Sun MPI 6.0 Software Programming and Reference Manual MPI 6.0 Software Programming and Reference Manual
|
| Sun MPI 6.0 Software Programming and Reference Manual
|
| C H A P T E R 2 |
|
Sun MPI Library |
This chapter describes the Sun MPI library:
|
Note - Sun MPI I/O is described separately, in Chapter 4. |
Sun MPI contains four types of libraries, which represent two categories.
For full information about linking to libraries, see Compiling and Linking.
This section gives a brief description of the routines in the Sun MPI library. All the Sun MPI routines are listed in Appendix A with brief descriptions and their C syntax. For detailed descriptions of individual routines, see the man pages or the MPI Standard. The routines are divided into these categories:
Point-to-point communication routines include the basic send and receive routines in both blocking and nonblocking forms and in four modes.
A blocking send blocks until its message buffer can be written with a new message.
A blocking receive blocks until the received message is in the receive buffer.
Nonblocking sends and receives differ from blocking sends and receives in that they return immediately and their completion must be waited or tested for. It is expected that eventually nonblocking send and receive calls will allow the overlap of communication and computation.
The four modes for MPI point-to-point communication are as follows:
Standard MPI communication is two-sided. To complete a transfer of information, both the sending and receiving processes must call appropriate functions. The operation proceeds in two stages, as shown in the following figure. 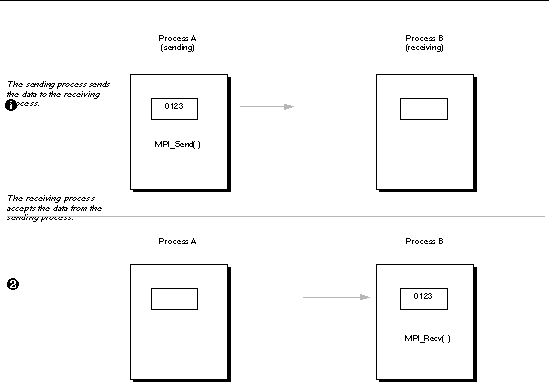
This form of communication requires regular synchronization between the sending and receiving processes. That synchronization can become complicated if the receiving process does not know which process is sending it the data it needs. One-sided communication was developed to solve this problem and to reduce the amount of synchronization required even when both sending and receiving processes know each other's identities.
In one-sided communication, a process opens a window in memory and exposes it to all processes that belong to a particular communicator, provided they reside on the same node. As long as that window is open, any process in the communicator and node can put data into it and get data out of it.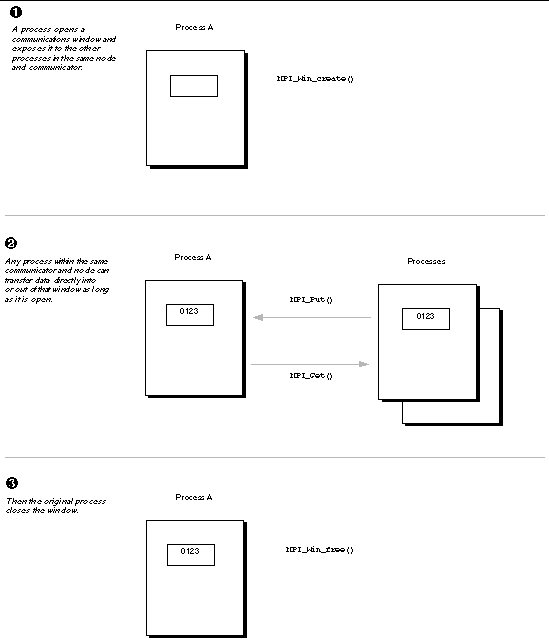
The put requires no complementary operation from the process that opened the window, and is equivalent to the combination of a send and receive operation in two-sided MPI communication.
The functions used to implement one-sided MPI communication fall into three categories and are summarized in TABLE 2-1. You can find their definitions in the MPI Standard. Also, Appendix A of this document provides syntax summaries.
Some special considerations apply to allocating memory for one-sided communications. For example:
Several one-sided communications routines support info keys. These keys, and their descriptions, are listed in TABLE 2-2.
Several one-sided communications routines support assertions. These assertions, and their descriptions, are listed in TABLE 2-3.
