON oops "Divert processing on error to oops label
funit = FILEOPEN('directory/datafile' READ) "Open the file
next: "Resume processing label
FILEREAD funit "Read the file with FILEREAD
.
.
.
WHILE FILENEXT(funit) "Or read it with FILEVIEW
DO
FILEVIEW funit...
DOEND
FILECLOSE funit "Close the file
RETURN "End normal processing
oops: "Error label
IF funit NE na AND ERRORNAME NE 'ATTN'
THEN DO
TRAP ON oops
GOTO next "Resume processing at next label
DOEND
IF funit NE na "Close the file on error
THEN FILECLOSE funit
The FILEREAD command enables you to modify values as they are read into the analytic workspace.
To simply add characters before or after a value, use the LSET and RSET clauses. For example, if the incoming time periods are only the months (such as JAN, FEB, MAR), you can add the year before storing the values in the TIME dimension:
FILEREAD funit - COLUMN 1 WIDTH 15 RSET '-04' time
For other transformations, you can use the FILEVIEW command or any of the data manipulation functions of the OLAP DML. The object of these manipulations is the keyword VALUE, which represents the value of the current field. In this example, the incoming values are converted to upper case:
FILEREAD funit -
COLUMN 1 WIDTH 15 time = UPCASE(VALUE)
If you need to match existing dimension values and a simple transformation cannot create a match, then you can create a relation in the analytic workspace that correlates the two sets of values. Take these steps:
Create a new dimension for the incoming dimension values.
You can define the dimension in Analytic Workspace Manager or with a command like this in OLAP Worksheet:
DEFINE new_dimension DIMENSION TEXT
Read the dimension values from the file.
Create a relation between the two dimensions.
You can define the relation in Analytic Workspace Manager or with a command like this in OLAP Worksheet:
DEFINE relation RELATION dimension <new_dimension>
Read the data from the file, using the relation to align the data.
Use syntax like this:
FILEREAD funit CSV -
FIELD 1 dimension = relation(new_dimension VALUE)
For example, if your Product dimension uses SKUs (stock keeping units) as dimension members, and you want to add data that uses bar codes, then you create a dimension for the bar codes and a relation between the bar codes and the SKUs of the Product dimension. You can populate the relation from a file that correlates bar codes and SKUs.
|
See Also: Oracle OLAP DML Reference under the entries forFILEREAD, FILEVIEW, and DEFINE RELATION for the complete syntax, usage notes, and examples of these commands. |
You can embed SQL statements in OLAP DML programs using the OLAP DML SQL command.
SQL sql_statement
When formatting a SQL statement that is an argument to the OLAP DML, be sure to use single quotes (') wherever you need quotes. In the OLAP DML, a double quote (") indicates the beginning of a comment.
You can use almost any SQL statement that is supported by Oracle in the OLAP DML SQL command. You can use SELECT to copy data from relational tables into analytic workspace objects. You can use the INSERT command to copy data from analytic workspace objects into relational tables.
The following Oracle SQL extensions are also supported:
The FOR UPDATE clause in the SELECT statement of a cursor declaration, so that you can update or delete data associated with the cursor
The WHERE CURRENT OF cursor clause in UPDATE and DELETE statements for interactive modifications to a table
Stored procedures and triggers
COMMIT and ROLLBACK are ignored as arguments to the SQL command. To commit your changes, issue the OLAP DML UPDATE and COMMIT commands. You cannot roll back using the OLAP DML.
Most SQL commands are submitted directly to the SQL command processor; however, a small number are first processed in the OLAP DML, and their syntax may be slightly different from standard SQL. Refer to the Oracle OLAP DML Reference for further details.
Table 11-2 describes the OLAP DML commands that support embedded SQL.
Table 11-2 OLAP DML Commands for Embedded SQL
| Statement | Description |
|---|---|
SQL command |
Passes SQL commands to the database SQL command processor |
SQLBLOCKMAX option |
Controls the maximum number of records retrieved from a table at one time |
SQLCODE option |
Holds the value returned by the database after the most recently attempted SQL operation |
SQLERRM option |
Contains an error message when SQLCODE has a nonzero value |
SQLMESSAGES option |
Controls whether error messages are sent to the current output file |
Using the OLAP DML, you can populate a standard form analytic workspace from relational tables by taking the following steps:
Define the analytic workspace objects that will hold the relational table data.
Follow the steps listed in "How to Manually Create a Standard Form Analytic Workspace". Then browse the analytic workspace to identify the objects you need to populate.
Write an OLAP DML program for each dimension. Compile and run the programs.
Read the following instructions in "Fetching Data From Relational Tables".
Write an OLAP DML program for each cube. Compile and run the programs.
Read the instructions in "Fetching Measures From Tables".
There are several strategies for fetching dimension members. The best practice is to fetch just the dimension members first, and fetch their attributes as a separate step. For Time members, the best practice is to fetch one level at a time, making a separate pass through the source table for each level. This practice enables you to fetch the Time members in the correct order so that they do not need to be sorted afterward.
However, the simplest method, and the one shown here, populates dimension members at all levels, and all of the objects that support hierarchies, at the same time. Before using this method, be sure that SEGWIDTH is set correctly, as discussed in "Setting the Segment Size".
is a template that you can use for fetching dimensions in one pass. The program does the following:
Reads the level columns one at a time, with their attribute columns, beginning with the top level (or most aggregate) and concluding with the base level. The syntax supports one hierarchy; refer to Example 11-18 for the equivalent syntax in FILEREAD for handling multiple hierarchies.
Because the parent relation is being populated at the same time, the parents must be added to the workspace dimension before their children. Otherwise, an error will occur, because a relation only accepts as legitimate values the members of a particular dimension. This is not an issue if you load all dimension members first.
Populates a Boolean member_inhier variable manually. The n shown in the syntax is either a 1 (for yes) or a 0 (for no).
