Release 2 (9.2)
Part Number A96598-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Real Application Clusters Deployment and Performance Release 2 (9.2) Part Number A96598-01 |
|
This chapter describes how to monitor Oracle Real Application Clusters performance and includes the following topics:
| See Also:
Chapter 5, "Monitoring Performance in Real Application Clusters with Oracle Performance Manager" for information about monitoring Real Application Clusters performance with Oracle Enterprise Manager |
All single instance tuning practices apply to applications running on Real Application Clusters databases. Therefore, review and implement the single-instance tuning methodologies described in Oracle9i Database Performance Planning.
Real Application Clusters databases should not require any more tuning than single-instance Oracle databases. This is because Cache Fusion does not use disk writes for cache coherency. Therefore, your performance monitoring effort for Real Application Clusters databases should be limited to the steps outlined in this chapter.
This section describes the following Real Application Clusters-specific configuration recommendations:
Because Cache Fusion exploits high speed IPCs, Real Application Clusters benefits from the performance gains of the latest technologies for low latency communication links used in cluster database interconnects. You can expect even greater performance gains if you use more efficient protocols, such as Virtual Interface Architecture (VIA) and user-mode IPCs.
Cache Fusion reduces CPU use with user-mode IPCs, also known as memory-mapped IPCs, for UNIX, Windows NT, and Windows 2000 platforms. If the appropriate hardware support is available, then operating system context switches are minimized beyond the basic reductions achieved with Cache Fusion alone. This also eliminates costly data copying and system calls.
If your hardware efficiently implements them, then user-mode IPCs can reduce CPU use. This is because user processes in user-mode IPCs communicate without using operating system kernels. In other words, user processes do not have to switch from user execution mode to kernel execution mode.
The buffer cache and shared pool capacity requirements in Real Application Clusters are slightly greater than those in single-instance Oracle databases. To facilitate recovery, Real Application Clusters may need additional memory to maintain duplicates of data blocks, or Past Images (PI), for blocks cached in more than one instance. Therefore, increase the size of the buffer cache by about 10% and increase the size of the shared pool by about 15%.
As in single-instance Oracle environments, you may be able to improve the buffer cache hit ratio by more aggressively flushing buffers that are not used frequently. For example, you can increase database writer (DBWRn) activity by using incremental checkpoints.
The rate of incremental checkpointing depends on the settings for various parameters, such as FAST_START_MTTR_TARGET, LOG_CHECKPOINT_TIMEOUT, and LOG_CHECKPOINT_INTERVAL. Setting these parameters to nonzero values results in more frequent writing of dirty or cold buffers. Consequently, the duration of instance recovery decreases and buffer cache use is more efficient. This results in more space being available to cache data blocks.
| See Also:
Oracle9i Database Performance Planning for more information about checkpointing and performance |
The interconnect and internode communication protocols can affect Cache Fusion performance. In addition, the interconnect bandwidth, its latency, and the efficiency of the IPC protocol determine the speed with which Cache Fusion processes consistent-read block requests.
Once your interconnect is operative, you cannot significantly influence its performance. However, you can influence an interconnect protocol's efficiency by adjusting the IPC buffer sizes.
| See Also:
Your vendor-specific interconnect documentation for more information about adjusting IPC buffer sizes |
Message traffic for Global Cache Service (GCS) and Global Enqueue Service (GES) processing must use the appropriate interconnect. If you are uncertain about the IP address or the NIC that Real Application Clusters-related traffic uses, then execute the following platform-independent SQL*Plus statements:
SQL> oradebug setmypid SQL> oradebug ipc
This command sequence causes Oracle to write information about the IP address that Oracle is using for interconnect traffic to a trace file in the user_dump_dest directory. Although you should rarely need to set this parameter, you can use the CLUSTER_INTERCONNECTS parameter to assign a private network IP address or NIC as in the following example:
CLUSTER_INTERCONNECTS=10.0.0.1
If you are using an operating system-specific vendor IPC protocol, then the trace information may not reveal the IP address. However, Oracle uses the correct network interface based on the use of vendor-specific IPC libraries.
| See Also:
Oracle9i Real Application Clusters Administration for information about setting the |
Each instance has a set of instance-specific views. You can also query global dynamic performance views to retrieve performance information from all qualified instances. Global dynamic performance view names are prefixed with GV$.
