| Oracle® OLAP Application Developer's Guide 10g Release 1 (10.1) Part Number B10333-02 |
|






|
View PDF |
| Oracle® OLAP Application Developer's Guide 10g Release 1 (10.1) Part Number B10333-02 |
|
|
View PDF |
This chapter explains how to create a standard form analytic workspace that performs optimally. It explores the various design decisions that affect how the data is stored in an analytic workspace, and thus how quickly it can be retrieved. These decisions are discussed in the context of using the wizards in Analytic Workspace Manager.
This chapter contains the following topics:
Creating a Standard Form Workspace Using Analytic Workspace Manager
Case Study: Aggregating Data in the GLOBAL Analytic Workspace
With OLAP Catalog metadata defined for your data source, you can choose from these methods for creating an analytic workspace:
Analytic Workspace Manager. The Create Analytic Workspace wizard is the easiest method of creating an analytic workspace, and the one described in this chapter. The wizard generates a SQL script of DBMS_AWM statements, which you can choose to execute immediately or save for execution later.
DBMS_AWM PL/SQL package. The DBMS_AWM package enables you to automate the build process in a script and schedule it to run overnight in a batch window. For most production systems, this is the preferred practice.
You can use the Create Analytic Workspace wizard to generate a basic script, then edit the script to make any changes. This is a much less tedious and time-consuming method than coding the scripts entirely by hand. The DBMS_AWM package provides greater flexibility in designing your analytic workspace than the graphical methods.
Figure 6-1 shows the relationships among the tools used in the build process.
Figure 6-1 Components Used With the OLAP Catalog to Build an Analytic Workspace
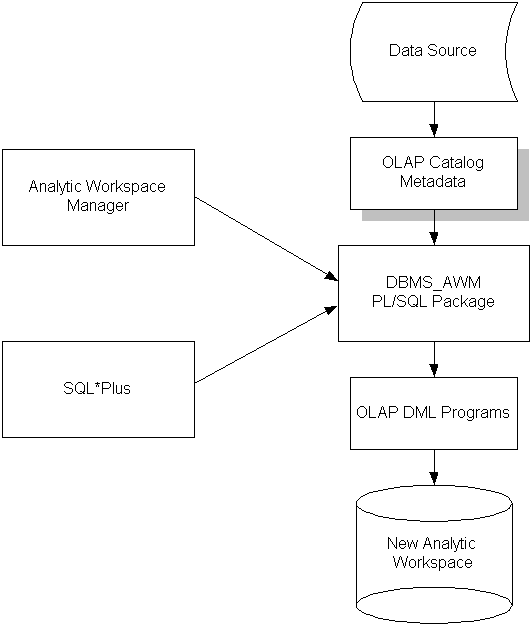
Analytic Workspace Manager is a primary tool for creating, developing, and managing analytic workspaces. It is a Java application that provides a graphical user interface to several PL/SQL packages and to the OLAP DML.
The console, or main window, provides two views: the OLAP Catalog View, and the Object View. You can switch between these two views using the View menu. In addition, there are menus, a toolbar, a navigation pane, and a display pane. When you select an object in the navigator pane, the display pane to the right provides detailed information about that object. When you right-click an object, you get a choice of menu items with appropriate actions for that object.
You can also conduct an interactive session using the OLAP DML, by opening OLAP Worksheet. You can switch between the console and OLAP Worksheet, and have an up-to-date view of your workspace in each one, because they share the same session.
Analytic Workspace Manager has a full online Help system, which includes context-sensitive Help.
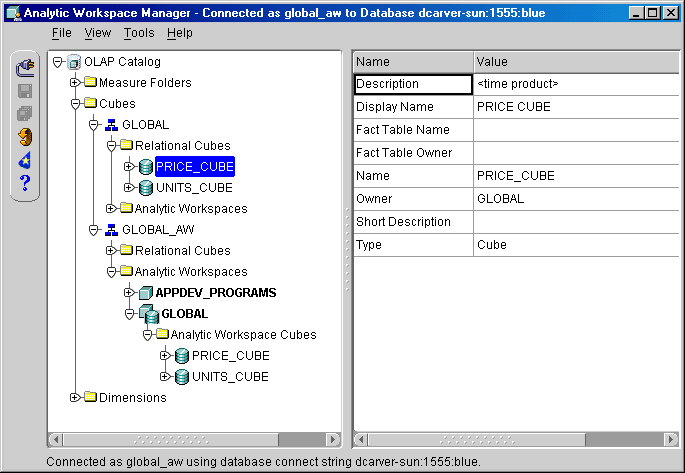
OLAP Catalog View displays all OLAP Catalog metadata that you own or that you have been given access rights to read, both CWM1 and CWM2. The view lists the primary logical objects: measure folders, cubes, and dimensions. You cannot create or change the metadata; to do that, you must use Oracle Enterprise Manager, Oracle Warehouse Builder, or the CWM2 PL/SQL procedures.
After you create an analytic workspace, the OLAP Catalog View shows the instantiated cubes in the analytic workspace in addition to the logical cubes in the relational model. You can augment the metadata by creating and deploying an aggregation plan on a workspace cube. An aggregation plan is associated with a workspace cube and is stored in the analytic workspace. It provides the rules for solving the data in a cube so that values are calculated for all levels.
Figure 6-2 shows the OLAP Catalog View. A relational cube named PRICE_CUBE in the GLOBAL schema is selected in the view, so the pane to the right displays information about the cube. Notice that an analytic workspace was created in the GLOBAL_AW schema from the relational cubes defined in GLOBAL.
Figure 6-2 OLAP Catalog View in Analytic Workspace Manager
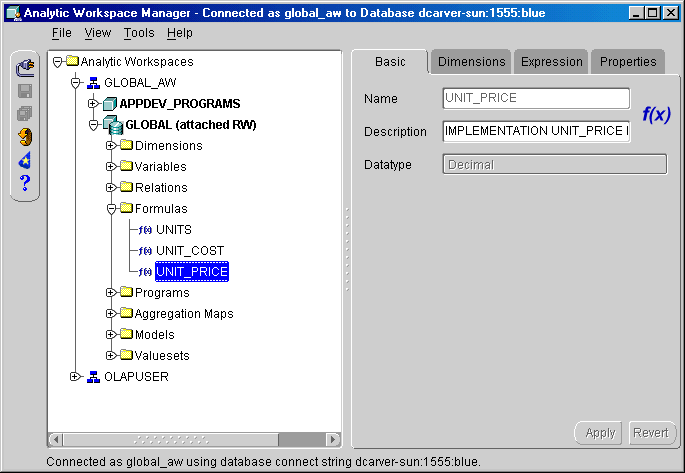
The Object View provides a graphical user interface to the OLAP DML. You can create, modify, and delete individual workspace objects. Using the tools available through the Object View, you can modify a workspace made by the Create Analytic Workspace wizard.
