| Oracle® XML Developer's Kit Programmer's Guide 10g Release 1 (10.1) Part Number B10794-01 |
|






|
View PDF |
| Oracle® XML Developer's Kit Programmer's Guide 10g Release 1 (10.1) Part Number B10794-01 |
|
|
View PDF |
This chapter contains these topics:
The single DOM is part of the unified C API, which is a C API for XML, whether the XML is in the database or in documents outside the database. DOM means DOM 2.0 plus non-standard extensions in XDK for XML documents or for Oracle XML DB for XML stored as an XMLType column in a table, usually for performance improvements.
|
Note: Use the new unified C API for new XDK and Oracle XML DB applications. The old C functions are deprecated and supported only for backward compatibility, but will not be enhanced. They will be removed in a future release. |
The unified C API is a programming interface that includes the union of all functionality needed by XDK and Oracle XML DB, with XSLT and XML Schema as primary customers. The DOM 2.0 standard was followed as closely as possible, though some naming changes were required when mapping from the objected-oriented DOM specification to the flat C namespace (overloaded getName() methods changed to getAttrName() and so on).
Unification of the functions is accomplished by conforming contexts: a top-level XML context (xmlctx) intended to share common information between cooperating XML components. Data encoding, error message language, low-level memory allocation callbacks, and so on, are defined here. This information is needed before a document can be parsed and DOM or SAX output.
Both the XDK and the Oracle XML DB need different startup and tear-down functions for both contexts (top-level and service). The initialization function takes implementation-specific arguments and returns a conforming context. A conforming context means that the returned context must begin with a xmlctx; it may have any additional implementation-specific parts following that standard header.
Initialization (getting an xmlctx) is an implementation-specific step. Once that xmlctx has been obtained, unified DOM calls are used, all of which take an xmlctx as the first argument.
This interface (new for release 10.1) supersedes the existing C API. In particular, the oraxml interfaces (top-level, DOM, SAX and XSLT) and oraxsd (Schema) interfaces are deprecated.
When the XML resides in a traditional file system, or the Web, or something similar, the XDK package is used. Again, only for startup are there any implementation-specific steps.
First a top-level xmlctx is needed. This contains encoding information, low-level memory callbacks, error message language, and encoding, and so on (in short, those things which should remain consistent for all XDK components). An xmlctx is allocated with XmlCreate().
xmlctx *xctx; xmlerr err; xctx = (xmlctx *) XmlCreate(&err, "xdk context", "data-encoding", "ascii", ..., NULL);
Once the high-level XML context has been obtained, documents may be loaded and DOM events generated. To generate DOM:
xmldocnode *domctx; xmlerr err; domctx = XmlLoadDom(xctx, &err, "file", "foo.xml", NULL);
To generate SAX events, a SAX callback structure is needed:
xmlsaxcb saxcb = {
UserAttrDeclNotify, /* user's own callback functions */
UserCDATANotify,
...
};
if (XmlLoadSax(xctx, &saxcb, NULL, "file", "foo.xml", NULL) != 0)
/* an error occured */
The tear-down function for an XML context, xmlctx, is XmlDestroy().
Once an xmlctx is obtained, a serialized XML document is loaded with the XmlLoadDom() or XmlLoadSax() functions. Given the Document node, all API DOM functions are available.
XML data occurs in many encodings. You have control over the encoding in three ways:
specify a default encoding to assume for files that are not self-describing
specify the presentation encoding for DOM or SAX
re-encode when a DOM is serialized
Input data is always in some encoding. Some encodings are entirely self-describing, such as UTF-16, which requires a specific BOM before the start of the actual data. A document's encoding may also be specified in the XMLDecl or MIME header. If the specific encoding cannot be determined, your default input encoding is applied. If no default is provided by you, UTF-8 is assumed on ASCII platforms and UTF-E on EBCDIC platforms.