Populates the member_levelrel relation manually with the appropriate level name for the column. Level names must exactly match the members of the levellist dimension.
Populates the member_parentrel relation with the parent dimension member from the appropriate column.
Includes commands for handling errors, which are omitted from other examples so they are easier to read.
Example 11-3 Template for Fetching Dimension Members
SQLMESSAGES=YES " Display error messages on the screen
TRAP ON CLEANUP " Go to the CLEANUP label if an error occurs
SQL DECLARE cursor CURSOR FOR SELECT -
top_level, n, 'levelname', parent_level, attribute, attribute,...-
.
.
.
base_level, n, 'levelname', attribute, attribute,... -
FROM table -
WHERE where_clause
" Signal an error if the command failed
IF SQLCODE NE 0
THEN SIGNAL declerr 'Define cursor failed'
" Open the cursor
SQL OPEN cursor
IF SQLCODE NE 0
THEN SIGNAL openerr 'Open cursor failed'
" Fetch the data
SQL IMPORT cursor INTO -
:APPEND dimension, :inhier, :levelrel, :parentrel, :attribute, :attribute, ...
IF SQLCODE NE 0 AND SQLCODE NE 100
THEN SIGNAL geterr 'Fetch failed'
" Save these changes
UPDATE
COMMIT
CLEANUP:
SQL CLOSE cursor
SQL CLEANUP
When you fetch dimension members at all levels in a single pass through the source table, they are mixed together in the target workspace dimension. For most dimensions, the order does not affect processing, although you can sort the members by level if you wish.
However, it is very important for Time dimension members to be ordered chronologically within levels so that the Time dimension supports time series analysis. Functions such as LEAD, LAG, and MOVINGAVERAGE use the relative position of Time members in their calculations. For example, LAG returns the dimension member that is a specified number of values before the current member. If the time periods are not in chronological order, the returned value is meaningless.
Your analytic workspace will perform better if you load the dimensions in the correct order instead of sorting them afterward.
contains an OLAP DML program template for sorting the Time dimension. It does the following:
Defines a valueset in which to hold the sorted values.
Sorts the Time dimension by level first, then by end date within level.
Stores the sorted values in the valueset.
Reorders the Time dimension members.
Example 11-4 Template for Sorting the Time Dimension
IF NOT EXISTS('valueset')
THEN DEFINE valueset VALUESET time_dim
LIMIT time_dim TO ALL
"Sort levels in descending order and time periods in ascending order
SORT time_dim D time_dim_LEVELREL A time_dim_END_DATE
LIMIT valueset TO time_dim
MAINTAIN time_dim MOVE VALUES(valueset) FIRST
"Save these changes
UPDATE
COMMIT
To fetch data from relational tables, you must write a program that defines a SQL cursor with the selection of data that you want to fetch, then retrieves the data into the analytic workspace objects that you previously created.
is a template that you can use for fetching all of the measures for a particular cube. It does the following:
Identifies a key column with the members of each dimension. When the data is fetched into a variable, the dimensions are limited to the appropriate cell by these values.
Orders the source data to match the target variable.
The ORDER BY clause in the SELECT statement is the reverse of the dimension list for the variable. If a variable is dimensioned by <Product Geography Time> so that Product is the fastest varying and Time is the slowest, then the ORDER BY clause sorts the rows by Time, Geography, and Product. This ordering speeds the data load.
Requires that values in the key columns match existing members in the target workspace dimensions.
A required match prevents new dimension members from being created without their level, parentage, attributes, and so forth.
Example 11-5 Template for Fetching Measures
SQLMESSAGES=YES " Display error messages on the screen
TRAP ON CLEANUP " Go to the CLEANUP label if an error occurs
" Define a cursor for selecting data
SQL DECLARE cursor CURSOR FOR SELECT -
key1, key2, key3, keyn -
meas1, meas2, meas3, measn -
FROM table
ORDER BY slowest_dim, ..., fastest_dim
" Signal an error if the command failed
IF SQLCODE NE 0
THEN SIGNAL declerr 'Define cursor failed'
" Open the cursor
SQL OPEN cursor
IF SQLCODE NE 0
THEN SIGNAL openerr 'Open cursor failed'
" Fetch the data
SQL IMPORT cursor INTO :MATCH dim1, :MATCH dim2, -
:MATCH dim3, :MATCH dimn, -
:var1, :var2 :var3
IF SQLCODE NE 0 AND SQLCODE NE 100
THEN SIGNAL geterr 'Fetch failed'
" Save these changes
UPDATE
COMMIT
CLEANUP:
SQL CLOSE cursor " Close the cursor
SQL CLEANUP " Free resources
Some of the metadata objects in an analytic workspace can only be populated after loading the data. Since you are creating a standard form analytic workspace, you can use the same OLAP DML programs as the DBMS_AWM package. These programs are stored in an analytic workspace named AWCREATE, which is owned by SYS. You can access the programs by attaching the workspace with this OLAP DML command:
AW ATTACH sys.awcreate
This chapter describes two programs:
___POP.FMLYREL populates the member_gid variables and member_familyrel relations.
___ORDER.HIERARCHIES populates the default_order variables.
The program names have three initial underscores.
The ___POP.FMLYREL program populates the member_gid variable and member_familyrel variable for a dimension of a data cube. You must execute ___POP.FMLYREL for each dimension. Use this syntax to call ___POP.FMLYREL:
CALL ___POP.FMLYREL(aw, aw!dim, aw!dim_HIERLIST, aw!dim_LEVELLIST, aw!dim_LEVELREL, dim, aw!dim_PARENTREL, aw!dim_INHIER)
Where:
All arguments are text expressions, so you must enclose literal text in single quotes. Use all upper-case letters for the arguments.
For an example, see "Populating Additional Standard Form Metadata Objects".