The Object View is useful primarily for managing the definitions of workspace objects. If you need to manage the contents of a workspace object or execute a program, or if you are adept at using the OLAP DML, then you can open OLAP Worksheet and have full use of the OLAP DML.
Figure 6-3 shows the Object View. A formula named UNIT_PRICE is currently selected, so the right pane shows information about the formula.
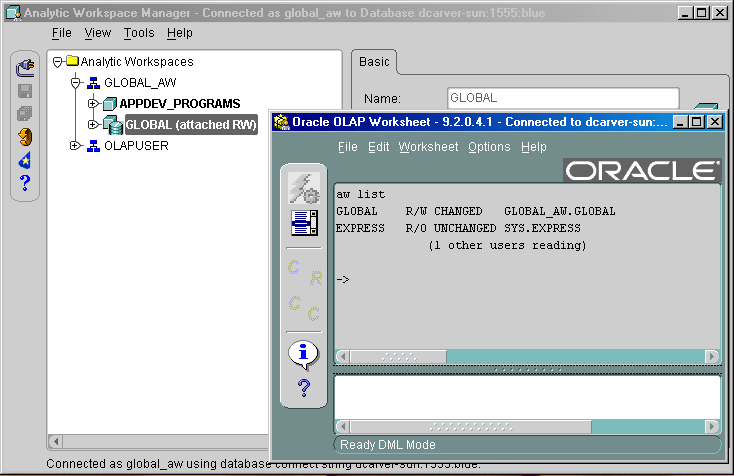
OLAP Worksheet opens in a separate window from the Analytic Workspace Manager console. This window provides menus, a toolbar, an input pane for OLAP DML commands on the bottom, and an output pane on the top.
Figure 6-4 shows OLAP Worksheet opened from Analytic Workspace Manager. Notice that the GLOBAL workspace is attached with read/write access in both OLAP Worksheet (as shown by the AW LIST command) and Analytic Workspace Manager (as shown by the Object View). The two applications share the same session.
Figure 6-4 OLAP Worksheet Opened From Analytic Workspace Manager
Using the Create Analytic Workspace wizard, you can create a workspace from one or more cubes in the OLAP Catalog. The resulting workspace is in database standard form, which is described in Appendix A.
The Create Analytic Workspace wizard provides reasonable defaults so that you can create an analytic workspace with the minimum number of decisions. By accepting the default settings, you create a physical storage model for your data that is appropriate for many types of data. If you are new to OLAP-type analysis, you may want to start by creating an analytic workspace with the default settings, and find out from using it whether its performance characteristics are acceptable.
However, good performance is critical in a production system. To create a workspace with the best performance, explore the characteristics of your data and set the advanced storage options appropriately for its requirements.
Always create an analytic workspace in a separate schema from the relational tables. This practice prevents conflicts in defining unique names within a single namespace.
Storage settings can have a huge impact on performance. When they are set incorrectly, you will experience poor performance for both data loads and run-time analysis. The default settings are appropriate when your data has the expected characteristics: a dense time dimension, and random sparsity (less than 30% non-null values) across the other dimensions.
Composite dimensions are a means of reducing the amount of space needed to store sparse data. Without composites, an analytic workspace stores a value for each combination of dimension members, even if that value is null (NA). With composites, only the combinations of dimension members with real data are stored. A combination of dimension members for which there is a data value is called a tuple. The addition of a data value to a variable automatically triggers the creation of a new composite tuple.
The order in which the dimensions are listed in a composite controls the order in which the composite tuples are stored. The dimensions are typically ordered by size (that is, number of members) so that the largest is the fastest varying and the smallest is the slowest varying. The composite tuples are stored so that the fastest varying dimension members are clustered together, and the slowest varying dimension members are the most widely separated. In the composite definition, the first dimension is the fastest varying, and the last dimension is the slowest varying.
For example, in a composite for <CUSTOMER PRODUCT CHANNEL>, CUSTOMER is the fastest varying and CHANNEL is the slowest varying.
Analytic Workspace Manager assumes that your data is sparse (that is, few data values compared to the number of cells in the cube), and will create one composite for each cube. The composite includes all dimensions except Time. Measures are often defined with the Time dimension first, regardless of its size, to facilitate time-based analysis and data refreshes.
If your Time dimension is sparse, then define a composite that includes Time. If another dimension is dense, then define a composite that excludes that dimension. (If you have a very small, dense dimension, you can include it as the last dimension in the composite.) Remember to order the dimensions in the composite from the one with the most members to the one with the fewest members.
The order in which the dimensions are listed in a cube affects performance because it determines the way the data is stored on disk. The first dimension in a cube is the fastest-varying dimension, and the last dimension is the slowest-varying dimension. The data for each measure in a cube is stored as a linear stream, in which the values of the fastest-varying dimension are clustered together.
Data storage is typically optimized for loads. List the dense dimension (such as Time) before the composite. If there is more than one dense dimension, then list the largest one first.
A segment is the amount of contiguous disk space reserved for storing the data in a measure. Performance is best when all of the data for a measure is stored in one segment.
Analytic Workspace Manager creates a segment large enough for the initial load. This setting defines a segment exactly large enough for the Time dimension (which is outside the composite) and plentifully large enough to store composite tuples as they are created. When you update your data, a second segment is created that is the same size as the first segment. Subsequent updates will be stored in this segment until it reaches its capacity in one of the dimensions, at which time a third, equal sized segment will be created, and so forth.
When you manually set the segment size, you can create a segment that permits future growth. Be sure to specify ample space, particularly for the fastest-varying dense dimension (that is, the first one in the list). Keep in mind, however, that you are reserving disk space that will not be available for other uses. Do not create a segment far in excess of realistic growth.