A provision is made for cases when the encoding information of the input document is corrupt. For example, if an ASCII document which contains an XMLDecl saying encoding=ascii is blindly converted to EBCDIC, the new EBCDIC document contains (in EBCDIC), an XMLDecl which claims the document is ASCII, when it is not. The correct behavior for a program which is re-encoding XML data is to regenerate the XMLDecl, not to convert it. The XMLDecl is metadata, not data itself. However, this rule is often ignored, and then the corrupt documents result. To work around this problem, an additional flag is provided which allows the input encoding to be forcibly set, overcoming an incorrect XMLDecl.
The precedence rules for determining input encoding are as follows:
1. Forced encoding as specified by the user.
|
Caution: This can result in a fatal error if there is a conflict. For example, the input document is UTF-16 and starts with a UTF-16 BOM, but the user specifies a forced UTF-8 encoding. Then the parser will object about the conflict. |
2. Protocol specification (HTTP header, and so on).
3. XMLDecl specification is used.
4. User's default input encoding.
5. The default: UTF-8 (ASCII platforms) or UTF-E (EBCDIC platforms).
Once the input encoding has been determined, the document can be parsed and the data presented. You are allowed to choose the presentation encoding; the data will be in that encoding regardless of the original input encoding.
When a DOM is written back out (serialized), you can choose at that time to re-encode the presentation data, and the final serialized document can be in any encoding.
The native string representation in C is NULL-terminated. Thus, the primary DOM interface takes and returns NULL-terminated strings. However, Oracle XML DB data when stored in table form, is not NULL-terminated but length-encoded, so an additional set of length-encoded APIs are provided for the high-frequency cases to improve performance (if you deliberately choose to use them). Either set of functions works.
In particular, the following DOM functions are invoked frequently and have dual APIs:
Table 14-1 NULL-Terminated and Length-Encoded C API Functions
| NULL-Terminated API | Length-Encoded API |
|---|---|
XmlDomGetNodeName() |
XmlDomGetNodeNameLen() |
XmlDomGetNodeLocal() |
XmlDomGetNodeLocalLen() |
XmlDomGetNodeURI() |
XmlDomGetNodeURILen() |
XmlDomGetNodeValue() |
XmlDomGetNodeValueLen() |
XmlDomGetAttrName() |
XmlDomGetAttrNameLen() |
XmlDomGetAttrLocal() |
XmlDomGetAttrLocalLen() |
XmlDomGetAttrURI() |
XmlDomGetAttrURILen() |
XmlDomGetAttrValue() |
XmlDomGetAttrValueLen() |
The API functions typically either return a numeric error code (0 for success, nonzero on failure), or pass back an error code through a variable. In all cases, error codes are stored and the last error can be retrieved with XmlDomGetLastError().
Error messages, by default, are output to stderr. However, you can register an error message callback at initialization time. When an error occurs, that callback will be invoked and no error printed.
There are no special installation or first-use requirements. The XML DOM does not require an ORACLE_HOME. It can run out of a reduced root directory such as those provided on OTN releases.
However, since the XML DOM requires globalization support, the globalization support data files must be present (and found through the environment variables ORACLE_HOME or ORA_NLS10).
The C API for XML can be used for XMLType columns in the database. XML data that is stored in a database table can be accessed in an Oracle Call Interface (OCI) program by initializing the values of OCI handles, such as environment handle, service handle, error handle, and optional parameters. These input values are passed to the function OCIXmlDbInitXmlCtx() and an XML context is returned. After the calls to the C API are made, the context is freed by the function OCIXmlDbFreeXmlCtx().
An XML context is a required parameter in all the C DOM API functions. This opaque context encapsulates information pertaining to data encoding, error message language, and so on. The contents of this XML context are different for XDK applications and for Oracle XML DB applications.
|
Caution: Do not use an XML context for XDK in an XML DB application, or an XML context for XML DB in an XDK application. |
For Oracle XML DB, the two OCI functions that initialize and free an XML context have as their prototypes:
xmlctx *OCIXmlDbInitXmlCtx (OCIEnv *envhp, OCISvcCtx *svchp, OCIError *errhp,
ocixmldbparam *params, ub4 num_params);
void OCIXmlDbFreeXmlCtx (xmlctx *xctx);
|
See Also:
|
New XMLType instances on the client can be constructed using the XmlLoadDom() calls. You first have to initialize the xmlctx, as in the example in Using DOM for XDK. The XML data itself can be constructed from a user buffer, local file, or URI. The return value from these is an (xmldocnode *) which can be used in the rest of the common C API. Finally, the (xmldocnode *) can be cast to a (void *) and directly provided as the bind value if required.
