| Oracle® Spatial User's Guide and Reference 10g Release 1 (10.1) Part Number B10826-01 |
|






|
View PDF |
| Oracle® Spatial User's Guide and Reference 10g Release 1 (10.1) Part Number B10826-01 |
|
|
View PDF |
After you have loaded spatial data (discussed in Chapter 3), you should create a spatial index on it to enable efficient query performance using the data. This chapter describes how to:
Create a spatial index (see Section 4.1)
Query spatial data efficiently, based on an understanding of the Oracle Spatial query model and primary and secondary filtering (see Section 4.2)
Once data has been loaded into the spatial tables through either bulk or transactional loading, a spatial index must be created on the tables for efficient access to the data. Although each spatial index can be an R-tree index or a quadtree index, you are strongly encouraged to use R-tree indexes and to avoid using quadtree indexes. Almost all information about quadtree indexing has been removed from this guide and placed in a separate guide, Oracle Spatial Quadtree Indexing, which is available only through the Oracle Technology Network.
If the index creation does not complete for any reason, the index is invalid and must be deleted with the DROP INDEX <index_name> [FORCE] statement.
If you create a spatial index without specifying any quadtree-specific parameters, an R-tree index is created. For example, the following statement creates a spatial R-tree index named territory_idx using default values for parameters that apply to R-tree indexes:
CREATE INDEX territory_idx ON territories (territory_geom) INDEXTYPE IS MDSYS.SPATIAL_INDEX;
For detailed information about options for creating a spatial index, see the documentation for the CREATE INDEX statement in Chapter 10.
R-tree indexes can be built on two, three, or four dimensions of data. The default number of dimensions is two, but if the data has more than two dimensions, you can use the sdo_indx_dims parameter keyword to specify the number of dimensions on which to build the index. However, if a spatial index has been built on more than two dimensions of a layer, the only spatial operator that can be used against that layer is SDO_FILTER (the primary filter or index-only query), which considers all dimensions. The SDO_RELATE, SDO_NN, and SDO_WITHIN_DISTANCE operators are disabled if the index has been built on more than two dimensions.
If the rollback segment is not large enough, an attempt to create an R-tree index will fail. The rollback segment should be 100*n bytes, where n is the number of rows of data to be indexed. For example, if the table contains 1 million (1,000,000) rows, the rollback segment size should be 100,000,000 (100 million bytes).
To ensure an adequate rollback segment, or if you have tried to create an R-tree index and received an error that a rollback segment cannot be extended, review (or have a DBA review) the size and structure of the rollback segments. Create a public rollback segment of the appropriate size, and place that rollback segment online. In addition, ensure that any small inappropriate rollback segments are placed offline during large spatial index operations. For information about performing these operations on a rollback segment, see Oracle Database Administrator's Guide.
The system parameter SORT_AREA_SIZE affects the amount of time required to create the index. The SORT_AREA_SIZE value is the maximum amount, in bytes, of memory to use for a sort operation. The optimal value depends on the database size, but a good guideline is to make it at least 1 million bytes when you create an R-tree index. To change the SORT_AREA_SIZE value, use the ALTER SESSION statement. For example, to change the value to 20 million bytes:
ALTER SESSION SET SORT_AREA_SIZE = 20000000;
The tablespace specified with the tablespace keyword in the CREATE INDEX statement (or the default tablespace if the tablespace keyword is not specified) is used to hold both the index data table and some transient tables that are created for internal computations.
The R-tree index data table requires approximately 70*n bytes (where n is the number of rows in the table).
The transient tables require up to approximately 200*n bytes (where n is the number of rows in the table); however, this space is freed up after the R-tree index is created.
For large tables (over 1 million rows), a temporary tablespace may be needed to perform internal sorting operations. The recommended size for this temporary tablespace is 100*n bytes, where n is the number of rows in the table.