You can only specify the segment size for multidimensional variables. You cannot specify the segment size for variables dimensioned only by a composite or by a single dimension.
The Create Analytic Workspace wizard enables you to decide how much data you want to load and when you want to initiate the load.
You can create an analytic workspace with all of the object definitions and several choices of data:
No data
All data from the dimension tables but none from the fact tables
All data from the dimension tables and the fact tables
Partial builds enable you to make manual changes to the object definitions before loading the data. To load the data later, use the Refresh Analytic Workspace wizard.
The option of generating SQL scripts is particularly useful if you are working with a large amount of data. Scripts enable you to:
Make changes to the build process.
Schedule the build to run overnight in a batch window.
To create a workspace in database standard form:
Configure your database instance for OLAP use. Define permanent, temporary, and undo tablespaces, and set the database parameters to values appropriate for data loads. Refer to Chapter 12 for details.
Define a user who will own the analytic workspace. Grant the user the OLAP_USER role and SELECT privileges on the source data tables.
While you can create the workspace in the same schema as the relational tables, doing so causes problems in defining unique names within a single namespace.
Examine the sparsity characteristics of your data. The default data storage settings are appropriate for data that is dense across the Time dimension and sparse across all other dimensions. If your data has these sparsity characteristics, or you cannot determine them, then use the default data storage settings. Otherwise, when you run the Create Analytic Workspace wizard, define a composite that is appropriate for your data cube.
Open Analytic Workspace Manager and connect to your database instance as the user you defined earlier for this purpose.
If you want to generate log files, from the Tools menu choose Configuration. Click Help for further information.
Log files store the messages that are generated by the various wizards. They do not provide additional information, but they are useful if the wizard fails and you want to explore the reasons for the failure.
In the OLAP Catalog View, verify that you have defined dimensions, hierarchies, measures, and cubes for the source data, and that you have access to these logical objects from your current session.
From the Tools menu, choose Create Analytic Workspace Using Wizard. Complete the steps of the wizard. If you need to define a composite, be sure to select the advanced storage options.
Click the Help button to get specific information about each step.
You can enable the workspace for the BI Beans either now or later. You may want to postpone enabling until after you enhance your analytic workspace with aggregate data and custom measures.
If the workspace will support other types of applications, then you can enable it later using the appropriate wizard.
From the File menu, choose Save. This option commits all changes to the database made during this session.
If you chose a build option that defines objects without loading all of the data, then run the Refresh Analytic Workspace wizard when you are ready to complete the build.
When you have finished, you will have an analytic workspace populated with the detail data fetched from your relational star or snowflake schema.
The following case study explains the choices made in creating an analytic workspace from the GLOBAL star schema. Chapter 3 describes the tables.
This example creates the GLOBAL analytic workspace in a different schema from the source tables. Example 6-1 lists the SQL commands to define the GLOBAL_AW user with sufficient access rights to use Analytic Workspace Manager and to access the GLOBAL star schema. Alternatively, you can define users through Oracle Enterprise Manager.
Example 6-1 SQL Script for Defining the GLOBAL_AW User
CREATE USER "GLOBAL_AW" PROFILE "DEFAULT"
IDENTIFIED BY "global_aw" DEFAULT TABLESPACE "GLOBAL"
TEMPORARY TABLESPACE "OLAPTEMP"
QUOTA UNLIMITED ON "GLOBAL"
QUOTA UNLIMITED ON "OLAPTEMP"
ACCOUNT UNLOCK;
GRANT OLAP_USER TO GLOBAL_AW;
GRANT SELECT ON global.channel_dim TO global_aw;
GRANT SELECT ON global.product_dim TO global_aw;
GRANT SELECT ON global.customer_dim TO global_aw;
GRANT SELECT ON global.time_dim TO global_aw;
GRANT SELECT ON global.units_history_fact TO global_aw;
GRANT SELECT ON global.price_and_cost_history_fact TO global_aw;
By using SQL SELECT commands with the COUNT and COUNT(DISTINCT) functions, you can estimate how dense the resulting multidimensional cubes will be in the analytic workspace.
The PRICE_AND_COST_HISTORY_FACT table has 1407 rows with values for both UNIT_PRICE and UNIT_COST out of a possible 1728 dimension value combinations (48 months * 36 products). The Price cube (which is mapped to the PRICE_AND_COST_HISTORY_FACT table) is 80% dense, and so a composite will actually slow performance rather than improve it. A dense cube is fairly unusual, and the Create Analytic Workspace wizard does not support it, nor does the DBMS_AWM PL/SQL package. Thus, you will need to make some modifications to the workspace object definitions before loading the data.
The UNITS_HISTORY_FACT table has 110,166 rows with values for UNITS out of a possible 316,224 dimension value combinations (48 months * 36 products * 61 customers * 3 channels). This cube is 30% dense, which is sufficiently sparse for a composite.
Because Time is aggregated to the month level, the Time dimension is probably dense. This cube can use the default composite.
Make these choices when running the Create Analytic Workspace wizard:
On the Choose Data Loading Options page, do the following:
Choose the second build option, Build analytic workspace and load dimensions. This choice enables you to make modifications to the variable definitions before loading the data.
Clear the Generate unique keys box. The dimension tables use surrogate keys for all levels to assure unique dimension values.
On the Choose Advanced Storage and Naming Options page, no prefix is needed when naming the workspace objects because the analytic workspace is being created in a different schema from the relational tables. The cube name prefix is optional, but may be useful when an analytic workspace contains multiple cubes.
The selected build option causes the Create Analytic Workspace wizard to define all of the workspace objects and fetch all of the data from the dimension tables. The measures are defined but do not have data. You can make changes to the object definitions before loading the data.
(An alternative approach to the one taken in this example is to generate a SQL script and modify the calls to DBMS_AWM, so that the analytic workspace is generated correctly and does not require modification.)
Measure names such as UNIT_PRICE and UNIT_COST are given to the formulas in the analytic workspace that are used to aggregate the variables. The data itself is stored in variables with names like UNIT_PRICE_VARIABLE and UNIT_CUBE_VARIABLE.