Empty XMLType instances can be constructed using the XmlCreateDocument() call. This would be equivalent to an OCIObjectNew() for other types. You can operate on the (xmldocnode *) returned by the above call and finally cast it to a (void *) if it needs to be provided as a bind value.
XML data on the server can be operated on by means of OCI statement calls. You can bind and define XMLType values using xmldocnode, as with other object instances. OCI statements are used to select XML data from the server. This data can be used in the C DOM functions directly. Similarly, the values can be bound back to SQL statements directly.
The following table describes a few of the functions for XML operations.
Table 14-2 XMLType Functions
| Description | Function Name |
|---|---|
Create empty XMLType instance |
XmlCreateDocument() |
| Create from a source buffer | XmlLoadDom() and so on |
Extract an XPath expression |
XmlXPathEvalexpr() and family |
| Transform using an XSL stylesheet | XmlXslProcess() and family |
Check if an XPath exists |
XmlXPathEvalexpr() and family |
| Is document schema-based? | XmlDomIsSchemaBased() |
| Get schema information | XmlDomGetSchema() |
| Get document namespace | XmlDomGetNodeURI() |
| Validate using schema | XmlSchemaValidate() |
Obtain DOM from XMLType |
Cast (void *) to (xmldocnode *) |
Obtain XMLType from DOM |
Cast (xmldocnode *) to (void *) |
Here is an example of how to construct a schema-based document using the DOM API and save it to the database (you must include the header files xml.h and ocixmldb.h):
#include <xml.h>
#include <ocixmldb.h>
static oratext tlpxml_test_sch[] = "<TOP xmlns='example1.xsd'\n\
xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance' \n\
xsi:schemaLocation='example1.xsd example1.xsd'/>";
void example1()
{
OCIEnv *envhp;
OCIError *errhp;
OCISvcCtx *svchp;
OCIStmt *stmthp;
OCIDuration dur;
OCIType *xmltdo;
xmldocnode *doc;
ocixmldbparam params[1];
xmlnode *quux, *foo, *foo_data;
xmlerr err;
/* Initialize envhp, svchp, errhp, dur, stmthp */
/* ........ */
/* Get an xml context */
params[0].name_ocixmldbparam = XCTXINIT_OCIDUR;
params[0].value_ocixmldbparam = &dur;
xctx = OCIXmlDbInitXmlCtx(envhp, svchp, errhp, params, 1);
/* Start processing */
printf("Supports XML 1.0: %s\n",
XmlHasFeature(xctx, (oratext *) "xml", (oratext *) "1.0") ?