To take full advantage of Spatial features, you must index geodetic data using a geodetic R-tree index. Geodetic data consists of geometries that have geodetic SDO_SRID values, reflecting the fact that they are based on a geodetic coordinate system (such as using longitude and latitude) as opposed to a flat or projected plane coordinate system. (Chapter 6 explains coordinate systems and related concepts.) A geodetic index is one that provides the full range of Spatial features with geodetic data. Thus, it is highly recommended that you use a geodetic index with geodetic data.
Only R-tree indexes can be geodetic indexes. Quadtree indexes cannot be geodetic indexes. If you create an R-tree or quadtree index and specify 'geodetic=false' in the CREATE INDEX statement, the index is non-geodetic. The following notes and restrictions apply to non-geodetic indexes:
If you create a non-geodetic index on geodetic data, you cannot use the unit parameter with the SDO_WITHIN_DISTANCE operator or the SDO_NN_DISTANCE ancillary operator with the SDO_NN operator.
If you create a non-geodetic index on projected data that has a projected SDO_SRID value, you can use the full range of Spatial features.
If you create a non-geodetic index on projected data that has a null SDO_SRID value, you cannot use the unit parameter with the SDO_WITHIN_DISTANCE operator or the SDO_NN_DISTANCE ancillary operator with the SDO_NN operator.
For additional information, see the Usage Notes about the geodetic parameter for the CREATE INDEX statement in Chapter 10.
If a Spatial index already exists and you need to insert many rows into the spatial geometry table, you can improve the performance of the insert operations by deferring spatial indexing, inserting the rows, and synchronizing the index. Follow these steps:
Modify the spatial index to set the index status to deferred. For example:
ALTER INDEX cola_spatial_idx PARAMETERS ('index_status=deferred');
Insert the new rows, using the appropriate INSERT statements.
Synchronize the index, specifying the sdo_batch_size keyword with a fairly large value. For example:
ALTER INDEX cola_spatial_idx PARAMETERS ('index_status=synchronize
sdo_batch_size=500');
The best value for the sdo_batch_size keyword is probably from 100 to 1000.
See the section about the ALTER INDEX statement in Chapter 10 for more information about the index_status and sdo_batch_size keywords.
When you create or rebuild a spatial index, you can ensure that all geometries that are in the table or that are inserted later are of a specified geometry type. To constrain the data to a geometry type in this way, use the layer_gtype keyword in the PARAMETERS clause of the CREATE INDEX or ALTER INDEX REBUILD statement, and specify a value from the Geometry Type column of Table 2-1 in Section 2.2.1. For example, to constrain spatial data in a layer to polygons:
CREATE INDEX cola_spatial_idx
ON cola_markets(shape)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
PARAMETERS ('layer_gtype=POLYGON');
The geometry types in Table 2-1 are considered as a hierarchy when data is checked:
The MULTI forms include the regular form also. For example, specifying 'layer_gtype=MULTIPOINT' allows the layer to include both POINT and MULTIPOINT geometries.
COLLECTION allows the layer to include all types of geometries.
You can create a spatial index on a table that is not in your schema. Assume that user B wants to create a spatial index on column GEOMETRY in table T1 under user A's schema. User B must perform the following steps:
Connect as user A (or have user A connect) and execute the following statement:
GRANT select, index on T1 to B;
Connect as user B and execute a statement such as the following:
CREATE INDEX t1_spatial_idx on A.T1(geometry) INDEXTYPE IS mdsys.spatial_index;
You can create a partitioned spatial index on a partitioned table. This section describes usage considerations specific to Oracle Spatial. For a detailed explanation of partitioned tables and partitioned indexes, see Oracle Database Administrator's Guide.
A partitioned spatial index can provide the following benefits:
Reduced response times for long-running queries, because partitioning reduces disk I/O operations
Reduced response times for concurrent queries, because I/O operations run concurrently on each partition
Easier index maintenance, because of partition-level create and rebuild operations
Indexes on partitions can be rebuilt without affecting the queries on other partitions, and storage parameters for each local index can be changed independent of other partitions.