Using OLAP Worksheet and the OLAP DML, you can make two changes to UNIT_PRICE_VARIABLE and UNIT_COST_VARIABLE:
Remove the composite. The Price cube is 80% dense, as explained in "Examining Sparsity Characteristics for GLOBAL". UNIT_PRICE_VARIABLE and UNIT_CUBE_VARIABLE store the data for the Price cube. Because these variables are dense, defining them with a composite would actually slow performance.
Change the data type. The data for the Price cube is easily handled by the SHORTDECIMAL data type. Use DECIMAL (8 bytes) and SHORTDECIMAL (4 bytes) whenever possible to save storage space and maximize performance. DECIMAL is the default numeric data type. For a full list of data types, search Analytic Workspace Manager Help.
These are significant changes that require the variables to be redefined, not simply modified.
Take these steps to redefine the variables:
In the Object View, attach the GLOBAL analytic workspace with read/write access.
Choose OLAP Worksheet from the Tools menu.
In the lower pane (the query window) enter this command to display the object definitions for the two variables:
FULLDSC price_cube_unit_price_variable price_cube_unit_cost_variable
Select the full object definitions from the top pane (the response window) and paste them into a text editor.
Edit the definitions so that they look like the following code example. Note the DELETE command at the beginning, the changes to the data type and dimensionality in the DEFINE commands, the addition of a CONSIDER command after each DEFINE, and the standard form PROPERTY commands listed with the full command on a single line.
DELETE PRICE_CUBE_UNIT_PRICE_VARIABLE PRICE_CUBE_UNIT_COST_VARIABLE DEFINE PRICE_CUBE_UNIT_PRICE_VARIABLE VARIABLE SHORTDECIMAL <TIME PRODUCT> CONSIDER PRICE_CUBE_UNIT_PRICE_VARIABLE PROPERTY 'AW$CLASS''EXTENSION' PROPERTY 'AW$CREATEDBY' 'AW$CREATE' PROPERTY 'AW$LASTMODIFIED' '20MAY03_10:37:08' PROPERTY 'AW$PARENT_NAME' 'PRICE_CUBE_UNIT_PRICE' PROPERTY 'AW$ROLE' 'VARIABLE' PROPERTY 'AW$SEGWDTH_CMD' 'chgdfn GLOBAL_AW.GLOBAL!PRICE_CUBE_UNIT_PRICE_VARIABLE segwidth 120 72' PROPERTY 'AW$STATE' 'CREATED' DEFINE PRICE_CUBE_UNIT_COST_VARIABLE VARIABLE SHORTDECIMAL <TIME PRODUCT> CONSIDER PRICE_CUBE_UNIT_COST_VARIABLE PROPERTY 'AW$CLASS' 'EXTENSION' PROPERTY 'AW$CREATEDBY' 'AW$CREATE' PROPERTY 'AW$LASTMODIFIED' '20MAY03_10:37:08' PROPERTY 'AW$PARENT_NAME' 'PRICE_CUBE_UNIT_COST' PROPERTY 'AW$ROLE' 'VARIABLE' PROPERTY 'AW$SEGWDTH_CMD' 'chgdfn GLOBAL_AW.GLOBAL!PRICE_CUBE_UNIT_COST_VARIABLE segwidth 85 72' PROPERTY 'AW$STATE' 'CREATED'
Save the file in, or move it to, a disk directory that has been defined as a directory object in the database. Then use the OLAP DML INFILE command to execute the file. INFILE is equivalent to the SQL @ command.
INFILE 'directory_object/filename'
Check the response window for errors. To fix them, edit the file and execute it again.
To save these changes, type these commands into the query window and execute them:
UPDATE COMMIT
After all of the changes are made to the workspace object definitions, run the Refresh wizard to load the data, as described in "Refreshing the Data in an Analytic Workspace" The dimensions do not need to be refreshed; only the cubes.
The workspace can be enabled now or after deploying an aggregation plan.
Although Global is used for most of the examples in this manual, Sales History has a very different set of data characteristics and demonstrates a correspondingly different set of build choices.
Sales History (SH) is a sample star schema that is delivered with your Oracle Database, along with a fully defined logical model stored in the OLAP Catalog. The SH schema has two cubes, SALES and COSTS. The SALES cube has five dimensions, and the COSTS cube uses two of these dimensions. This case study uses only the SALES cube.
|
See Also: Oracle Database Sample Schemas for a full description of Sales History. |
When building a large analytic workspace, the startup parameters for the Oracle Database affect how quickly the build proceeds. Example 6-2 shows a few of the settings in the init.ora file for building Sales History. For more information about these settings, refer to Chapter 12.
While the GLOBAL analytic workspace has less than a million cells for base-level data in its largest cube, the Sales History COST cube has over 235 trillion. This makes Sales History quite large for a sample schema, yet it is small to average for a real application. It is sufficiently large for the build to fail unless resources have been allocated specifically for its use. The build needs adequate temporary and permanent tablespaces:
Define a tablespace just for use by the Sales History analytic workspace, which is sufficiently large to hold the base-level data, stored aggregates, forecast data, and so forth. If possible, define extension files on separate physical disks. For the best performance, do not use the same tablespace as the star schema.
Define a temporary tablespace that is sufficiently large to hold the data for the SALES cube. Use a small EXTENT MANAGEMENT SIZE value, such as 256K.
Example 6-3 shows how the tablespaces might be defined for Sales History.
Example 6-3 SQL Script for Defining Tablespaces for the Sales History Analytic Workspace
/* Create a permanent tablespace on four disks */ CREATE TABLESPACE sh_aw DATAFILE '/disk1/oradata/sh_aw1.dbf' SIZE 64M AUTOEXTEND ON NEXT 64M MAXSIZE 1024M EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO; ALTER TABLESPACE sh_aw ADD DATAFILE '/disk2/oradata/sh_aw2.dbf' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE 1024M,'/disk3/oradata/sh_aw3.dbf' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE 1024M,'/disk4/oradata/sh_aw4.dbf' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE UNLIMITED; /* Create a temporary tablespace on four disks */ CREATE TEMPORARY TABLESPACE sh_temp TEMPFILE '/disk1/oradata/sh_aw.tmp' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE 1024M EXTENT MANAGEMENT LOCAL UNIFORM SIZE 256K; ALTER TABLESPACE sh_temp ADD TEMPFILE '/disk2/oradata/sh_aw2.tmp' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE 1024M,'/disk3/oradata/sh_aw3.tmp' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE 1024M,'/disk4/oradata/sh_aw4.tmp' SIZE 64M REUSE AUTOEXTEND ON NEXT 64M MAXSIZE UNLIMITED;
The data in the SH relational schema is extremely sparse. Many dimension keys are never used as foreign keys in the SALES fact table, much less used in all possible combinations with the other four dimensions. For example, CUSTOMERS.CUST_ID has 5100 values, of which only 2557 are used in the SALES.CUST_ID column.