The ORDR.HIERARCHIES program populates the default_order attribute of a data dimension. You must run it for each dimension of a data cube. Use this syntax to run ORDR.HIERARCHIES:
CALL ___ordr.hierarchies('aw!dim', 'aw!dim_HIERLIST', 'aw!dim_HIER_CREATEDBY', 'dim_PARENTREL', 'dim_ORDER', 'dim_INHIER')
Where:
All arguments are text expressions, so you must enclose literal text in single quotes. Use all upper-case letters for the arguments.
For an example, see "Populating Additional Standard Form Metadata Objects".
This example shows how to create an analytic workspace by acquiring data from relational tables and flat files. It uses Global data simply because you are already familiar with this data set; if you want to create an analytic workspace directly from the Global star schema, refer to Chapter 6.
These are the basic steps:
Create the GLOBALX user and a default tablespace.
Create a star schema in GLOBALX.
Create OLAP Catalog metadata for the GLOBALX star schema that defines all of the dimensions, levels, hierarchies, attributes, and measures.
Define the GLOBALX_AW user and default tablespace.
Create the GLOBALX standard form analytic workspace.
Modify the GLOBALX analytic workspace, such as redefining composites and setting the segment size.
Populate the Price cube from relational tables using the OLAP DML SQL command.
Populate the Units cube from a flat file using the OLAP DML File Reader commands.
Aggregate the data.
Enable the GLOBALX analytic workspace for use by the BI Beans.
Because Global data is already stored in the GLOBAL star schema, GLOBALX can simply mimic its design for the Price and Units cubes. The only difference is that while GLOBAL is populated with data, GLOBALX contains empty tables.
Take these steps to create the sample GLOBALX schema:
Create the GLOBALX user and a default tablespace. Sample scripts are shown in "SQL Scripts for Defining Users and Tablespaces".
Create the SQL scripts listed in "SQL Scripts for the GLOBALX Star Schema".
Log in to SQL*Plus or a similar SQL command processor as the GLOBALX user.
Execute the scripts using the SQL @ command.
After the scripts execute without errors, issue a SQL COMMIT statement.
The metadata for the GLOBALX star schema can be generated by any available method: the OLAP Management tools in Oracle Enterprise Manager, the OLAP Bridge in Oracle Warehouse Builder, or the CWM2 PL/SQL package. This example arbitrarily uses the CWM2 packages.
Take these steps to create OLAP Catalog metadata for the GLOBALX schema:
Create the SQL scripts listed in "SQL Scripts for OLAP Catalog Metadata".
Log in to SQL*Plus or a similar SQL command processor as the GLOBALX user.
Issue these SQL commands so that you can see the full report from the metadata validator, both on the screen and saved to a file:
SET LINESIZE 135 SET SERVEROUT ON SIZE 999999 EXECUTE cwm2_olap_manager.set_echo_on SPOOL filepath SET ECHO ON
The buffer for server output holds a maximum of 1,000,000 characters. If you are building a large application, you may need to control the size of the output with a combination of SET_ECHO_ON, SET_ECHO_OFF, BEGIN_LOG, and END_LOG commands.
Execute the CWM2 scripts using the SQL @ command.
After the scripts execute without errors, issue a SQL COMMIT statement.
Examine the metadata in Analytic Workspace Manager, as shown in Figure 11-1.
Open Analytic Workspace Manager and connect as the GLOBALX user.
In the OLAP Catalog view, expand the Cubes, GLOBALX, and Relational Cubes folders.
Figure 11-1 GLOBALX Metadata Displayed in Analytic Workspace Manager
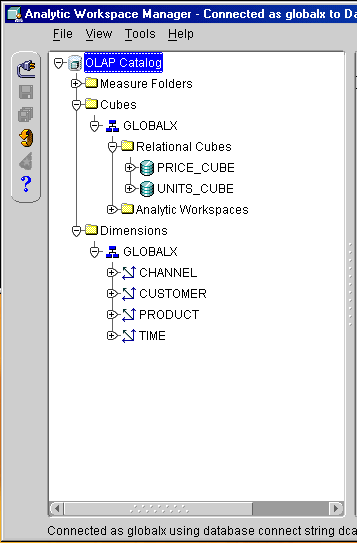
You can create the GLOBALX analytic workspace from the empty tables and OLAP Catalog metadata using any of the available methods: The Create Analytic Workspace wizard in Analytic Workspace Manager, the OLAP bridge in Oracle Warehouse Builder, or the DBMS_AWM PL/SQL procedures. This example uses the wizard to generate a script containing calls to DBMS_AWM, then modifies the script.
Take these steps to create the GLOBALX analytic workspace.
Create the GLOBALX_AW user with access rights to the GLOBALX tables and tablespaces, using a script like the one in "SQL Scripts for Defining Users and Tablespaces".
Open Analytic Workspace Manager and log in to the database as the GLOBALX_AW user.
From the Tools menu, choose Create Analytic Workspace Using Wizard.
Make these choices in the wizard:
Specify Analytic Workspace page: Type GLOBALX as the workspace name, and select GLOBALX_AW as the schema.
Select Cubes page: Select all cubes in the GLOBALX relational schema.
Choose Data Loading Options page: Select Build analytic workspace and load dimensions and facts. Clear the Generate unique keys box.
There is no data in the tables to load; however, this choice populates more catalogs in the analytic workspace than the other choices. The lack of data does not cause the build to fail.
Choose Advanced Storage and Naming Options page: Select Display the pages for setting the advanced storage options. Clear the Prefix measure names with cube names box.
Because no data is available, the tools cannot determine the correct order of the dimensions, nor an appropriate segment size. You must provide this information or the analytic workspace will run slower than it should.
Create Composite Dimension and following pages: Create a composite for the Units Cube named UNITS_CUBE_COMPOSITE with the dimensions in this order: CUSTOMER PRODUCT CHANNEL. Omit TIME from the composite.
Specify Segment Width and Dimension Order page: For the Units Cube, specify the dimensions like this.
TIME 85 <CUSTOMER PRODUCT CHANNEL> 1000000
Save the new analytic workspace.