Parallel query on multiple partition searching
The degree of parallelism is the value from the DEGREE column in the row for the index in the USER_INDEXES view (that is, the value specified or defaulted for the PARALLEL keyword with the CREATE INDEX, ALTER INDEX, or ALTER INDEX REBUILD statement).
Improved query processing in multiprocessor system environments
In a multiprocessor system environment, if a spatial operator is invoked on a table with partitioned spatial index and if multiple partitions are involved in the query, multiple processors can be used to evaluate the query. The number of processors used is determined by the degree of parallelism and the number of partitions used in evaluating the query.
The following restrictions apply to spatial index partitioning:
The partition key for spatial tables must be a scalar value, and must not be a spatial column.
Only range partitioning is supported on the underlying table. Hash and composite partitioning are not currently supported for partitioned spatial indexes.
To create a partitioned spatial index, you must specify the LOCAL keyword. For example:
CREATE INDEX counties_idx ON counties(geometry) INDEXTYPE IS MDSYS.SPATIAL_INDEX LOCAL;
In this example, the default values are used for the number and placement of index partitions, namely:
Index partitioning is based on the underlying table partitioning. For each table partition, a corresponding index partition is created.
Each index partition is placed in the default tablespace.
If you do specify parameters for individual partitions, the following considerations apply:
The storage characteristics for each partition can be the same or different for each partition. If they are different, it may enable parallel I/O (if the tablespaces are on different disks) and may improve performance.
The sdo_indx_dims value must be the same for all partitions.
The layer_gtype parameter value (see Section 4.1.4) used for each partition may be different.
To override the default partitioning values, use a CREATE INDEX statement with the following general format:
CREATE INDEX <indexname> ON <table>(<column>)
INDEXTYPE IS MDSYS.SPATIAL_INDEX
[PARAMETERS ('<spatial-params>, <storage-params>')] LOCAL
[( PARTITION <index_partition>
PARAMETERS ('<spatial-params>, <storage-params>')
[, PARTITION <index_partition>
PARAMETERS ('<spatial-params>, <storage-params>')]
)]
Queries can operate on partitioned tables to perform the query on only one partition. For example:
SELECT * FROM counties PARTITION(p1)
WHERE ...<some-spatial-predicate>;
Querying on a selected partition may speed up the query and also improve overall throughput when multiple queries operate on different partitions concurrently.
When queries use a partitioned spatial index, the semantics (meaning or behavior) of spatial operators and functions is the same with partitioned and nonpartitioned indexes, except in the case of SDO_NN (nearest neighbor). With SDO_NN, the requested number of geometries is returned for each partition that is affected by the query. For example, if you request the 5 closest restaurants to a point and the spatial index has 4 partitions, SDO_NN returns up to 20 (5*4) geometries. In this case, you must use the ROWNUM pseudocolumn (here, WHERE ROWNUM <=5) to return the 5 closest restaurants. See the description of the SDO_NN operator in Chapter 12 for more information.
You can use the ALTER TABLE statement with the EXCHANGE PARTITION ... INCLUDING INDEXES clause to exchange a spatial table partition and its index partition with a corresponding table and its index. For information about exchanging partitions, see the description of the ALTER TABLE statement in the Oracle Database SQL Reference.
This feature can help you to operate more efficiently in a number of situations, such as:
Bringing data into a partitioned table and avoiding the cost of index re-creation.
Managing and creating partitioned indexes. For example, the data could be divided into multiple tables. The index for each table could be built one after the other to minimize the memory and tablespace resources needed during index creation. Alternately, the indexes could be created in parallel in multiple sessions. The tables (along with the indexes) could then be exchanged with the partitions of the original data table.
Managing offline insert operations. New data can be stored in a temporary table and periodically exchanged with a new partition (for example, in a database with historical data).
To exchange partitions including indexes with spatial data and indexes, the two spatial indexes (one on the partition, the other on the table) must be of compatible types. Specifically:
Both indexes must have the same dimensionality (sdo_indx_dims value).
Both indexes must be either geodetic or non-geodetic. (Geodetic and non-geodetic indexes are explained in Section 4.1.2.)