"YES" : "NO");
/* Parsing a schema-based document */
if (!(doc = XmlLoadDom(xctx, &err, "buffer", tlpxml_test_sch,
"buffer_length", sizeof(tlpxml_test_sch)-1,
"validate", TRUE, NULL)))
{
printf("Parse failed, code %d\n");
return;
}
/* Create some elements and add them to the document */
top = XmlDomGetDocElem(xctx, doc);
quux = (xmlnode *) XmlDomCreateElem(xctx ,doc, (oratext *) "QUUX");
foo = (xmlnode *) XmlDomCreateElem(xctx, doc, (oratext *) "FOO");
foo_data = (xmlnode *) XmlDomCreateText(xctx, doc, (oratext *)"foo's data");
foo_data = XmlDomAppendChild(xctx, (xmlnode *) foo, (xmlnode *) foo_data);
foo = XmlDomAppendChild(xctx, quux, foo);
quux = XmlDomAppendChild(xctx, top, quux);
XmlSaveDom(xctx, &err, top, "stdio", stdout, NULL);
XmlSaveDom(xctx, &err, doc, "stdio", stdout, NULL);
/* Insert the document to my_table */
ins_stmt = "insert into my_table values (:1)";
status = OCITypeByName(envhp, errhp, svchp, (const text *) "SYS",
(ub4) strlen((char *)"SYS"), (const text *) "XMLTYPE",
(ub4) strlen((char *)"XMLTYPE"), (CONST text *) 0,
(ub4) 0, dur, OCI_TYPEGET_HEADER,
(OCIType **) &xmltdo)) ;
if (status == OCI_SUCCESS)
{
exec_bind_xml(svchp, errhp, stmthp, (void *)doc, xmltdo, ins_stmt));
}
/* free xml ctx */
OCIXmlDbFreeXmlCtx(xctx);
}
/*--------------------------------------------------------*/
/* execute a sql statement which binds xml data */
/*--------------------------------------------------------*/
sword exec_bind_xml(svchp, errhp, stmthp, xml, xmltdo, sqlstmt)
OCISvcCtx *svchp;
OCIError *errhp;
OCIStmt *stmthp;
void *xml;
OCIType *xmltdo;
OraText *sqlstmt;
{
OCIBind *bndhp1 = (OCIBind *) 0;
OCIBind *bndhp2 = (OCIBind *) 0;
sword status = 0;
OCIInd ind = OCI_IND_NOTNULL;
OCIInd *indp = &ind;
if(status = OCIStmtPrepare(stmthp, errhp, (OraText *)sqlstmt,
(ub4)strlen((char *)sqlstmt),
(ub4) OCI_NTV_SYNTAX, (ub4) OCI_DEFAULT)) {
return OCI_ERROR;
}
if(status = OCIBindByPos(stmthp, &bndhp1, errhp, (ub4) 1, (dvoid *) 0,
(sb4) 0, SQLT_NTY, (dvoid *) 0, (ub2 *)0,
(ub2 *)0, (ub4) 0, (ub4 *) 0, (ub4) OCI_DEFAULT)) {
return OCI_ERROR;
}
if(status = OCIBindObject(bndhp1, errhp, (CONST OCIType *) xmltdo,
(dvoid **) &xml, (ub4 *) 0, (dvoid **) &indp, (ub4 *) 0)) {
return OCI_ERROR;
}
if(status = OCIStmtExecute(svchp, stmthp, errhp, (ub4) 1, (ub4) 0,
(CONST OCISnapshot*) 0, (OCISnapshot*) 0, (ub4) OCI_DEFAULT)) {
return OCI_ERROR;
}
return OCI_SUCCESS;
}
Here is an example of how to get a document from the database and modify it using the DOM API:
#include <xml.h>
#include <ocixmldb.h>
sword example2()
{
OCIEnv *envhp;
OCIError *errhp;
OCISvcCtx *svchp;
OCIStmt *stmthp;
OCIDuration dur;
OCIType *xmltdo;
xmldocnode *doc;
xmlnodelist *item_list; ub4 ilist_l;
ocixmldbparam params[1];
text *sel_xml_stmt = (text *)"SELECT xml_col FROM my_table";
ub4 xmlsize = 0;
sword status = 0;
OCIDefine *defnp = (OCIDefine *) 0;
/* Initialize envhp, svchp, errhp, dur, stmthp */
/* ........ */
/* Get an xml context */
params[0].name_ocixmldbparam = XCTXINIT_OCIDUR;
params[0].value_ocixmldbparam = &dur;
