Sun HPC ClusterTools 5 Software User's Guide 5 Software User's Guide
|
| Sun HPC ClusterTools 5 Software User's Guide
|
| C H A P T E R 2 |
|
Fundamental Concepts |
This chapter summarizes a few basic concepts that you should understand to get the most out of Sun's HPC ClusterTools software. It contains the following sections:
High performance computing clusters[1] are groups of Sun symmetric multiprocessor (SMP) servers interconnected by any Sun-supported, TCP/IP-capable interconnect or by the Sun Fire Link high-speed interconnect. Each server in a cluster is called a node.
|
Note - A cluster can consist of a single Sun SMP server. However, to execute MPI jobs on even a single-node cluster, CRE must be running on that cluster. |
When using CRE, you can select the cluster and nodes on which your MPI programs will run, and how your processes will be distributed among them. For instructions, see Chapter 4, "See Running Programs With mprun."
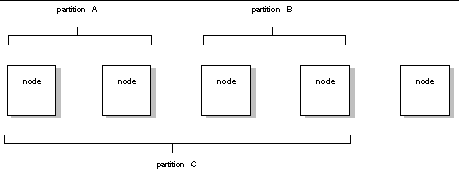
You can group a cluster's nodes into partitions. Partitions let you run different jobs simultaneously on different subsets of the cluster. You can also use partitions to create groups nodes of nodes with similar characteristics such as memory size, CPU count, or I/O support, so you can target jobs that benefit from those characteristics.
|
Note - The CPUs in the Sun Fire line of servers can be configured into "logical nodes," called domains. You can also group these domains into CRE partitions. |
You can define multiple partitions within a cluster.
Partitions do not have to include every node in the cluster. Nodes that are not included in any partition are called independent or free-floating nodes.
A single node can be included in more than one partition. However, two partitions with overlapping nodes cannot run jobs simultaneously. And only one of them can be enabled at a time. In the example above, partitions A and B can run jobs simultaneously with each other, but not with partition C.
A job can run only on a partition that has been enabled. Normally, the system administrator who manages the cluster enables and disables partitions (for more information, see the Sun HPC ClusterTools Software Administrator's Guide).
To find out which partitions are currently enabled, use the -P option to the mpinfo command, as described in How to Display Information About All Partitions (-P).
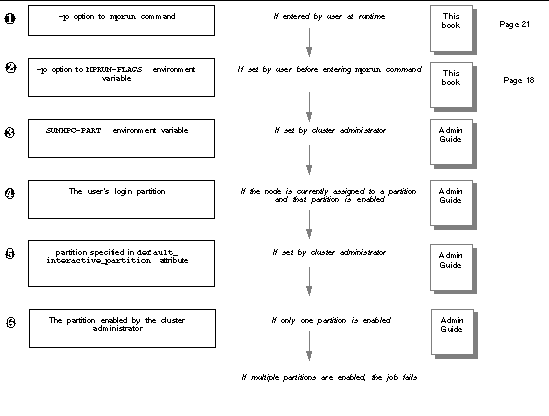
If only one partition is enabled, all jobs must run on that partition. If multiple partitions are enabled, where your particular job runs depends upon which environment variables the cluster administrator set and which options to the mprun command you entered. To determine the partition, CRE steps through the criteria shown in FIGURE 2-1, in order.
CRE load-balances programs when more CPUs are available than are required for a job. When you issue the mprun command to start a job, CRE first determines what criteria (if any) you have specified for the node or nodes on which the program is to run. It then determines which nodes within the partition meet these criteria. If more nodes meet the criteria than are required to run your program, CRE starts the program on the node or nodes that are least loaded. It examines the one-minute load averages of the nodes and ranks them accordingly.
This load-balancing mechanism ensures that your program's execution will not be unnecessarily delayed because it happened to be placed on a heavily loaded node. It also ensures that some nodes do not sit idle while other nodes are heavily loaded, thereby keeping overall throughput of the partition as high as possible.
When a serial program executes on a Sun HPC cluster, it becomes a Solaris process with a Solaris process ID, or pid. When CRE executes a distributed message-passing program it spawns multiple Solaris processes, each with its own pid.
CRE allows you to control several aspects of jobs and process execution, such as:
For tasks and instructions, see Chapter 4.
CRE assigns a job ID, or jid, to a program. In an MPI job, the jid applies to the overall job. Many CRE commands take jids as arguments. CRE provides a variety of information about jobs. To find out how to obtain that information, see Chapter 7.
As described in Chapter 1, the ClusterTools 5 environment provides close integration between CRE and three different DRM systems:
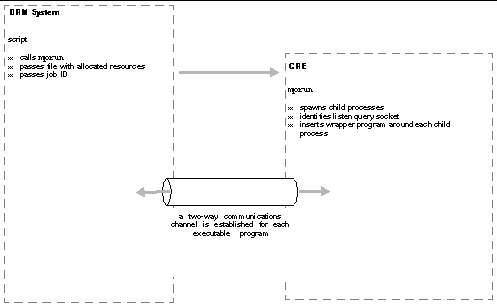
The integration process is similar for all three, with some individual differences. The DRM system, whether SGE, LSF, or PBS, launches the job through a script. The script calls mprun, and passes it a host file of the resources that have been allocated for the job, plus the job ID assigned by the DRM system.
The CRE environment continues to perform most of its normal parallel-processing actions, but its child processes do not fork any executable programs. Instead, each child process identifies a communications channel (specifically, a listen query socket) through which it can be monitored by the CRE environment while running in the DRM system.
You can also invoke a similar process interactively, without a script. Instructions for script-based and interactive job launching are provided in Chapter 5.
The exact instructions vary from one resource manager to another, and are affected by CRE's configuration, but they all follow these general guidelines:
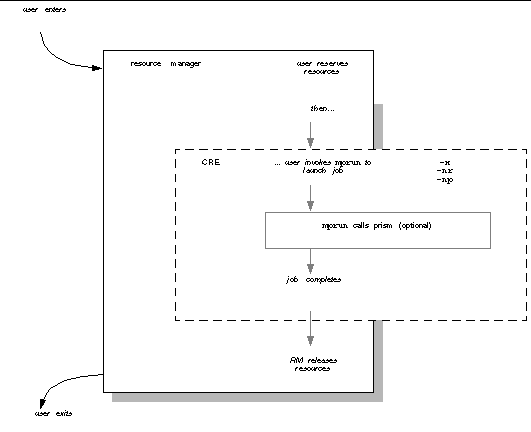
1. You can launch the job either interactively or through a script. Instructions for both are provided in Chapter 5 and the following man pages:
2. Enter the DRM processing environment before launching jobs with mprun.
3. Reserve resources for the parallel job and set other job control parameters from within their resource manager.
4. Invoke the mprun command with the applicable resource manager flags. Those flags are described in Chapter 5 and the mprun(1) manpage.
Here is a diagram that summarizes the user interaction:
If you are using a Distributed Resource Manager (DRM) such as Sun Grid Engine, PBS, or LSF for resource management, all Sun HPC ClusterTools jobs are handled by the DRM's Batch system. Consequently, Sun HPC ClusterTools job submission involves the following:
For further information about using DRMs with CRE, see the man pages sge_cre.1, pbs_cre.1, and lsf_cre.1.
is a completely different technology used for high availability (HA) applications.
| Sun HPC ClusterTools 5 Software User's Guide
| 817-0084-10 |
Copyright © 2003, Sun Microsystems, Inc. All rights reserved.