Neither index can have a status of deferred updates. (Deferred update status is set by specifying 'index_status=deferred' with the ALTER INDEX statement, as described in Chapter 10.)
If the indexes are not compatible, an error is raised. The table data is exchanged, but the indexes are not exchanged and the indexes are marked as failed. To use the indexes, you must rebuild them.
If you use the Export utility to export tables with spatial data, the behavior of the operation depends on whether or not the spatial data has been spatially indexed:
If the spatial data has not been spatially indexed, the table data is exported. However, you must update the USER_SDO_GEOM_METADATA view with the appropriate information on the target system.
If the spatial data has been spatially indexed, the table data is exported, the appropriate information is inserted into the USER_SDO_GEOM_METADATA view on the target system, and the spatial index is built on the target system. However, if the insertion into the USER_SDO_GEOM_METADATA view fails (for example, if there is already a USER_SDO_GEOM_METADATA entry for the spatial layer), the spatial index is not built.
If you use the Import utility to import data that has been spatially indexed, if the index on the exported data was created with a TABLESPACE clause and if the specified tablespace does not exist in the database at import time, the index is not built. (This is different from the behavior with other Oracle indexes, where the index is created in the user's default tablespace if the tablespace specified for the original index does not exist at import time.)
For information about using the Export and Import utilities, see Oracle Database Utilities.
This section describes how the structures of a Spatial layer are used to resolve spatial queries and spatial joins.
Spatial uses a two-tier query model with primary and secondary filter operations to resolve spatial queries and spatial joins, as explained in Section 1.6. The term two-tier indicates that two distinct operations are performed to resolve queries. If both operations are performed, the exact result set is returned.
You cannot append a database link (dblink) name to the name of a spatial table in a query if a spatial index is defined on that table.
If a spatial index is created in a database that was created using the UTF8 character set, spatial queries that use the spatial index will fail if the system parameter NLS_LENGTH_SEMANTICS is set to CHAR. For spatial queries to succeed in this case, the NLS_LENGTH_SEMANTICS parameter must be set to BYTE (its default value).
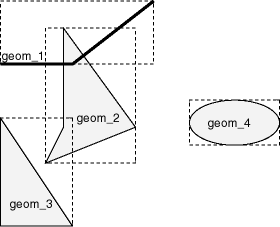
In a spatial R-tree index, each geometry is represented by its minimum bounding rectangle (MBR), as explained in Section 1.7.1. Consider the following layer containing several objects in Figure 4-1. Each object is labeled with its geometry name (geom_1 for the line string, geom_2 for the four-sided polygon, geom_3 for the triangular polygon, and geom_4 for the ellipse), and the MBR around each object is represented by a dashed line.
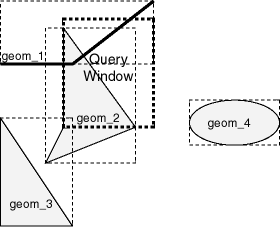
A typical spatial query is to request all objects that lie within a query window, that is, a defined fence or window. A dynamic query window refers to a rectangular area that is not defined in the database, but that must be defined before it is used. Figure 4-2 shows the same geometries as in Figure 4-1, but adds a query window represented by the heavy dotted-line box.
In Figure 4-2, the query window covers parts of geometries geom_1 and geom_2, as well as part of the MBR for geom_3 but none of the actual geom_3 geometry. The query window does not cover any part of the geom_4 geometry or its query window.
The SDO_FILTER operator, described in Chapter 12, implements the primary filter portion of the two-step process involved in the Oracle Spatial query processing model. The primary filter uses the index data to determine only if a set of candidate object pairs may interact. Specifically, the primary filter checks to see if the MBRs of the candidate objects interact, not whether the objects themselves interact. The SDO_FILTER operator syntax is as follows:
SDO_FILTER(geometry1 SDO_GEOMETRY, geometry2 SDO_GEOMETRY)
In the preceding syntax:
geometry1 is a column of type SDO_GEOMETRY in a table. This column must be spatially indexed.
geometry2 is an object of type SDO_GEOMETRY. This object may or may not come from a table. If it comes from a table, it may or may not be spatially indexed.