Collective communication routines are blocking routines that involve all processes in a communicator and, in most cases, an intercommunicator. Collective communication includes broadcasts and scatters, reductions and gathers, all-gathers and all-to-alls, scans, and a synchronizing barrier call.
Many of the collective communication calls have alternative vector forms, with which various amounts of data can be sent to or received from various processes. In addition, MPI_Alltoallw() accepts a database of individual datablocks.
The syntax and semantics of these routines are basically consistent with the point-to-point routines (upon which they are built), but there are restrictions to keep them from becoming too complex:
Several collectives can pass MPI_IN_PLACE as the value of send-buffer at the root. When they do, sendcount and sendtype are ignored, and the contribution of the root to the gathered vector is assumed to be already in the correct location in the receive bugger. The collectives are as follows:
Sometimes within an inner loop of a parallel computation, a communication with the same argument list is executed repeatedly. The communication can be slightly improved by using a persistent communication request, which reduces the overhead for communication between the process and the communication controller. A persistent request can be thought of as a communication port or half-channel.
Process topologies are associated with communicators; they are optional attributes that can be given to an intracommunicator (not to an intercommunicator).
Recall that processes in a group are ranked from 0 to n-1. This linear ranking often reflects nothing of the logical communication pattern of the processes, which may be, for instance, a two- or three-dimensional grid. The logical communication pattern is referred to as a virtual topology (separate and distinct from any hardware topology). In MPI, two types of virtual topologies can be created: Cartesian (grid) topology and graph topology.
You can use virtual topologies in your programs by taking physical processor organization into account to provide a ranking of processors that optimizes communication.
Name-publishing routines enable client applications to retrieve system-supplied port names. A server calls the MPI_Publish_name() function to publish the name of the service associated with a particular port name. A client application calls the MPI_Lookup_name(), passing it the published service name, and in return gets its associated port name. The server can also call the MPI_Unpublish_name() function to stop publishing names.
Sun's implementation of the MPI Standard does not provide a scope for the published names and does not allow a server to publish the same service name twice. The implementation consists of three routines:
Environmental inquiry routines are used for starting up and shutting down error-handling routines and timers.
Few MPI routines can be called before MPI_Init() or after MPI_Finalize(). Examples include MPI_Initialized() and MPI_Version(). MPI_Finalize() can be called only if there are no outstanding communications involving that process.
The set of errors handled by MPI depends upon the implementation. See Appendix C for tables listing the Sun MPI error classes.
Sun's implementation of the MPI Standard provides functions for packing and unpacking messages to be exchanged within an MPI implementation, and in the external32 format used to exchange messages between MPI implementations.
A distinguishing feature of the MPI Standard is that it includes a mechanism for creating separate worlds of communication, accomplished through communicators, groups, and contexts.
A communicator specifies a group of processes that will conduct communication operations within a specified context without affecting or being affected by operations occurring in other groups or contexts elsewhere in the program. A communicator also guarantees that, within any group and context, point-to-point and collective communication are isolated from each other.
A group is an ordered collection of processes. Each process has a rank in the group; the rank runs from 0 to n-1. A process can belong to more than one group; its rank in one group has nothing to do with its rank in any other group.
A context is the internal mechanism by which a communicator guarantees safe communication space to the group.
At program startup, two default communicators are defined:
The process group that corresponds to MPI_COMM_WORLD is not predefined, but can be accessed using MPI_COMM_GROUP. One MPI_COMM_SELF communicator is defined for each process, each of which has rank zero in its own communicator. For many programs, these are the only communicators needed.
Communicators are of two kinds: intracommunicators, which conduct operations within a given group of processes; and intercommunicators, which conduct operations between two groups of processes.
Communicators provide a caching mechanism, which allows an application to attach attributes to communicators. Attributes can be user data or any other kind of information.
New groups and new communicators are constructed from existing ones. Group constructor routines are local, and their execution does not require interprocessor communication. Communicator constructor routines are collective, and their execution can require interprocess communication.