Open the GLOBALX analytic workspace in OLAP Worksheet, and make the following modifications:
Delete and redefine UNIT_COST_VARIABLE and UNIT_PRICE_VARIABLE so they are dimensioned by <TIME PRODUCT>.
These 80% dense, two-dimensional measures will perform better without a composite. Refer to "Examining Sparsity Characteristics for GLOBAL" for a discussion of composite definitions. Follow the instructions in "Manually Changing Object Definitions".
Delete PRICE_CUBE_COMPOSITE.
Set the segment size on either one of the variables with a command like this:
CHGDFN unit_price_variable SEGWIDTH 85 50
These settings reserve contiguous disk space for 85 time periods and 50 products. A single command changes the segment size on all measures in the same cube.
Set the segment size on the dimension attributes with the following commands:
CHGDFN time_end_date SEGWIDTH 85 1 CHGDFN time_long_description SEGWIDTH 85 1 1 CHGDFN customer_long_description SEGWIDTH 80 2 1 CHGDFN product_long_description SEGWIDTH 50 1 1 CHGDFN channel_long_description SEGWIDTH 3 1 1
Save these changes by issuing UPDATE and COMMIT commands.
The Price cube has two measures, UNIT_COST and UNIT_PRICE, with two dimensions, PRODUCT and TIME. In this example, the data is loaded manually from the GLOBAL star schema. However, it could be loaded from any form of relational tables using the method described here.
Take these steps to populate the Price cube in the GLOBALX analytic workspace:
Open Analytic Workspace Manager and connect to the database as the GLOBALX_AW user.
In the Object View, open the GLOBALX analytic workspace in read/write mode.
Create the OLAP DML programs for fetching the PRODUCT and TIME dimension members.
You can create and compile programs in the Object View or in OLAP Worksheet. You can execute programs, and view the contents of the objects they populated, only in OLAP Worksheet.
Open OLAP Worksheet and execute the programs using the CALL command.
CALL program_name
After the programs run without error, check the contents of the target workspace objects to verify that they are populated correctly.
Issue UPDATE and COMMIT commands to save the loaded data.
Create and execute a data load program for the Price cube.
After that program runs without error, check the data in the target variables
Issue UPDATE and COMMIT commands to save the loaded data.
The GETPROD program shown in Example 11-7 fetches data into the PRODUCT dimension, the member_parentrel relation and the long_description variable. Note that parent values must be added to the PRODUCT dimension before their children, otherwise an error will occur in populating the parent relation. Thus the SELECT statement lists the level columns from the highest level of aggregation to the lowest.
The member_inhier Boolean variable is populated with values of 1 for true and 0 for false. The member_levelrel relation is also populated with text values that match the values of the levellist dimension.
Define the example program, then execute it with this command:
CALL getprod
Example 11-7 OLAP DML Program for Loading Products From GLOBAL.PRODUCT_DIM
DEFINE GETPROD PROGRAM
PROGRAM
TRAP ON CLEANUP
" Define cursor c1
SQL DECLARE c1 CURSOR FOR SELECT -
total_product_id, 1, 'TOTAL_PRODUCT', total_product_dsc, -
class_id, 1, 'CLASS', total_product_id, class_dsc, -
family_id, 1, 'FAMILY', class_id, family_dsc, -
item_id, 1, 'ITEM', family_id, item_dsc, item_package_id -
FROM global.product_dim
" Open the cursor
SQL OPEN c1
" Fetch the data
SQL FETCH c1 LOOP INTO -
:APPEND product, :product_inhier, :product_levelrel, :product_long_description, -
:APPEND product, :product_inhier, :product_levelrel, :product_parentrel, -
:product_long_description, -
:APPEND product, :product_inhier, :product_levelrel, :product_parentrel,-
:product_long_description, -
:APPEND product, :product_inhier, :product_levelrel, :product_parentrel, -
:product_long_description, :product_package
" Save these changes
UPDATE
COMMIT
CLEANUP:
SQL CLOSE c1
SQL CLEANUP
END
Example 11-8 shows a selection of the data to verify that the load was successful.
Example 11-8 Viewing the PRODUCT Dimension and Attributes
LIMIT product TO product_levelrel EQ 'ITEM'
LIMIT product KEEP FIRST 2
LIMIT product ADD ANCESTORS USING product_parentrel
REPORT W 8 DOWN product W 16 <product_long_description product_levelrel>
W 10 <product_parentrel product_inhier>
ALL_LANGUAGES: AMERICAN_AMERICA
-------------------PRODUCT_HIERLIST--------------------
--------------------PRODUCT_ROLLUP---------------------
PRODUCT_LONG_DES PRODUCT_PA PRODUCT_IN
PRODUCT CRIPTION PRODUCT_LEVELREL RENTREL HIER
-------- ---------------- ---------------- ---------- ----------
13 Envoy Standard ITEM 4 yes
14 Envoy Executive ITEM 4 yes
4 Portable PCs FAMILY 2 yes
2 Hardware CLASS 1 yes
1 Total Product TOTAL_PRODUCT NA yes
The program to fetch TIME members, shown in Example 11-9, is very similar to the previous program for fetching PRODUCT members. It differs only in the addition of time span and end date attributes.
However, TIME members must be sorted chronologically within levels in order to support time series analysis functions. Each row contains dimension members at every level, so the TIME dimension is populated with the levels completely mixed. Example 11-10 shows a program that sorts the TIME dimension. It uses the SORT command to order the current, temporary status of the TIME dimension, saves this order in a valueset, then loops over the valueset with the MAINTAIN command to reorder the values permanently.