The following examples perform a primary filter operation only (with no secondary filter operation). They will return all the geometries shown in Figure 4-2 that have an MBR that interacts with the query window. The result of the following examples are geometries geom_1, geom_2, and geom_3.
Example 4-1 performs a primary filter operation without inserting the query window into a table. The window will be indexed in memory and performance will be very good.
Example 4-1 Primary Filter with a Temporary Query Window
SELECT A.Feature_ID FROM TARGET A
WHERE sdo_filter(A.shape, SDO_geometry(2003,NULL,NULL,
SDO_elem_info_array(1,1003,3),
SDO_ordinate_array(x1,y1, x2,y2))
) = 'TRUE';
In Example 4-1, (x1,y1) and (x2,y2) are the lower-left and upper-right corners of the query window.
In Example 4-2, a transient instance of type SDO_GEOMETRY was constructed for the query window instead of specifying the window parameters in the query itself.
Example 4-2 Primary Filter with a Transient Instance of the Query Window
SELECT A.Feature_ID FROM TARGET A WHERE sdo_filter(A.shape, :theWindow) = 'TRUE';
Example 4-3 assumes the query window was inserted into a table called WINDOWS, with an ID of WINS_1.
Example 4-3 Primary Filter with a Stored Query Window
SELECT A.Feature_ID FROM TARGET A, WINDOWS B WHERE B.ID = 'WINS_1' AND sdo_filter(A.shape, B.shape) = 'TRUE';
If the B.SHAPE column is not spatially indexed, the SDO_FILTER operator indexes the query window in memory and performance is very good.
If the B.SHAPE column is spatially indexed with the same SDO_LEVEL value as the A.SHAPE column, the SDO_FILTER operator reuses the existing index, and performance is very good or better.
If the B.SHAPE column is spatially indexed with a different SDO_LEVEL value than the A.SHAPE column, the SDO_FILTER operator reindexes B.SHAPE in the same way as if there were no index on the column originally, and then performance is very good.
The SDO_RELATE operator, described in Chapter 12, performs both the primary and secondary filter stages when processing a query. The secondary filter ensures that only candidate objects that actually interact are selected. This operator can be used only if a spatial index has been created on two dimensions of data. The syntax of the SDO_RELATE operator is as follows:
SDO_RELATE(geometry1 SDO_GEOMETRY,
geometry2 SDO_GEOMETRY,
param VARCHAR2)
In the preceding syntax:
geometry1 is a column of type SDO_GEOMETRY in a table. This column must be spatially indexed.
geometry2 is an object of type SDO_GEOMETRY. This object may or may not come from a table. If it comes from a table, it may or may not be spatially indexed.
param is a quoted string with the mask keyword and a valid mask value, as explained in the documentation for the SDO_RELATE operator in Chapter 12.
The following examples perform both primary and secondary filter operations. They return all the geometries in Figure 4-2 that lie within or overlap the query window. The result of these examples is objects geom_1 and geom_2.
Example 4-4 performs both primary and secondary filter operations without inserting the query window into a table. The window will be indexed in memory and performance will be very good.
Example 4-4 Secondary Filter Using a Temporary Query Window
SELECT A.Feature_ID FROM TARGET A
WHERE sdo_relate(A.shape, SDO_geometry(2003,NULL,NULL,
SDO_elem_info_array(1,1003,3),
SDO_ordinate_array(x1,y1, x2,y2)),
'mask=anyinteract') = 'TRUE';
In Example 4-4, (x1,y1) and (x2,y2) are the lower-left and upper-right corners of the query window.
Example 4-5 assumes the query window was inserted into a table called WINDOWS, with an ID value of WINS_1.
Example 4-5 Secondary Filter Using a Stored Query Window
SELECT A.Feature_ID FROM TARGET A, WINDOWS B
WHERE B.ID = 'WINS_1' AND
sdo_relate(A.shape, B.shape,
'mask=anyinteract') = 'TRUE';
If the B.SHAPE column is not spatially indexed, the SDO_RELATE operator indexes the query window in memory and performance is very good.