You can also create an intercommunicator from two MPI processes that are connected by a socket. Use the MPI_Comm_join() function.
|
Note - Users who do not need any communicator other than the default MPI_COMM_WORLD communicator--that is, who do not need any sub- or supersets of processes--can plug in MPI_COMM_WORLD wherever a communicator argument is requested. In these circumstances, users can ignore this section and the associated routines. (These routines can be identified from the listing in
|
All Sun MPI communication routines have a data type argument. They can be primitive data types, such as integers or floating-point numbers, or they can be user-defined, derived data types that are specified in terms of primitive types.
Derived data types enable users to specify more general, mixed, and noncontiguous communication buffers, such as array sections and structures that contain combinations of primitive data types.
Fortran data types are listed in TABLE 2-5. Data types of Fortran used with the -r8 flag are listed in TABLE 2-6. C data types are listed in TABLE 2-7.
|
Pair of DOUBLE PRECISION variables[1] |
|
|
Pair of REALs* |
|
|
Pair of INTEGERs* |
|
|
Pair of REAL*8[2] |
|
|
Pair of REAL*4* |
|
|
Pair of int[3] |
|
|
float and int* |
|
|
double and int* |
|
|
long double and int* |
|
|
long and int* |
|
|
short and int* |
If you plan to launch a job that uses the MPI_Comm_spawn or MPI_Comm_spawn_multiple functions, you must first reserve the resources with the resource manager that will run the job. As explained in the mprun.1 man page and the Sun HPC ClusterTools Software User's Guide, you can reserve those resources by adding the -nr flag to the mprun command.
When you launch a job with the mprun command from within a resource manager, the number of processes allocated for that job are stored in the environment variable MPI_UNIVERSE_SIZE. It is the sum of the processes allocated with the mprun command's -np flag, and reserved with its -nr flag.
Although there are about 190 non-I/O routines in the Sun MPI library, you can write programs for a wide range of problems using only six routines, as described in TABLE 2-8.
This set of six routines includes the basic send and receive routines. Programs that depend heavily on collective communication might also include MPI_Bcast() and MPI_Reduce().
The functionality of these routines means you can have the benefit of parallel operations without having to learn the whole library at once. As you become more familiar with programming for message passing, you can start learning the more complex and esoteric routines and add them to your programs as needed.
See Appendix A for a complete list of Sun MPI routines.
Sun MPI provides extended Fortran support, as described in Section 10.2 of the MPI-2 Standard. In other words, it provides basic Fortran support, plus additional functions that specifically support Fortran 90:
Basic Fortran support provides the original Fortran bindings and an mpif.h file specified in the MPI-1 Standard. The mpif.h file is valid for both fixed- and free-source forms, as specified in the MPI-2 Standard.
The MPI interface is known to violate the Fortran standard in several ways, but it causes few problems for FORTRAN 77 programs. Violations of the standard can cause more significant problems for Fortran 90 programs, however, if you do not follow the guidelines recommended in the standard. If you are programming in Fortran, and particularly if you are using Fortran 90, you should consult Section 10.2 of the MPI-2 Standard for detailed information about basic Fortran support in an MPI implementation.
The Sun MPI library uses the TCP protocol to communicate over a variety of networks. MPI depends on TCP to ensure reliable, correct data flow. TCP's reliability compensates for unreliability in the underlying network, as the TCP retransmission algorithms handle any segments that are lost or corrupted. In most cases, this works well with good performance characteristics. However, when doing all-to-all and all-to-one communication over certain networks, a large number of TCP segments can be lost, resulting in poor performance.
You can compensate for this diminished performance over TCP in these ways:
When running the MPI library over TCP, nonfatal SIGPIPE signals can be generated. To handle them, the library sets the signal handler for SIGPIPE to ignore, overriding the default setting (terminate the process). In this way the MPI library can recover in certain situations. You should therefore avoid changing the SIGPIPE signal handler.
The Sun MPI Fortran and C++ bindings are implemented as wrappers on top of the C bindings. The profiling interface is implemented using weak symbols. This means a profiling library need contain only a profiled version of C bindings.
The SIGPIPEs can occur when a process first starts communicating over TCP. This happens because the MPI library creates connections over TCP only when processes actually communicate with one another. There are some unavoidable conditions where SIGPIPEs can be generated when two processes establish a connection. If you want to avoid any SIGPIPEs, set the environment variable MPI_FULLCONNINIT, which creates all connections during MPI_Init() and avoids any situations that might generate a SIGPIPE. For more information about environment variables, see Appendix B.