xctx = OCIXmlDbInitXmlCtx(envhp, svchp, errhp, params, 1);
/* Start processing */
if(status = OCITypeByName(envhp, errhp, svchp, (const text *) "SYS",
(ub4) strlen((char *)"SYS"), (const text *) "XMLTYPE",
(ub4) strlen((char *)"XMLTYPE"), (CONST text *) 0,
(ub4) 0, dur, OCI_TYPEGET_HEADER,
(OCIType **) xmltdo_p)) {
return OCI_ERROR;
}
if(!(*xmltdo_p)) {
printf("NULL tdo returned\n");
return OCI_ERROR;
}
if(status = OCIStmtPrepare(stmthp, errhp, (OraText *)selstmt,
(ub4)strlen((char *)selstmt),
(ub4) OCI_NTV_SYNTAX, (ub4) OCI_DEFAULT)) {
return OCI_ERROR;
}
if(status = OCIDefineByPos(stmthp, &defnp, errhp, (ub4) 1, (dvoid *) 0,
(sb4) 0, SQLT_NTY, (dvoid *) 0, (ub2 *)0,
(ub2 *)0, (ub4) OCI_DEFAULT)) {
return OCI_ERROR;
}
if(status = OCIDefineObject(defnp, errhp, (OCIType *) *xmltdo_p,
(dvoid **) &doc,
&xmlsize, (dvoid **) 0, (ub4 *) 0)) {
return OCI_ERROR;
}
if(status = OCIStmtExecute(svchp, stmthp, errhp, (ub4) 1, (ub4) 0,
(CONST OCISnapshot*) 0, (OCISnapshot*) 0, (ub4) OCI_DEFAULT)) {
return OCI_ERROR;
}
/* We have the doc. Now we can operate on it */
printf("Getting Item list...\n");
item_list = XmlDomGetElemsByTag(xctx,(xmlelemnode *) elem,(oratext *)"Item");
ilist_l = XmlDomGetNodeListLength(xctx, item_list);
printf(" Item list length = %d \n", ilist_l);
for (i = 0; i < ilist_l; i++)
{
elem = XmlDomGetNodeListItem(xctx, item_list, i);
printf("Elem Name:%s\n", XmlDomGetNodeName(xctx, fragelem));
XmlDomRemoveChild(xctx, fragelem);
}
XmlSaveDom(xctx, &err, doc, "stdio", stdout, NULL);
/* free xml ctx */
OCIXmlDbFreeXmlCtx(xctx);
return OCI_SUCCESS;
}
The XML Parser for C is provided with the Oracle Database and the Oracle Application Server. It is also available for download from the OTN site: http://otn.oracle.com/tech/xml
It is located in $ORACLE_HOME/xdk/ on UNIX systems.
readme.html in the doc directory of the software archive contains release specific information including bug fixes and API additions.
The XML Parser for C checks if an XML document is well-formed, and optionally, validates it against a DTD. The parser constructs an object tree which can be accessed through a DOM interface or the parser operates serially through a SAX interface.
You can post questions, comments, or bug reports to the XML Discussion Forum at http://otn.oracle.com/tech/xml.
There are several sources of information on specifications:
|
See Also:
|
The memory callback functions XML_ALLOC_F and XML_FREE_F can be used if you want to use your own memory allocation. If they are used, both of the functions should be specified.
The memory allocated for parameters passed to the SAX callbacks or for nodes and data stored with the DOM parse tree are not freed until one of the following is done:
XmlFreeDocument() is called.
XmlDestroy() is called.
If threads are forked off somewhere in the init-parse-term sequence of calls, you get unpredictable behavior and results.
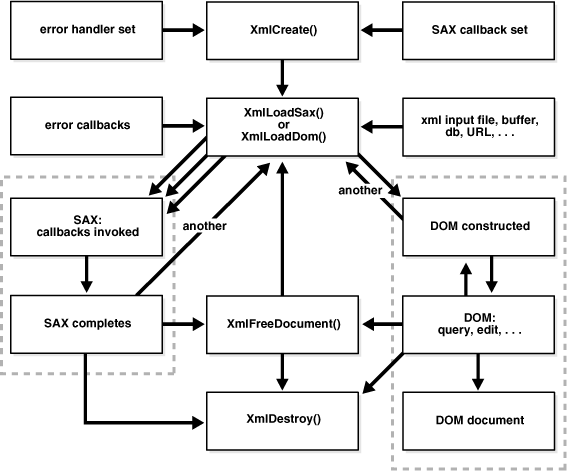
Figure 14-1 describes the XML Parser for C calling sequence as follows:
XmlCreate() function initializes the parsing process.