A global view contains all columns from its respective instance-specific view as well as the INST_ID column. This column displays the instance number from which Oracle obtains the associated instance-specific information. You can use it as a filter to retrieve information from a subset of instances. For example, the following query retrieves information from instances 2 and 5:
SELECT INST_ID,NAME,VALUE FROM GV$SYSSTAT WHERE NAME LIKE 'global cache%' AND (INST_ID =2 OR INST_ID=5);
Each global view contains a GLOBAL hint that creates a query executed in parallel to retrieve the contents of the local views on each instance. If the number of parallel execution processes in an instance reaches the limit of the value set for PARALLEL_MAX_SERVERS and you submit an additional query against a GV$ view, then Oracle spawns one additional parallel execution process for this purpose. The extra process is not available for parallel operations other than to perform GV$ queries.
|
Note: Oracle does not spawn additional parallel execution server processes to accommodate GV$ queries if you have set |
If the number of parallel execution processes on an instance reaches the value set for PARALLEL_MAX_SERVERS and you issue multiple GV$ queries, then all queries except for the first query will fail. In most parallel queries, if a process could not be allocated, then it would result in either an error or in a sequential execution of the query by the query coordinator.
See Also:
|
If you did not create your Real Application Clusters database with the Database Configuration Assistant (DBCA), then run the CATCLUST.SQL script to create Real Application Clusters-related views and tables. You must have SYSDBA privileges to run this script.
| See Also:
Oracle9i Database Reference for more information on dynamic performance views |
This section provides an overview of statistics from V$ and GV$ views that you can use to evaluate block traffic in your cluster. Use these statistics to analyze interconnect block transfer rates as well as the overall performance of your Real Application Clusters database. This section includes the following topics:
Real Application Clusters-specific statistics appear as message request counters or as timed statistics. Message request counters include statistics showing the number of certain types of block mode conversions. Timed statistics reveal the total or average time waited for read and write I/O for particular types of operations.
Many statistics measure the work done by different components of the database kernel, such as the cache layer, the transaction layer, or the I/O layer. For example, timed statistics reveal the amount of time spent processing certain requests and the amount of time waited for specific events. Oracle records most statistics in each instance's System Global Area (SGA).
Oracle Corporation recommends that you record statistics about the rates at which certain events occur. Maintaining a history of system performance identifies trends as these statistics change. Performance trends also highlight problems that contribute to increased response times and reduced throughput. They also help identify processing requirements changes during peak capacity periods.
Oracle collects Cache Fusion-related performance statistics from the buffer cache and Global Cache Service (GCS) layers. The statistics that Oracle collects describe general Real Application Clusters performance statistics as well as statistics for block requests and block mode conversion waits.
Oracle records object level statistics by default, that is, Oracle sets the STATISTICS_LEVEL parameter to typical. To also record timed statistics, set the TIMED_STATISTICS parameter to true. Oracle records statistics in hundredths of seconds.
In addition to performance trends revealed by object level and timed statistics, also examine statistics that reveal information about specific transactions within your Real Application Clusters environment. Do this with utilities such as Oracle9i Statspack as described in the next section.
|
Note: Set |
| See Also:
Oracle9i Performance Methods for more information about using the |
The remainder of this chapter explains how to use Statspack in Real Application Clusters and how to analyze its statistics to assess performance trends as described under the following headings:
You can use Statspack for Real Application Clusters just as you would for single-instance Oracle databases. Statspack displays statistics that show performance trends over a period of time. It uses the following pages to display Real Application Clusters performance information:
Monitor the following statistics on these pages:
Most statistics such as counts, elapsed times, and wait times, are computed by Statspack. These statistics characterize the application workloads and profiles. Oracle computes these statistics in the following ways:
The first page of Statspack displays most of the load and profile data and the average Global Cache Service times per request, such as the time required to receive a current block. Statspack also displays the top wait events and their proportion to the total wait time. These statistics indicate the overhead associated with specific requests.
| See Also:
The |
To analyze your cluster database's performance and to identify any contention in Real Application Clusters, examine block transfer rates and the wait events and statistics as described under the following headings:
Analyze block transfers in Real Application Clusters to determine the cost of global processing and to quantify the resources required to maintain interinstance coherency. Do this by analyzing the statistics as described in the following sections. Use these procedures on an on-going basis to identify processing trends and optimize performance. The following statistics reveal Real Application Clusters-related performance characteristics:
Response times for cache-to-cache transfers are not bounded by I/O-related factors other than log writes. This is because Oracle writes data block modifications to the redo logs before blocks are transmitted to a remote instance. In other words, Real Application Clusters does not cause overhead in terms of disk I/O other than to perform physical I/O for cache replacement, checkpoints, and the reading of newly requested blocks. This behavior is identical to single-instance Oracle environments.