When you are linked to one of the thread-safe libraries, Sun MPI calls are thread safe, in accordance with basic tenets of thread safety for MPI mentioned in the MPI-2 specification. As a result:
Use MPI_Init_thread() in place of MPI_Init() to initialize the MPI execution environment with a predetermined level of thread support. Use the MPI_Is_thread_main() function to find out whether a thread is the one that called MPI_Init_thread().
Each thread within an MPI process can issue MPI calls; however, threads are not separately addressable. That is, the rank of a send or receive call identifies a process, not a thread, which means that no order is defined for the case in which two threads call MPI_Recv() with the same tag and communicator. Such threads are said to be in conflict.
If threads within the same application post conflicting communication calls, data races will result. You can prevent such data races by using distinct communicators or tags for each thread.
In general, adhere to these guidelines:
The following sections describe more specific guidelines that apply for some routines. They also include some general considerations for collective calls and communicator operations that you should be aware of.
In a program in which two or more threads call one of these routines, you must ensure that they are not waiting for the same request. Similarly, the same request cannot appear in the array of requests of multiple concurrent wait calls.
One thread must not cancel a request while that request is being serviced by another thread.
A call to MPI_Probe() or MPI_Iprobe() from one thread on a given communicator should not have a source rank and tags that match those of any other probes or receives on the same communicator. Otherwise, correct matching of message to probe call might not occur.
Collective calls are matched on a communicator according to the order in which the calls are issued at each processor. All the processes on a given communicator must make the same collective call. You can avoid the effects of this restriction on the threads on a given processor by using a different communicator for each thread.
No process that belongs to the communicator may omit making a particular collective call; that is, none should be left "dangling."
Each of the communicator (or intercommunicator) functions operates simultaneously with each of the noncommunicator functions, regardless of what the parameters are and whether the functions are on the same or different communicators. However, if you are using multiple instances of the same communicator function on the same communicator where all parameters are the same, it cannot be determined which threads belong to which resultant communicator. Therefore, when concurrent threads issue such calls, you must ensure that the calls are synchronized in such a way that threads in separate processes participating in the same communicator operation are grouped together. Do this either by using a different base communicator for each call or by making the calls in single-thread mode before actually using them within the separate threads.
Note also these special situations:
When an error occurs as a result of an MPI call, the handler might not run on the same thread as the thread that made the error-raising call. In other words, you cannot assume that the error handler will execute in the local context of the thread that made the error-raising call. The error handler can be executed by another thread on the same process, distinct from the one that returns the error code. Therefore, you cannot rely on local variables for error handling in threads; instead, use global variables from the process.
The Sun HPC ClusterTools software suite includes MPProf, a profiling tool to be used with applications that call Sun MPI library routines. When enabled, MPProf collects information about a program's message-passing activities in a set of intermediate files, one file per MPI process. Once the information is collected, you can invoke the MPProf command-line utility mpprof, which generates a report based on the profiling data stored in the intermediate files. You must enable MPProf before starting an MPI program. You do this by setting the environment variable MPI_PROFILE to 1.
If MPProf is enabled, it creates and initializes the intermediate files with header information when the program's MPI_Init call ends. It also creates an index file that contains a map of the intermediate files. mpprof uses this index file to find the intermediate files.
mpprof includes an interface for interacting with loadable protocol modules (loadable PMs). If an MPI program uses a loadable PM, this interface allows MPProf to collect profiling data that is specific to loadable PM activities.
An mpprof report contains the following classes of performance information:
You can control aspects of mpprof behavior with the following environment variables:
The Sun HPC ClusterTools software suite also provides a conversion utility, mpdump, which converts the data from each intermediate file into a raw (unevaluated) user-readable format. You can use the ASCII files generated by mpdump as input to a report generator of your choice.
Once you've enabled MPProf profiling by setting MPI_PROFILE to 1 (and run a job using mprun) you will find a file in your working directory of the form
mpprof.index.rm.jid
% mpprof mpprof.index.rm.jid
Further instructions for using mpprof and mpdump are provided in the Sun HPC ClusterTools Software User's Guide.