Define the example programs, then execute them with these commands:
CALL gettime CALL timesort
Example 11-9 OLAP DML Program for Loading Time From GLOBAL.TIME_DIM
DEFINE GETTIME PROGRAM
PROGRAM
TRAP ON CLEANUP
SQL DECLARE c1 CURSOR FOR SELECT -
year_id, 1, 'YEAR', year_dsc, year_timespan, year_end_date, -
quarter_id, 1, 'QUARTER', year_id, quarter_dsc, quarter_timespan, quarter_end_date, -
month_id, 1, 'MONTH', quarter_id, month_dsc, month_timespan, month_end_date -
FROM global.time_dim -
ORDER BY month_end_date
" Open the cursor
SQL OPEN c1
" Fetch the data
SQL FETCH c1 LOOP INTO -
:APPEND time, :time_inhier, :time_levelrel, :time_long_description, -
:time_time_span, :time_end_date,-
:APPEND time, :time_inhier, :time_levelrel, :time_parentrel, -
:time_long_description, :time_time_span, :time_end_date,-
:APPEND time, :time_inhier, :time_levelrel, :time_parentrel, -
:time_long_description, :time_time_span, :time_end_date
" Save these changes
UPDATE
COMMIT
CLEANUP:
SQL CLOSE c1
SQL CLEANUP
END
Example 11-10 OLAP DML Program for Sorting TIME Dimension Members
DEFINE TIMESORT PROGRAM
PROGRAM
" Create a valueset to hold the sorted values
IF NOT EXISTS('timeset')
THEN DEFINE timeset VALUESET time
LIMIT time TO ALL
" Sort by descending levels and ascending end-dates
SORT time D time_LEVELREL A time_end_date
" Save sorted values in the valueset
LIMIT timeset TO time
" Reorder the dimension members
MAINTAIN time MOVE VALUES(timeset) FIRST
END
The TIME dimension has too many members to list in its entirety, but selecting members by ancestry (as shown for PRODUCT) temporarily reorders the dimension. The results will show whether the objects were populated correctly, but not necessarily whether the members are sorted correctly. Example 11-11 uses LIMIT commands that do not change the original order. The report shows the correct sort order.
Example 11-11 Viewing the TIME Dimension and Attributes
LIMIT time TO FIRST 10
LIMIT time ADD LAST 3
REPORT W 5 DOWN time W 8 <time_long_description time_parentrel time_levelrel time_inhier time_end_date time_time_span>
ALL_LANGUAGES: AMERICAN_AMERICA
--------------------TIME_HIERLIST--------------------
----------------------CALENDAR-----------------------
TIME_LON
G_DESCRI TIME_PAR TIME_LEV TIME_INH TIME_END TIME_TIM
TIME PTION ENTREL ELREL IER _DATE E_SPAN
----- -------- -------- -------- -------- -------- --------
1 1998 NA YEAR yes 31DEC98 365.00
2 1999 NA YEAR yes 31DEC99 365.00
3 2000 NA YEAR yes 31DEC00 366.00
4 2001 NA YEAR yes 31DEC01 365.00
85 2002 NA YEAR yes 31DEC02 365.00
102 2003 NA YEAR yes 31DEC03 365.00
119 2004 NA YEAR yes 31DEC04 366.00
5 Q1-98 1 QUARTER yes 31MAR98 90.00
6 Q2-98 1 QUARTER yes 30JUN98 91.00
7 Q3-98 1 QUARTER yes 30SEP98 92.00
106 Apr-04 116 MONTH yes 30APR04 30.00
107 May-04 116 MONTH yes 31MAY04 31.00
108 Jun-04 116 MONTH yes 30JUN04 30.00
Example 11-12 shows the program for fetching data into UNIT_PRICE_VARIABLE and UNIT_COST_VARIABLE. Note that the data must be loaded into the variables, not into the measuredef formulas, which have the same names as the logical measures. These are the definitions for these variables:
DEFINE UNIT_PRICE_VARIABLE VARIABLE DECIMAL <TIME PRODUCT> LD IMPLEMENTATION Variable for UNIT_PRICE Measure DEFINE UNIT_COST_VARIABLE VARIABLE DECIMAL <TIME PRODUCT> LD IMPLEMENTATION Variable for UNIT_COST Measure
The ORDER BY clause in the DECLARE CURSOR SELECT statement sorts the rows so that PRODUCT (ITEM_ID) is the slower varying dimension and TIME (MONTH_ID) is the faster varying dimension. This organization corresponds to the order in which the values are stored in the workspace variables, as shown by their definitions. This sort order enables the data to be loaded as quickly as possible.
All of the dimension members must already exist in the analytic workspace. If a value is found without a match among the dimension members, then the program fails with an error.
Define the example program, then execute it with this command:
CALL getpricecube
Example 11-12 OLAP DML Program to Load the PRICE Cube From PRICE_AND_COST_HISTORY_FACT
DEFINE GETPRICECUBE PROGRAM
PROGRAM
" Define a cursor for selecting data
SQL DECLARE c1 CURSOR FOR SELECT -
item_id, month_id, unit_price, unit_cost -
FROM global.price_and_cost_history_fact -
ORDER BY item_id, month_id
" Open the cursor
SQL OPEN c1
" Fetch the data
SQL FETCH c1 LOOP INTO :MATCH product, :MATCH time, -
:unit_price_variable, :unit_cost_variable
" Save these changes
UPDATE
COMMIT
SQL CLOSE c1 " Close the cursor
SQL CLEANUP
END
Unlike most measures, those from the Price cube are dense so that it is easy to check the data. The LIMIT commands in Example 11-13 select members at all levels of the PRODUCT and TIME hierarchies. There is only data at the lowest levels, so the other levels are calculated on demand. Notice that the measuredef formulas are shown, not their underlying variables.
To make a quick check for any values in a variable, use the ANY function:
SHOW ANY(variable NE NA)
For example:
SHOW ANY(unit_price_variable NE NA)
A return value of YES indicates that at least one cell has data; a value of NO indicates that all cells are empty.