If the B.SHAPE column is spatially indexed with the same SDO_LEVEL value as the A.SHAPE column, the SDO_RELATE operator reuses the existing index, and performance is very good or better.
If the B.SHAPE column is spatially indexed with a different SDO_LEVEL value than the A.SHAPE column, the SDO_RELATE operator reindexes B.SHAPE in the same way as if there were no index on the column originally, and then performance is very good.
The SDO_WITHIN_DISTANCE operator, described in Chapter 12, is used to determine the set of objects in a table that are within n distance units from a reference object. This operator can be used only if a spatial index has been created on two dimensions of data. The reference object may be a transient or persistent instance of SDO_GEOMETRY (such as a temporary query window or a permanent geometry stored in the database). The syntax of the operator is as follows:
SDO_WITHIN_DISTANCE(geometry1 SDO_GEOMETRY,
aGeom SDO_GEOMETRY,
params VARCHAR2);
In the preceding syntax:
geometry1 is a column of type SDO_GEOMETRY in a table. This column must be spatially indexed.
aGeom is an instance of type SDO_GEOMETRY.
params is a quoted string of keyword value pairs that determines the behavior of the operator. See the SDO_WITHIN_DISTANCE operator in Chapter 12 for a list of parameters.
The following example selects any objects within 1.35 distance units from the query window:
SELECT A.Feature_ID FROM TARGET A WHERE SDO_WITHIN_DISTANCE( A.shape, :theWindow, 'distance=1.35') = 'TRUE';
The distance units are based on the geometry coordinate system in use. The distance units are those specified in the UNIT field of the well-known text (WKT) associated with the coordinate system (in the WKTEXT column of the MDSYS.CS_SRS table, as explained in Section 6.4.1.1). If you are using a geodetic coordinate system, the units are meters. If no coordinate system is used, the units are the same as for the stored data.
The SDO_WITHIN_DISTANCE operator is not suitable for performing spatial joins. That is, a query such as Find all parks that are within 10 distance units from coastlines will not be processed as an index-based spatial join of the COASTLINES and PARKS tables. Instead, it will be processed as a nested loop query in which each COASTLINES instance is in turn a reference object that is buffered, indexed, and evaluated against the PARKS table. Thus, the SDO_WITHIN_DISTANCE operation is performed n times if there are n rows in the COASTLINES table.
For non-geodetic data, there is an efficient way to accomplish a spatial join that involves buffering all geometries of a layer. This method does not use the SDO_WITHIN_DISTANCE operator. First, create a new table COSINE_BUFS as follows:
CREATE TABLE cosine_bufs UNRECOVERABLE AS
SELECT SDO_BUFFER (A.SHAPE, B.DIMINFO, 1.35)
FROM COSINE A, USER_SDO_GEOM_METADATA B
WHERE TABLE_NAME='COSINES' AND COLUMN_NAME='SHAPE';
Next, create a spatial index on the SHAPE column of COSINE_BUFS. Then you can perform the following query:
SELECT a.gid, b.gid FROM parks a, cosine_bufs b, TABLE(SDO_JOIN('PARKS', 'SHAPE', 'COSINE_BUFS', 'SHAPE', 'mask=ANYINTERACT')) c WHERE c.rowid1 = a.rowid AND c.rowid2 = b.rowid;
The SDO_NN operator, described in Chapter 12, is used to identify the nearest neighbors for a geometry. This operator can be used only if a spatial index has been created on two dimensions of data. The syntax of the operator is as follows:
SDO_NN(geometry1 SDO_GEOMETRY,
geometry2 SDO_GEOMETRY,
param VARCHAR2
[, number NUMBER]);
In the preceding syntax:
geometry1 is a column of type SDO_GEOMETRY in a table. This column must be spatially indexed.
geometry2 is an instance of type SDO_GEOMETRY.
param is a quoted string of a keyword value pair that determines how many nearest neighbor geometries are returned by the operator. See the SDO_NN operator in Chapter 12 for information about this parameter.
number is the same number used in the call to SDO_NN_DISTANCE. Use this only if the SDO_NN_DISTANCE ancillary operator is included in the call to SDO_NN. See the SDO_NN operator in Chapter 12 for information about this parameter.