This section describes how to monitor Global Cache and Global Enqueue Service performance by identifying any contention as explained under the following topics:
Identify globally hot resources in each cache by examining the values for the following statistics:
Use the V$SESSION_WAIT view to identify objects that have performance issues. Columns P1 and P2 identify the file and block number of the object as in the following example queries:
SELECT P1 FILE_NUMBER, P2 BLOCK_NUMBER FROM V$SESSION_WAIT WHERE EVENT = 'BUFFER BUSY GLOBAL CR';
The output from this first query may look like this:
FILE_NUMBER BLOCK_NUMBER ----------- ------------ 12 3841
If you then issue the query:
SELECT OWNER,SEGMENT_NAME,SEGMENT_TYPE FROM DBA_EXTENTS WHERE FILE_ID = 12 AND 3841 BETWEEN BLOCK_ID AND BLOCK_ID+BLOCKS-1;
Then the output would be similar to:
OWNER SEGMENT_NAME SEGMENT_TYPE ---------- ---------------------------- --------------- SCOTT W_ID_I INDEX PARTITION
If there is contention, then index leaf blocks are usually the most contended blocks. To reduce contention on individual blocks, you can use a smaller block size for the index tablespace, or hash partitioning. These modifications distribute the load among more distinct blocks.
Examine Global Cache Service timings to determine whether the interconnect has latency problems. Do this by examining the statistic for:
Long latencies can be caused by:
The procedures you use to evaluate whether these types of performance issues are occurring in your Real Application Clusters database are platform-specific. On Solaris operating systems, for example, execute the following commands:
netstat -l netstat -s sar -c sar -q vmstat
If the wait event 'enqueue' is among the leading wait events in terms of wait time, then analyze the output from the V$ENQUEUE_STATS view to identify the enqueue with the highest wait time.
ALTER SEQUENCE statement. Ensure that the sequence uses the NOORDER keyword to avoid additional SQ enqueue contention.You can resolve TX enqueue performance issues by setting the value of the INITRANS parameter to be equal to the number of CPUs per node multiplied by the number of nodes in the cluster multiplied by 0.75. However, Oracle Corporation recommends that you avoid setting this parameter to be greater than 100. Therefore, you should also not set MAXTRANS to be greater than 100. If the value for either of these parameters is too high, then Oracle uses more space for the transaction layer block header and less is used for the data layer variable header. This can result in more I/O.
The following are undesirable statistics, or statistics for which the values should always be zero or near-zero.
Most events that show a high total time as reported in the dynamic performance views or in Statspack are actually normal. If response times increase and Statspack shows a high proportion of wait time for cluster accesses, then determine the cause of these waits. Statspack provides a breakdown of the wait events with the five highest values sorted by percentages. Specific statistics events that you should monitor are:
These events are associated with the initial access of particular data blocks by an instance. The duration of the wait is short and the completion of the wait is most likely followed by a read from disk. This is because the blocks have not been cached in any instances in the cluster database.
If these events are associated with high totals or high per-transaction wait times, then it is likely that data blocks are not cached in the local instance and that the blocks cannot be obtained from another instance which results in a disk read. At the same time, you may also observe sub-optimal buffer cache hit ratios.
These events are waited for when a block was used by an instance, transferred to another instance, and then requested again by the original instance. Processes waiting for these events are usually waiting for a block to be transferred from the instance that last modified it. If one instance requests cached data blocks from other instances, then it is normal that these events consume a greater proportion of the total wait time.
This event is waited for when an instance has requested a data block for a consistent read and the transferred block has not yet arrived at the requesting instance.