Sun MPI meets the profiling interface requirements described in Chapter 8 of the MPI-1 Standard. This means you can write your own profiling library or choose from a number of available profiling libraries, such as those in the multiprocessing environment (MPE) from Argonne National Laboratory. (See MPE: Extensions to the Library for more information.) The User's Guide for mpich, a Portable Implementation of MPI includes more detailed information about using profiling libraries.
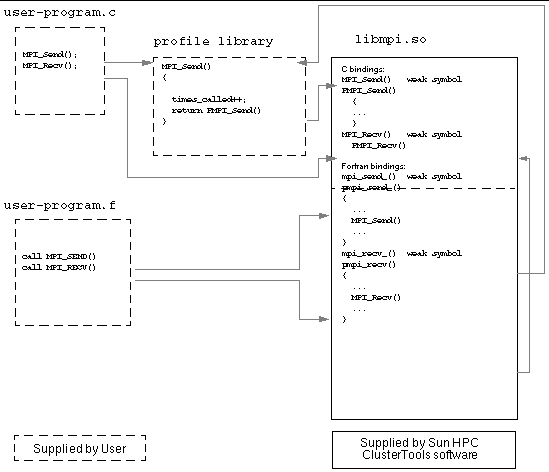
FIGURE 2-1 provides a generic illustration of how the software fits together. In this example, the user is linking against a profiling library that collects information on MPI_Send(). No profiling information is being collected for MPI_Recv().
C profiling interfaces are needed even for Fortran programs. If there is profiling for both the Fortran and C version of an MPI function, then a Fortran call will encounter both profilings.
Be sure you make the library dynamic. A static library can experience the linker problems described in Section 8.4.3 of the MPI 1.1 Standard.
For compiling the program, the user's link line would look like this:
# cc ..... -llibrary-name -lmpi |
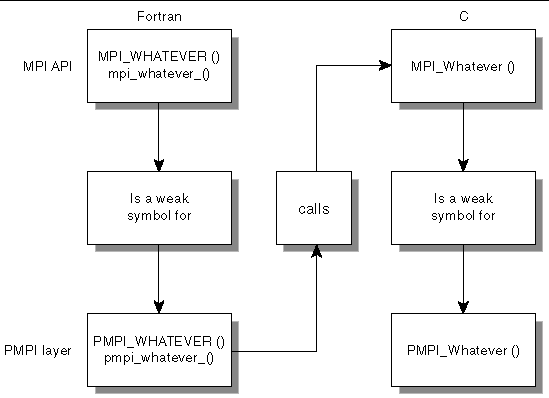
To clarify the layering of PMPI profiling, users need to understand the role of weak symbols. A weak symbol is such that, if a user defines the symbol, the user's definition is used. Otherwise, the associated function is used. The relation of weak symbols to associated functions is illustrated in FIGURE 2-2.
Although the Sun MPI library does not include or support the multiprocessing environment (MPE) available from Argonne National Laboratory (ANL), it is compatible with MPE. If you would like to use these extensions to the MPI library, see the following instructions for downloading them from ANL and building MPE yourself. Note that this procedure may change if ANL makes changes to MPE.
The MPE software is available from Argonne National Laboratory. The mpe.tar.gz file is about 240 Kbytes.
1. Use ftp to obtain the file.
ftp://ftp.mcs.anl.gov/pub/mpi/misc/mpe.tar.gz |
2. Use gunzip and tar to decompress the software.
# gunzip mpe.tar.gz # tar xvf mpe.tar |
3. Change your current working directory to the mpe directory, and execute configure with the arguments shown.
# cd mpe # configure -cc=cc -fc=f77 -opt=-I/opt/SUNWhpc/include |
# make |
|
Note - Sun MPI does not include the MPE error handlers. You must call the debug routines MPE_Errors_call_dbx_in_xterm() and MPE_Signals_call_debugger() yourself. |
Refer to the User's Guide for mpich, a Portable Implementation of MPI for information on how to use MPE. It is available at the Argonne National Laboratory web site:
| Sun MPI 6.0 Software Programming and Reference Manual
| 817-0085-10 |
Copyright © 2002, Sun Microsystems, Inc. All rights reserved.