The following example finds the two objects from the SHAPE column in the COLA_MARKETS table that are closest to a specified point (10,7). (Note the use of the optimizer hint in the SELECT statement, as explained in the Usage Notes for the SDO_NN operator in Chapter 12.)
SELECT /*+ INDEX(cola_markets cola_spatial_idx) */ c.mkt_id, c.name FROM cola_markets c WHERE SDO_NN(c.shape, SDO_geometry(2001, NULL, SDO_point_type(10,7,NULL), NULL, NULL), 'sdo_num_res=2') = 'TRUE';
Spatial also supplies functions for determining relationships between geometries, finding information about single geometries, changing geometries, and combining geometries. These functions all take into account two dimensions of source data. If the output value of these functions is a geometry, the resulting geometry will have the same dimensionality as the input geometry, but only the first two dimensions will accurately reflect the result of the operation.
A spatial join is the same as a regular join except that the predicate involves a spatial operator. In Spatial, a spatial join takes place when you compare all geometries of one layer to all geometries of another layer. This is unlike a query window, which compares a single geometry to all geometries of a layer.
Spatial joins can be used to answer questions such as Which highways cross national parks?
The following table structures illustrate how the join would be accomplished for this example:
PARKS( GID VARCHAR2(32), SHAPE SDO_GEOMETRY) HIGHWAYS( GID VARCHAR2(32), SHAPE SDO_GEOMETRY)
To perform a spatial join, use the SDO_JOIN operator, which is described in Chapter 12. The following spatial join query, to list the GID column values of highways and parks where a highway interacts with a park, performs a primary filter operation only ('mask=FILTER'), and thus it returns only approximate results:
SELECT a.gid, b.gid FROM parks a, highways b, TABLE(SDO_JOIN('PARKS', 'SHAPE', 'HIGHWAYS', 'SHAPE', 'mask=FILTER')) c WHERE c.rowid1 = a.rowid AND c.rowid2 = b.rowid;
The following spatial join query requests the same information as in the preceding example, but it performs both primary and secondary filter operations ('mask=ANYINTERACT'), and thus it returns exact results:
SELECT a.gid, b.gid FROM parks a, highways b,
TABLE(SDO_JOIN('PARKS', 'SHAPE', 'HIGHWAYS', 'SHAPE',
'mask=ANYINTERACT')) c
WHERE c.rowid1 = a.rowid AND c.rowid2 = b.rowid;
You can invoke spatial operators on an indexed table that is not in your schema. Assume that user A has a spatial table T1 (with index table IDX_TAB1) with a spatial index defined, that user B has a spatial table T2 (with index table IDX_TAB2) with a spatial index defined, and that user C wants to invoke operators on tables in one or both of the other schemas.
If user C wants to invoke an operator only on T1, user C must perform the following steps:
Connect as user A and execute the following statements:
GRANT select on T1 to C; GRANT select on idx_tab1 to C;
Connect as user C and execute a statement such as the following:
SELECT a.gid FROM T1 a WHERE sdo_filter(a.geometry, :theGeometry) = 'TRUE';
If user C wants to invoke an operator on both T1 and T2, user C must perform the following steps:
Connect as user A and execute the following statements:
GRANT select on T1 to C; GRANT select on idx_tab1 to C;
Connect as user B and execute the following statements:
GRANT select on T2 to C; GRANT select on idx_tab2 to C;
Connect as user C and execute a statement such as the following:
SELECT a.gid
FROM T1 a, T2 b
WHERE b.gid = 5 AND
sdo_filter(a.geometry, b.geometry) = 'TRUE';
|
 Copyright © 1999, 2003 Oracle Corporation All Rights Reserved. |
|