Example 11-13 Validating the PRICE_CUBE Data Load
LIMIT time TO '44' '45'
LIMIT time ADD ANCESTORS USING time_parentrel
LIMIT product TO '13'
LIMIT product ADD ANCESTORS USING product_parentrel
REPORT unit_price unit_cost
----------------------------------------PRODUCT----------------------------------------
---------13---------- ----------4---------- ----------2---------- ----------1----------
TIME UNIT_PRICE UNIT_COST UNIT_PRICE UNIT_COST UNIT_PRICE UNIT_COST UNIT_PRICE UNIT_COST
-------------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
44 3,008.91 2,862.51 9,483.71 8,944.35 19,163.02 18,071.18 19,960.72 18,714.88
45 3,142.99 2,926.79 9,590.01 9,024.35 18,969.89 17,924.55 19,735.20 18,542.48
13 9,152.01 8,655.17 28,452.92 26,883.70 57,229.23 53,982.32 59,577.63 55,873.16
3 34,314.40 32,681.09 111,333.24 105,481.00 224,713.71 211,680.12 234,516.47 219,574.10
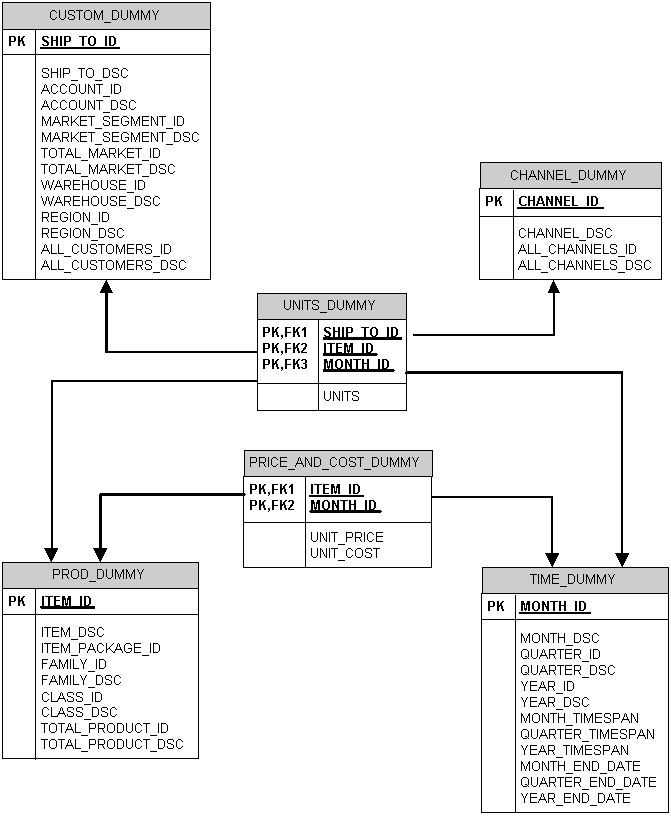
The Units cube has one measure, UNITS, and four dimensions, TIME, CUSTOMER, PRODUCT, and CHANNEL. The TIME and PRODUCT dimensions have already been added to the analytic workspace in "Fetching the Price Cube From Relational Tables", so unless additional dimension members are contained in the flat files, these two dimensions do not need to be maintained. However, the CUSTOMER and CHANNEL dimensions must be fully populated before loading the UNITS measure.
This example loads data from three flat files:
CHANNEL.DAT contains all CHANNEL dimension members and their attributes. It is equivalent to the CHANNEL_DIM dimension table in the GLOBAL star schema, described in Chapter 3.
CUSTOMER.DAT contains all CUSTOMER dimension members and their attributes. It is equivalent to the CUSTOMER_DIM dimension table in the GLOBAL star schema, described in Chapter 3.
UNITS.DAT contains the base-level data for the UNITS measure. It is equivalent to the UNITS_HISTORY_FACT fact table in the GLOBAL star schema, described in Chapter 3.
The basic process for loading from flat files is the same as loading from relational tables, as described earlier in "Fetching the Price Cube From Relational Tables". The difference is only in the OLAP DML programs.
CHANNELS.DAT is a comma-delimited file as shown in Example 11-14. It has fields that correspond to the columns of the CHANNELS_DIM dimension table in the Global star schema:
With these fields, you can populate the CHANNEL dimension, the CHANNEL_LONG_DESCRIPTION attribute, the CHANNEL_PARENTREL relation, and the CHANNEL_LEVELREL relation. In addition, you can populate CHANNEL_INHIER and CHANNEL_LEVELREL with literal text during the data load.
Example 11-14 CHANNELS.DAT Flat File
2,Direct Sales,1,All Channels 3,Catalog,1,All Channels 4,Internet,1,All Channels
Loading the dimension values is straightforward except for the All Channels dimension member (1), which appears only in the third field. It must be added to the CHANNEL dimension before it can be used as the parent of other dimension members in CHANNEL_PARENTREL. For this reason, the third field is read first as a dimension member that has no parent, and again as a parent value. Example 11-15 shows the program for loading the data.
Define the sample program, then execute it with this command:
CALL read_channels
Example 11-15 OLAP DML Program for Loading Channels from CHANNELS.DAT
DEFINE READ_CHANNELS PROGRAM
PROGRAM
VARIABLE funit INTEGER "Define local variable for file handle
TRAP ON CLEANUP "Divert processing on error to CLEANUP label
funit = FILEOPEN('gx/channels.dat' READ) "Open the file
FILEREAD funit CSV -
FIELD 3 APPEND channel channel_inhier=yes channel_levelrel='ALL_CHANNELS' -
FIELD 4 channel_long_description -
FIELD 1 APPEND channel channel_inhier=YES channel_levelrel='CHANNEL' -
FIELD 2 channel_long_description -
FIELD 3 channel_parentrel
CLEANUP:
IF funit NE na
THEN FILECLOSE funit
END
CHANNEL is a very small dimension with only four members, so you can review the results of the load without selecting a sample. shows the results of the load.