Time is also a sparse dimension, with only 1075 of 1826 dimension members used. Thus, TIMES_DIM must be included in the composite. You can define a composite with all five dimensions by choosing Advanced Storage Options. List TIMES as the first dimension (the fastest varying) in the composite, to facilitate time-based analysis and data maintenance, even though it is smaller than PRODUCTS and CUSTOMERS. List the other dimensions from largest to smallest. This information is easily obtained by issuing a SELECT COUNT(*) on the dimension tables.
Because SH is large, you may want to manage these aspects of the build:
Time: Execute the build during off-peak hours. To do this, generate a SQL script for the build instead of creating it immediately.
Progress Monitor: Add comments to the SQL script so that you can monitor its progress. If the build fails for any reason, or if you need to interrupt it, you can restart the script from where the build stopped.
Permanent Tablespace Size: If possible, define some measures with smaller data types, as described in "Manually Changing Object Definitions". This type of change requires you to choose one of the partial build options.
For a description of data types, search Help in Analytic Workspace Manager.
Make these choices in the Create Analytic Workspace wizard for building Sales History, based on the previous discussion:
On the Choose Data Loading Options page, do the following:
Choose the second build option, Build analytic workspace and load dimensions. This choice enables you to make modifications to the variable definitions before loading the data.
Clear the Generate unique keys box. The dimension tables use surrogate keys for all levels to assure unique dimension values.
On the Choose Advanced Storage and Naming Options page, select Advanced Storage Options. This choice enables you to define a composite that includes the TIMES dimension.
No prefix is needed because the analytic workspace is being created in a different schema from the relational tables. The cube name prefix is optional, but may be useful when an analytic workspace contains multiple cubes.
When creating the composite, include all of the dimensions and put them in this order. Do not specify a segment size, because a very large segment is allocated automatically for composites.
TIMES PRODUCTS CUSTOMERS PROMOTIONS CHANNELS
On the Choose Create and Enablement Options page, select Save Script to File. You do not need to enable the workspace at this time.
Take these steps to build the Sales History analytic workspace:
Run the build script. After it has completed successfully, you have an analytic workspace with all of the dimensions, hierarchies, levels, and attributes from the dimension tables.
Make any changes or additions to the object definitions.
Run the Refresh wizard to load the data, as described in "Refreshing the Data in an Analytic Workspace". The dimensions do not need to be refreshed; only the cubes.
The workspace can be enabled now or after deploying an aggregation plan.
An analytic workspace initially contains only the detail data from the relational schema. However, it also contains the hierarchies, levels, and parent relations that are needed to aggregate the data. The aggregate data in an analytic workspace replaces the use of materialized views; all of the aggregate data is created in the analytic workspace. To optimize run-time performance, you must generate and store some aggregate data.
A data cube in an analytic workspace can be solved at two distinct times:
At run-time when needed. The cells for the aggregate values are NA (null) until a query requests the aggregate values. The aggregates are then calculated in response to the query. This type of aggregation is referred to as on-the-fly or run-time aggregation. Run-time aggregation slows querying time since the data must be calculated instead of just retrieved, but it does not require storage in a permanent tablespace for the aggregate values.
As a data maintenance procedure. The DBA calculates the aggregate values and stores them in the analytic workspace for all users to share. This type of aggregate data is sometimes call precomputed or stored aggregates. Stored aggregates support the fastest querying time, but increase the size of the analytic workspace and therefore the size of the relational database. The amount of stored data may also be limited by the amount of time available for data maintenance, which is typically limited to a batch window. Fully materializing a cube may simply take more time than the batch window permits.
When dimensions have multiple hierarchies or the hierarchies have many levels, fully aggregating the measures increases the size of your analytic workspace (and thus your database) geometrically. At the same time, much of the intermediate level data may be accessed infrequently or not at all.
A typical strategy is to aggregate some of the data as a data maintenance procedure and the rest of the data on demand. This strategy is called skip-level aggregation. The data cube is presented to the application fully solved, with no detectable difference between the values that were retrieved from storage and the values that were calculated for the query. When skip-level aggregation is done correctly, the time to calculate the unsolved levels is negligible.
A good strategy for identifying levels for pre-aggregation is to determine the ratio of dimension members at each level, and to keep the ratio of members to be rolled up on the fly at approximately 10:1. This ratio assures that all answer sets can be returned quickly. Either the data is stored in the analytic workspace, or it can be calculated by rolling up 10 values at a time into each aggregate value.
This 10:1 rule is best applied with some judgment. You might want to permit a higher ratio for levels that you know are seldom accessed. Or you might want to pre-calculate levels at a lower ratio if you know they have heavy use.
An analytic workspace that was created by the Create Analytic Workspace wizard has a default set of rules, called an aggregation plan, for each cube. A default plan specifies that:
No aggregate levels are stored. All aggregate data is calculated at run-time as necessary to return an answer set to a query.
All measures in the cube use the default plan.
The default aggregation plans assure that the measures in a cube are always presented to an application with fully solved data; that is, all levels of all hierarchies in an answer set are populated. However, because the default plans specify that all levels must be calculated during the user's session, their use typically causes unacceptably slow performance.
You can define and deploy aggregation plans that precalculate some of the data. Each measure can have its own aggregation plan, or any number of measures in a cube can share the same one. For each aggregation plan that you create, you must specify:
Which aggregate levels are stored.
Which measures in the cube use the plan.
An aggregation plan does not take effect until it is deployed. Deployment creates and modifies objects in the analytic workspace to support the aggregation plan, and then calculates all stored aggregate levels. While you can create an aggregation plan in a few minutes, deployment can take much longer, depending on the amount of data that needs to be calculated and the available resources. You may want to schedule aggregation for off-peak hours.