If global cache waits constitute a large proportion of the wait time as listed on the first page of your Statspack report, and if response times or throughput does not conform to your service level requirements, then check the Global Cache Service workload characteristics on the Cluster Statistics page of the Statspack report.
If the average Global Cache Service time per request is high, then it could be the result of contention, system loads, or network issues. System logs and operating system statistics may also indicate that a network link is congested, that packets are routed through the public network instead of the private interconnect, or that the sizes of the run queues are increasing.
In cases where CPU use is close to the maximum and processes are queuing for the CPU, raising the priorities of the Global Cache Service processes (LMSn) to have priority over other processes can significantly lower Global Cache Service times. Also consider reducing the number of processes on the database server, adding CPUs to the server, or adding nodes to the cluster database.
| See Also:
Oracle9i Real Application Clusters Administration for procedures to add nodes and instances to your Real Application Clusters database |
To estimate the use of the Global Cache Service relative to the number of buffer cache reads, or logical reads, divide the sum of Global Cache Service requests by the number of logical reads for a given statistics collection interval.
Oracle makes a Global Cache Service request whenever a user accesses a buffer cache to read or modify a data block and the block is not in the local cache. This results in a remote cache read, a disk read, or a change of access privileges. In other words, logical reads are a superset of Global Cache Service operations. The calculation is:
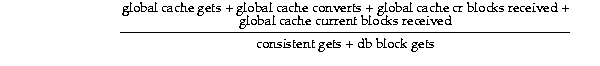
Some blocks may be very hot, or in other words, frequently requested by local and remote users. Sometimes a block transfer is delayed for a few milliseconds to permit local users to complete their work. The following ratio provides a rough estimate of how probable this is:

A ratio of more than 0.3 indicates a fairly hot data set. In such a case, closely analyze the blocks involved in busy waits. To do this, query columns such as NAME, TYPE, FORCED_READS, and FORCED_WRITES from the V$CACHE_TRANSFER view, or examine the CR_TRANSFERS and CURRENT_TRANSFERS columns in V$OBJ_STATS. Also examine the values shown for the "global cache busy", "buffer busy global cache", and "buffer busy global CR" statistics as described under the heading "Global Cache Service Wait Events".
If you discover a problem, then identify the object causing it, the instance that is accessing the object, and how the object is being accessed. If necessary, alleviate the contention by reducing:
As mentioned earlier, in single-instance Oracle databases and in Real Application Clusters, blocks are only written to disk for aging, cache replacement, or checkpoints. When a data block is replaced from the cache due to aging or when a checkpoint occurs and the block was previously changed in another instance but not written to disk, Oracle sends a message to notify the other instance that Oracle will write the data block to disk. This is called a fusion write, and the following ratio reveals the proportion of writes that Oracle manages in this way:

The larger this ratio is, the higher the number of written blocks that have been copied with previous changes in other instances. A large ratio can result from insufficiently sized caches or it can be because checkpoints have not occurred for some time. A large number can also indicate the proportion of the global working set that is composed of buffers written due to cache replacement or checkpointing. For example, 0.1 means that 10% of the buffers written to disk were globally dirty.
Note that a fusion write is not an additional write to disk. However, a fusion write requires messaging to coordinate the transfer with the other instance. Therefore, a fusion write is a subset of all physical writes incurred by an instance.
Use the V$CACHE_TRANSFER and V$FILE_CACHE_TRANSFER views to examine Real Application Clusters Statistics. The V$CACHE_TRANSFER view shows the types and classes of blocks that Oracle transfers over the interconnect on a per-object basis. Use the FORCED_READS and FORCED_WRITES columns to determine which types of objects your Real Application Clusters instances share. Values in the FORCED_WRITES column provide counts of how often a certain block type experiences a transfer out of a local buffer cache because the current version was requested by another instance.
Use the V$FILE_CACHE_TRANSFER view to identify files that experience cache transfers. For example, V$CACHE_TRANSFER has a NAME column showing the name of an object. Therefore, use this view to assess block transfers per object.
Even though the shared disk architecture eliminates forced disk writes, the V$CACHE_TRANSFER and V$FILE_CACHE_TRANSFER views may still show the number of block mode conversions per block class or object. However, values in the FORCED_WRITES column will be zero.
|
 Copyright © 1999, 2002 Oracle Corporation. All Rights Reserved. |
|