Example 11-16 Viewing the CHANNEL Dimension and Attributes
REPORT W 8 DOWN channel W 12 <channel_long_description channel_parentrel channel_levelrel channel_inhier>
ALL_LANGUAGES: AMERICAN_AMERICA
-----------------CHANNEL_HIERLIST------------------
------------------CHANNEL_ROLLUP-------------------
CHANNEL_LONG CHANNEL_PARE CHANNEL_LEVE CHANNEL_INHI
CHANNEL _DESCRIPTION NTREL LREL ER
-------- ------------ ------------ ------------ ------------
1 All Channels NA ALL_CHANNELS yes
2 Direct Sales 1 CHANNEL yes
3 Catalog 1 CHANNEL yes
4 Internet 1 CHANNEL yes
CUSTOMERS.DAT is a structured file, so that text columns are enclosed in double quotes. It has fields that correspond to the columns in the CUSTOMERS_DIM dimension table in the GLOBAL star schema:
Example 11-17 shows the first six fields of a few sample records. It contains the same types of information as CHANNELS.DAT, so that all of the equivalent workspace objects are populated. The one significant difference is that the data supports two hierarchies.
Example 11-17 CUSTOMERS.DAT Flat File
49 "Bavarian Indust, GmbH Rome" 22 "Bavarian Industries" 5 "Manufacturing" ...
50 "Bavarian Indust, GmbH London" 22 "Bavarian Industries" 5 "Manufacturing" ...
55 "CiCi Douglas Chattanooga" 24 "CiCi Douglas" 5 "Manufacturing" ...
.
.
.
The load program for CUSTOMERS.DAT, like the one for CHANNELS.DAT, must read parent dimension members before their children. Field 13 contains the most aggregate level, All Customers ID, so it is loaded first. The program shown in Example 11-18 loads the parent members for the SHIPMENTS_ROLLUP hierarchy first, then the parent members for the MARKET_ROLLUP hierarchy. The base level, SHIP_TO, belongs to both hierarchies.
Define the example program, then execute it with this command:
CALL read_customers
Example 11-18 OLAP DML Program for Reading CUSTOMERS.DAT
DEFINE READ_CUSTOMERS PROGRAM
PROGRAM
VARIABLE funit INTEGER "Define local variable for file handle
TRAP ON CLEANUP "Divert processing on error to CLEANUP label
funit = FILEOPEN('gx/customers.dat' READ) "Open the file
FILEREAD funit STRUCTURED -
FIELD 13 APPEND customer -
customer_inhier(customer_hierlist 'SHIPMENTS_ROLLUP')=yes -
customer_levelrel='ALL_CUSTOMERS' -
FIELD 14 customer_long_description(customer_hierlist 'SHIPMENTS_ROLLUP') -
FIELD 11 APPEND customer -
customer_inhier(customer_hierlist 'SHIPMENTS_ROLLUP')=yes -
customer_levelrel='REGION' -
FIELD 12 customer_long_description(customer_hierlist 'SHIPMENTS_ROLLUP') -
FIELD 13 customer_parentrel(customer_hierlist 'SHIPMENTS_ROLLUP') -
FIELD 9 APPEND customer -
customer_inhier(customer_hierlist 'SHIPMENTS_ROLLUP')=yes -
customer_levelrel='WAREHOUSE' -
FIELD 10 customer_long_description(customer_hierlist 'SHIPMENTS_ROLLUP') -
FIELD 11 customer_parentrel(customer_hierlist 'SHIPMENTS_ROLLUP') -
FIELD 7 APPEND customer -
customer_inhier(customer_hierlist 'MARKET_ROLLUP')=yes -
customer_levelrel='TOTAL_MARKET' -
FIELD 8 customer_long_description(customer_hierlist 'MARKET_ROLLUP') -
FIELD 9 customer_parentrel(customer_hierlist 'MARKET_ROLLUP') -
FIELD 5 APPEND customer -
customer_inhier(customer_hierlist 'MARKET_ROLLUP')=yes -
customer_levelrel='MARKET_SEGMENT' -
FIELD 6 customer_long_description(customer_hierlist 'MARKET_ROLLUP') -
FIELD 7 customer_parentrel(customer_hierlist 'MARKET_ROLLUP') -
FIELD 3 APPEND customer -
customer_inhier(customer_hierlist 'MARKET_ROLLUP')=yes -
customer_levelrel='ACCOUNT' -
FIELD 4 customer_long_description(customer_hierlist 'MARKET_ROLLUP') -
FIELD 5 customer_parentrel(customer_hierlist 'MARKET_ROLLUP') -
FIELD 1 APPEND customer -
customer_inhier(customer_hierlist 'SHIPMENTS_ROLLUP')=yes -
customer_inhier(customer_hierlist 'MARKET_ROLLUP')=yes -
customer_levelrel='SHIP_TO' -
FIELD 2 customer_long_description(customer_hierlist 'SHIPMENTS_ROLLUP') -
FIELD 2 customer_long_description(customer_hierlist 'MARKET_ROLLUP') -
FIELD 3 customer_parentrel(customer_hierlist 'MARKET_ROLLUP') -
FIELD 9 customer_parentrel(customer_hierlist 'SHIPMENTS_ROLLUP')
CLEANUP:
IF funit NE na
THEN FILECLOSE funit
END
CUSTOMER is too large a dimension to show the complete results of the load. shows how to select a few base-level dimensions and their ancestors, so that you can check that the supporting objects were populated correctly.