An aggregation plan can be used for all the measures in a cube, or just for selected measures.
To create an aggregation plan:
Expand the Cubes folder of OLAP Catalog View so that you can see the names of the analytic workspaces in your schema.
Right-click the name of your workspace.
Choose Create Aggregation Plan Using Wizard. Complete the steps of the wizard.
Click the Help button to get specific information about each step.
The aggregation plan is a permanent part of your analytic workspace until you explicitly delete it.
The Aggregation Plan wizard always specifies SUM as the method of aggregation. However, you can change the method to one of these operators:
AVERAGEFIRSTLASTMAXMINA procedure in the DBMS_AWM package changes the operator in an existing aggregation plan. The syntax of the procedure call is this:
EXECUTE DBMS_AWM.SET_AWCUBEAGG_SPEC_AGGOP('aggplan', 'aw_owner', 'aw_name', 'cube', 'measure', 'dimension', 'operator')
For the BI Beans to be aware of this change, you must either re-enable your analytic workspace or manually execute the CWM2_OLAP_METADATA_REFRESH.MR_AC_REFRESH procedure.
See the example in "Aggregating the Global Price Cube". For a full discussion of the syntax, refer to the Oracle OLAP Reference.
Deployment first deletes any previously aggregated data, then solves the data for the specified levels.
To deploy an aggregation plan:
Expand the OLAP Catalog View sufficiently to see the names of the aggregation plans for your workspace.
Right-click the name of an aggregation plan, and choose Deploy Aggregation Plan Using Wizard. Complete the steps of the wizard.
You can edit an aggregation plan, but no change is made to your data until you redeploy the modified plan. Similarly, you can delete an aggregation plan, but no change is made until you deploy another plan for the same measures.
You must redeploy your aggregation plans whenever you refresh the data. Refer to "Refreshing the Data in an Analytic Workspace" for further information.
GLOBAL contains two cubes. Aggregates for the Units cube are summed, which is the default, but aggregates for the Price cube are averaged. All measures within each cube are aggregated in the same way.
To identify the levels to be precalculated, you must know the number of dimension members at each level. You can easily acquire this information using either SQL statements or OLAP DML commands.
For example, this SQL statement:
SELECT COUNT(DISTINCT year_id) FROM global.time_dim;
and this OLAP DML command in the GLOBAL analytic workspace:
SHOW NUMLINES(LIMIT(time TO time_levelrel EQ 'Year'))
both return the number of TIME dimension members at the Year level.
Global is a very small data set, so few adjacent levels have a 10:1 ratio of dimension members. Table 6-1 identifies the levels to be calculated and stored in the analytic workspace.
Table 6-1 Precalculated Levels in the Global Workspace
| Dimension | Level | Members | Precalculate |
|---|---|---|---|
TIME |
Month |
60 | X |
TIME |
Quarter |
20 | -- |
TIME |
Year |
5 | X |
CUSTOMER |
Ship_To |
61 | X |
CUSTOMER |
Account |
24 | -- |
CUSTOMER |
Market_Segment |
5 | X |
CUSTOMER |
Total_Market |
1 | -- |
CUSTOMER |
Warehouse |
11 | -- |
CUSTOMER |
Region |
3 | X |
CUSTOMER |
All_Customers |
1 | -- |
PRODUCT |
Item |
36 | X |
PRODUCT |
Family |
9 | -- |
PRODUCT |
Class |
2 | X |
PRODUCT |
Total_Product |
1 | -- |
CHANNEL |
Channel |
3 | X |
CHANNEL |
All_Channels |
1 | -- |
Take these steps to aggregate the Price cube.
Run the Create Aggregation Plan wizard and create a plan for PRICE_CUBE.
In the Object View, attach the GLOBAL analytic workspace in read/write mode.
From the Tools menu, choose OLAP Worksheet.
From the Options menu of OLAP Worksheet, select SQL Mode.
Type these SQL statements in the query window.
EXECUTE DBMS_AWM.SET_AWCUBEAGG_SPEC_AGGOP('price_aggplan', 'global_aw', 'global', 'price_cube', 'unit_price', 'time', 'AVERAGE')
EXECUTE DBMS_AWM.SET_AWCUBEAGG_SPEC_AGGOP('price_aggplan', 'global_aw', 'global', 'price_cube', 'unit_cost', 'time', 'AVERAGE')
In the OLAP Catalog View, run the Deploy Aggregation Plan wizard to generate the aggregate data.
From the File menu, choose Save.
Enable the GLOBAL analytic workspace for the BI Beans.
Oracle applications are typically designed to run against relational tables in the Oracle Database. The relational tables must conform to certain standards set by the application, and some form of metadata is used to identify the data to the application. For example, the BI Beans requires a star or snowflake schema with embedded total dimension views for solved data, and OLAP Catalog metadata to describe the schema.
The same applications, without modification, can run against analytic workspaces which have been enabled for their use. Enabling an analytic workspace means that you have:
Created views of analytic workspace data that conform to the same criteria as the relational tables typically used by the application. These views use the OLAP_TABLE function to extract workspace data.
Created any metadata required by the application in order to access the views.
To enable an analytic workspace, complete these steps:
Expand the OLAP Catalog View sufficiently to see the workspaces for your schema.
Right-click the name of the analytic workspace you want to enable.
Choose Enable Workspace for OLAP API & BI Beans.
or
Enable Workspace for Oracle Discoverer Using Wizard.
Complete the steps of the wizard. Click the Help button to get specific information about each step.
When you enable an analytic workspace for the BI Beans, you create several views that form a star schema. In addition, you create CWM2 metadata, which makes these views accessible to BI Beans applications.
|
See Also: Oracle OLAP Reference for full descriptions of the views andCWM2 read API. |
The star schema for a BI Beans-enabled analytic workspace includes:
A dimension view for each hierarchy
A fact view for each combination of dimension hierarchies
These views are sometimes called embedded total views because dimension members at all levels are listed in a single column. Information about which level a particular member belongs to and the parent-child relationships among members is stored in separate columns. Within the fact tables, summary data is interspersed with (or embedded in) the base-level data. This differs markedly from the source star schema, in which there is no summary data in the fact tables and each level is represented by its own column in the dimension tables.
Table 6-2 describes the views created in the GLOBAL_AW schema when the GLOBAL analytic workspace is enabled.
Table 6-2 Views of the GLOBAL Analytic Workspace for the BI Beans
| Name of View | Description |
|---|---|
GLOB_GLOBA_CHANN_CHANN5VIEW |
CHANNEL dimension view, CHANNEL_ROLLUP hierarchy |
GLOB_GLOBA_CUSTO_MARKE6VIEW |
CUSTOMER dimension view, MARKET_SEGMENT hierarchy |
GLOB_GLOBA_CUSTO_SHIPM7VIEW |
CUSTOMER dimension view, SHIPMENTS hierarchy |
GLOB_GLOBA_PRODU_PRODU1VIEW |
PRODUCT dimension view, PRODUCT_ROLLUP hierarchy |
GLOB_GLOBA_TIME_CALEN2VIEW |
TIME dimension view, CALENDAR hierarchy |
GLOB_GLOBA_PRICE_CU4VIEW |
PRICE_CUBE measure view |
GLOB_GLOBA_SALES_CU10VIEW |
SALES_CUBE measure view, CUSTOMER MARKET_SEGMENT hierarchy |
GLOB_GLOBA_SALES_CU9VIEW |
SALES_CUBE measure view, CUSTOMER SHIPMENTS hierarchy |
GLOB_GLOBA_UNITS_CU12VIEW |
UNITS_CUBE measure view, CUSTOMER MARKET_SEGMENT hierarchy |
GLOB_GLOBA_UNITS_CU13VIEW |
UNITS_CUBE measure view, CUSTOMER SHIPMENTS hierarchy |
When an analytic workspace is enabled for the BI Beans, OLAP Catalog metadata is created for the relational views, as described previously.
OLAP Catalog metadata for analytic workspaces is stored in a set of tables, which you can access through a set of views owned by OLAPSYS. The public synonyms for these views have a prefix of ALL_OLAP2.
The BI Beans query a special set of views, also owned by OLAPSYS, with the public synonym MRV_OLAP2. These views are created from the CWM2 metadata tables with a special structure that improves performance.
You can browse the metadata in the OLAP Catalog View of Analytic Workspace Manager, or you can use SQL commands to query the views. Example 6-4 shows the results of a query.
To enable an analytic workspace, complete these steps:
Expand the OLAP Catalog View to see the workspaces for your schema.
Right-click the name of the analytic workspace you want to enable.
Choose Enable Workspace for Oracle Discoverer Using Wizard. Complete the steps of the wizard.
Click the Help button to get specific information about each step.
Detach the analytic workspace, saving your changes first if necessary.
To create the views, execute the SQL script generated by the wizard.
To create an End User Layer (EUL), use Oracle Discoverer Administrator to import the EEX file generated by the wizard.
The Enable for Discoverer wizard generates two files on your local computer, where you are running Analytic Workspace Manager:
A SQL script that creates views of workspace data in the format required by Discoverer.
An EEX file that contains XML for creating an End User Layer.
Your analytic workspace is not enabled until you run the script and import the EEX file.
This release supports only one hierarchy for each dimension. If a dimension has multiple hierarchies, you must select one of them for access through Discoverer.
Enabling an analytic workspace for Discoverer generates two sets of views.
The first set of views contains the OLAP_TABLE function calls that actually extract the data. This set exists to simplify creation of views in the format used by Discoverer (the second set of views), requiring that only a few object types and table types be defined. This set contains two types of views. Both sets use a letter and digit identifier, instead of the names, to identify the schema, the dimensions, and the levels.
A view of the complete analytic workspace, with all dimensions and all measures. The name in this format:
workspace_schema_FULL_VIEW
where schema is an S followed by a digit, such as S1.
A view for each dimension. The names are in this format:
TFDV_dimension_VIEW
where dimension is a D followed by a digit, such as D5.
The second set of views selects data from the first set, and presents the analytic workspace data in the format required by Discoverer. This set also has two types of views.
A measure view for each combination of dimension levels. This view runs against the FULL_VIEW described earlier. The names are in this format:
FACTVIEW_schema_level_level_level...
where schema is an S followed by a digit, such as S1, and level is an L followed by a digit, such as L1.
A view for each dimension. This view runs against the TFDV view described earlier. The names are in this format:
DV_dimension
where dimension is a D followed by a number, such as D1.
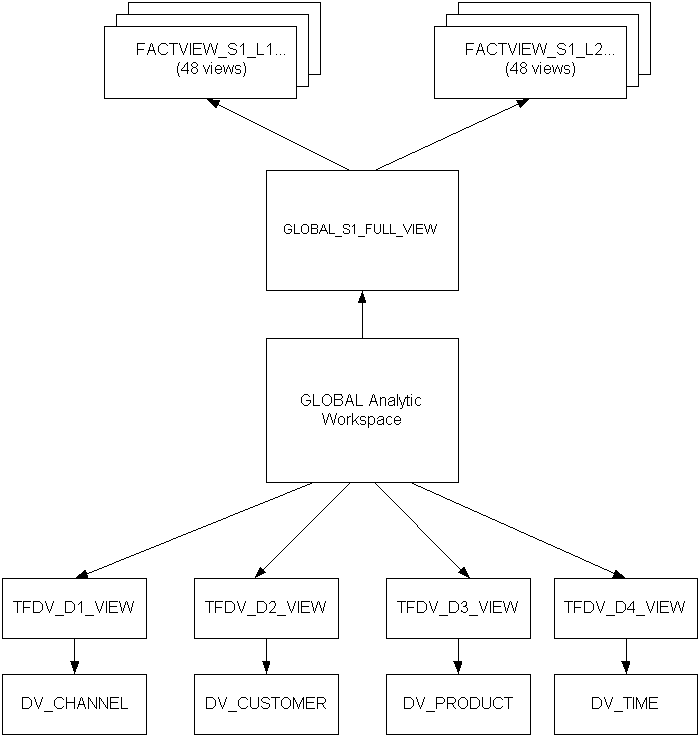
Figure 6-5 shows the relationships among the views.
Table 6-3 describes the views of the GLOBAL analytic workspace.