Example 11-19 Viewing the CUSTOMER Dimension and Attributes
LIMIT customer TO customer_levelrel 'SHIP_TO' "Select base-level members
LIMIT customer KEEP FIRST 2 "Keep the first 2 base-level members
LIMIT customer ADD ANCESTORS USING customer_parentrel "Add all their ancestors
SORT customer A customer_levelrel A CUSTOMER "Sort the selected members within levels
REPORT W 8 DOWN customer W 16 <customer_long_description customer_levelrel> -
W 6 <customer_parentrel customer_inhier>
ALL_LANGUAGES: AMERICAN_AMERICA
---------------------------------------CUSTOMER_HIERLIST---------------------------------------
-----------------MARKET_ROLLUP----------------- ---------------SHIPMENTS_ROLLUP----------------
CUSTOM CUSTOM CUSTOM CUSTOM
CUSTOMER_LONG_DE CUSTOMER_LEVELRE ER_PAR ER_INH CUSTOMER_LONG_DE CUSTOMER_LEVELRE ER_PAR ER_INH
CUSTOMER SCRIPTION L ENTREL IER SCRIPTION L ENTREL IER
-------- ---------------- ---------------- ------ ------ ---------------- ---------------- ------ ------
22 Bavarian ACCOUNT 5 yes NA ACCOUNT NA NA
Industries
1 All Customers ALL_CUSTOMERS NA NA All Customers ALL_CUSTOMERS NA yes
5 Manufacturing MARKET_SEGMENT 7 yes NA MARKET_SEGMENT NA NA
9 Europe REGION 1 NA Europe REGION 1 yes
49 Bavarian Indust, SHIP_TO 22 yes Bavarian Indust, SHIP_TO 16 yes
GmbH Rome GmbH Rome
50 Bavarian Indust, SHIP_TO 22 yes Bavarian Indust, SHIP_TO 20 yes
GmbH London GmbH London
7 Total Market TOTAL_MARKET 14 yes NA TOTAL_MARKET NA NA
14 Germany WAREHOUSE 9 NA Germany WAREHOUSE 9 yes
16 Italy WAREHOUSE 9 NA Italy WAREHOUSE 9 yes
20 United Kingdom WAREHOUSE 9 NA United Kingdom WAREHOUSE 9 yes
UNITS_CUBE.DAT contains just the Units measure with columns for each dimension key. Example 11-20 shows several sample rows.
Example 11-20 UNITS_CUBE.DAT Flat File
CHANNEL_ID ITEM_ID SHIP_TO_ID MONTH_ID UNITS
---------- ---------- ---------- ---------- ----------
2 13 51 54 2
2 13 51 56 2
2 13 51 57 2
2 13 51 58 2
2 13 51 59 2
2 13 51 61 1
The data is written to the UNITS_VARIABLE variable, not to the UNITS formula. This is the definition of UNITS_VARIABLE:
DEFINE UNITS_VARIABLE VARIABLE DECIMAL <TIME UNITS_CUBE_COMPOSITE <CUSTOMER PRODUCT CHANNEL>>
Notice that it is dimensioned by UNITS_CUBE_COMPOSITE, but the incoming data is aligned with the base dimensions, as shown in Example 11-21. All four base dimensions are already populated.
Define the example program, then execute it with this command:
CALL read_units
Example 11-21 OLAP DML Program For Reading UNITS_CUBE.DAT
DEFINE READ_UNITS PROGRAM
PROGRAM
VARIABLE funit INTEGER "Define local variable for file handle
TRAP ON cleanup "Divert processing on error to cleanup label
funit = FILEOPEN('gx/units_cube.dat' READ) "Open the file
FILEREAD funit STRUCTURED -
FIELD 1 channel -
FIELD 2 product -
FIELD 3 customer -
FIELD 4 time -
FIELD 5 units_variable
cleanup:
IF funit NE na
THEN FILECLOSE funit
END
Measures typically contain vast amounts of data but are quite sparse, so you must target specific cells to verify that the data was loaded correctly. You can do this by selecting a row or two from the source file and limiting the workspace dimensions to those values, as shown in .
Example 11-22 Validating the UNITS_CUBE Data Load
limit time to '50' to '60'
limit channel to '2'
limit product to '13' '14'
limit customer to '51'
report down time across product: units_variable
CHANNEL: 2
CUSTOMER: 51
---UNITS_VARIABLE----
-------PRODUCT-------
TIME 13 14
-------------- ---------- ----------
50 2.00 2.00
51 2.00 NA
52 2.00 2.00
53 1.00 2.00
54 2.00 2.00
55 NA 2.00
56 2.00 2.00
57 2.00 NA
58 2.00 1.00
59 2.00 2.00
60 NA 1.00
If you enable the GLOBALX analytic workspace for the BI Beans now, the dimension views will have many empty columns. For example, the view of the CHANNEL dimension has these empty columns:
CHANNEL_GIDCHANNEL_PARENTGIDALL_CHANN_ALL_CHANNELSCHANNEL_CHANNELAW_MEMBER_ORDERThe ___POP_FMLYREL and ___ORDR.HIERARCHIES programs populate the workspace objects that are displayed by these columns. shows the commands used for the CHANNEL dimension. Repeat these commands for the PRODUCT, CUSTOMER, and TIME dimensions.
You do not need to re-enable the GLOBALX workspace after populating these objects. The data is available through the views as soon as you commit the changes to the database.
Example 11-23 OLAP DML Commands to Populate CHANNEL Metadata Objects
" Populate CHANNEL_GID and CHANNEL_FAMILYREL
CALL ___POP.FMLYREL('GLOBALX', 'GLOBALX!CHANNEL', 'GLOBALX!CHANNEL_HIERLIST', 'GLOBALX!CHANNEL_LEVELLIST', 'GLOBALX!CHANNEL_LEVELREL', 'CHANNEL', 'GLOBALX!CHANNEL_PARENTREL', 'GLOBALX!CHANNEL_INHIER')
" Populate CHANNEL_ORDER
call ___ordr.hierarchies('GLOBALX!CHANNEL', 'GLOBALX!CHANNEL_HIERLIST', 'GLOBALX!CHANNEL_HIER_CREATEDBY', 'CHANNEL_PARENTREL', 'CHANNEL_ORDER', 'CHANNEL_INHIER')
|
 Copyright © 2002, 2003 Oracle Corporation All Rights Reserved. |
|