Table 6-3 Views of the GLOBAL Analytic Workspace for Oracle Discoverer
| View | Description |
|---|---|
GLOBAL_S1_FULL_VIEW |
Uses the OLAP_TABLE function to create a complete view of all dimensions and measures in the GLOBAL analytic workspace |
TFVD_D1_VIEW |
Uses the OLAP_TABLE function to create a PRODUCT dimension view |
TFVD_D2_VIEW |
Uses the OLAP_TABLE function to create a TIME dimension view |
TFVD_D3_VIEW |
Uses the OLAP_TABLE function to create a CHANNEL dimension view |
TFVD_D4_VIEW |
Uses the OLAP_TABLE function to create a CUSTOMER dimension view |
FACTVIEW_S1_L1_L6_L10_L14 |
Selects all measures at the ALL_CHANNELS, ALL_CUSTOMERS, TOTAL_PRODUCT, and YEAR levels from GLOBAL_S1_FULL_VIEW. |
FACTVIEW_S1_L1_L6_L10_L15 |
Selects all measures at the ALL_CHANNELS, ALL_CUSTOMERS, TOTAL_PRODUCT, and QUARTER levels from GLOBAL_S1_FULL_VIEW. |
. |
. |
. |
. |
. |
. |
FACTVIEW_S1_L2_L9_L13_L15 |
Selects all measures at the CHANNEL, SHIP_TO, ITEM, and QUARTER levels from GLOBAL_S1_FULL_VIEW. |
FACTVIEW_S1_L2_L9_L13_L16 |
Selects all measures at the CHANNEL, SHIP_TO, ITEM, and MONTH levels from GLOBAL_S1_FULL_VIEW. |
DV_CHANNEL |
Selects the CHANNEL dimension view from TFVD_D3_VIEW. |
DV_CUSTOMER |
Selects the CUSTOMER dimension view from TFVD_D4_VIEW. |
DV_PRODUCT |
Selects the PRODUCT dimension view from TFVD_D1_VIEW. |
DV_TIME |
Selects the TIME dimension view from TFVD_D2_VIEW. |
Some build options do not load data, so you must perform an initial refresh before your analytic workspace can be used. Over time, all analytic workspaces need to be refreshed with new data. The data source will have new time periods as well as other new dimension members.
The Refresh Analytic Workspace wizard adds new members for selected dimensions and reloads all of the data for selected measures. The wizard requires the new data to be in the same tables as the original data.
To refresh your data, complete these steps:
Expand the OLAP Catalog View to see the workspaces for your schema.
Right-click the name of the analytic workspace you want to enable.
Choose Refresh Analytic Workspace Using Wizard. Complete the steps of the wizard. You can refresh individual dimensions, or measures, or both.
Click the Help button to get specific information about each step.
Re-enable the cube if necessary.
Re-deploy the aggregation plans.
The Refresh wizard accesses the same tables that the Create Analytic Workspace wizard used originally. However, you may bring new data into your relational schema in separate tables. You can either write a load program in SQL using the DBMS_AWM package, or follow these alternative steps.
These are the basic steps for refreshing a cube:
In the Object View of Analytic Workspace Manager, attach the analytic workspace in Read/Write mode.
In the Object View, expand the Programs folder and select the load program that was generated by the Create Analytic Workspace wizard to load data for the original build.
If you are not sure which program to choose, then expand the Dimension folder and select the cubedef dimension. On the Properties page, note the value of the AW$LOADPRGS property.
On the Program page of the property viewer, edit the load program and change the name of the source table.
Choose Apply, then Compile.
Correct any errors before continuing.
Right-click the name of the load program, then choose Copy to Clipboard.
Open OLAP Worksheet, and execute the program. Paste the name of the program into the query window by typing Ctrl+V.
CALL program
Check the new data using the LIMIT and REPORT commands.
Issue UPDATE and COMMIT commands to save the new data.
The Global star schema provides an additional month of data in separate update tables.
In the Object View, expand the Programs folder and select GLOBAL_AW.GLOBAL!___GET.CUBE.DATA_UNITS_CUBE_1.
Display the Program page of the load program, and locate the name of the source file, UNITS_HISTORY_FACT.
SQL DECLARE C1 CURSOR FOR SELECT CHANNEL_ID,SHIP_TO_ID,ITEM_ID, -
MONTH_ID,UNITS FROM GLOBAL.UNITS_HISTORY_FACT
Edit this statement by replacing UNITS_HISTORY_FACT with UNITS_UPDATE_FACT.
Choose Apply, then Compile.
Open OLAP Worksheet and run the revised load program with a command like this:
CALL ___get.cube.data_units_cube_1
Display a sample of the new data with commands like these:
LIMIT channel TO '1' "Select any channel
LIMIT product TO '1' "Select any product
LIMIT time TO '91' "Select the new time period
LIMIT customer TO '76' "Select any customer
" Add the parent values of customer 76
LIMIT customer ADD ANCESTORS USING customer_parentrel
REPORT DOWN customer units "View the new data
CHANNEL: 1
PRODUCT: 1
--UNITS---
---TIME---
CUSTOMER 91
-------------- ----------
76 1,220.00
17 7,378.00
8 12,985.00
1 50,632.00
Save the changes with these commands:
UPDATE COMMIT
or
From the File menu of Analytic Workspace Manager, choose Save.
Routine refreshes of the data do not require you to re-enable the workspace for a particular application, because the views created by the enablers do not need to be redefined for new dimension members. However, you do need to re-enable your workspace if you make changes to the logical model, such as:
Change the OLAP Catalog metadata for the source cubes
Add or delete a cube in the analytic workspace
Add or delete a measure in the analytic workspace
Add or delete a hierarchy in the analytic workspace
Add or delete a level in the analytic workspace
Change the OLAP Catalog metadata for the analytic workspace.
Because the enabling step takes only a short time to complete, you may prefer to re-enable your analytic workspace each time you refresh it.
If you want to delete old dimension members (for example, roll off the same number of old time periods as you added new ones) or load only new data values, then you can generate build scripts and modify the calls to the DBMS_AWM package.
|
See Also: Oracle OLAP Application Developer's Guide for reference information about theDBMS_AWM package. |
|
 Copyright © 2002, 2003 Oracle Corporation All Rights Reserved. |
|