The parsed item can be an XML document (file) or string buffer. The input is parsed using the XmlLoadDom() function.
DOM or SAX API:
DOM: If you are using the DOM interface, include the following steps:
The XmlLoadDom() function calls XmlDomGetDocElem().
This first step calls other DOM functions as required. These other DOM functions are typically node or print functions that output the DOM document.
You can first invoke XmlFreeDocument() to clean up any data structures created during the parse process.
SAX: If you are using the SAX interface, include the following steps:
Process the results of the parser from XmlLoadSax() using callback functions.
Register the callback functions. Note that any of the SAX callback functions can be set to NULL if not needed.
Use XmlFreeDocument() to clean up the memory and structures used during a parse, and go to Step 5. or return to Step 2.
Terminate the parsing process with XmlDestroy()
The following is the XML Parser for C default behavior:
Character set encoding is UTF-8. If all your documents are ASCII, you are encouraged to set the encoding to US-ASCII for better performance.
Messages are printed to stderr unless an error handler is provided.
The default behavior for the parser is to check that the input is well-formed but not to check whether it is valid. Theproperty "validate" can be set to validate the input. The default behavior for whitespace processing is to be fully conforming to the XML 1.0 specification, that is, all whitespace is reported back to the application but it is indicated which whitespace is ignorable. However, some applications may prefer to set the property "discard-whitespace"which discards all whitespace between an end-element tag and the following start-element tag.
|
Note: It is recommended that you set the default encoding explicitly if using only single byte character sets (such as US-ASCII or any of the ISO-8859 character sets) for performance up to 25% faster than with multibyte character sets, such as UTF-8. |
Oracle XML parser for C checks if an XML document is well-formed, and optionally validates it against a DTD. The parser constructs an object tree which can be accessed through one of the following interfaces:
DOM: Tree-based APIs. A tree-based API compiles an XML document into an internal tree structure, then allows an application to navigate that tree using the Document Object Model (DOM), a standard tree-based API for XML and HTML documents.
Tree-based APIs are useful for a wide range of applications, but they often put a great strain on system resources, especially if the document is large (under very controlled circumstances, it is possible to construct the tree in a lazy fashion to avoid some of this problem). Furthermore, some applications need to build their own, different data trees, and it is very inefficient to build a tree of parse nodes, only to map it onto a new tree.
SAX: Event-based APIs. An event-based API, on the other hand, reports parsing events (such as the start and end of elements) directly to the application through callbacks, and does not usually build an internal tree. The application implements handlers to deal with the different events, much like handling events in a graphical user interface.
An event-based API provides a simpler, lower-level access to an XML document. You can parse documents much larger than your available system memory, and you can construct your own data structures using your callback event handlers.
To use SAX, an xmlsaxcb structure is initialized with function pointers and passed to the XmlLoadSax() call. A pointer to a user-defined context structure can also be included. That context pointer will be passed to each SAX function.
The XML Parser and XSLT Processor can be called as an executable by invoking bin/xml:
xml [options] [document URI] or xml -f [options] [document filespec]
Table 14-4 lists the command line options.
Table 14-4 XML Parser and XSLT Processor: Command Line Options
| Option | Description |
|---|---|
-B BaseUri |
Set the Base URI for XSLT processor: BaseUri of http://pqr/xsl.txt resolves pqr.txt to http://pqr/pqr.txt |
-c |
Conformance check only, no validation. |
-e encoding |
Specify input file encoding. |
-E encoding |
Specify DOM or SAX encoding. |
-f |
File - interpret as filespec, not URI. |
-G xptrexprs |
Evaluates XPointer schema examples given in a file. |
-h |
Help - show this usage. (-hh for more options.) |
-hh |
Show complete options list. |
-i n |
Number of times to iterate the XSLT processing. |
-l language |
Language for error reporting. |
-n |
Number - DOM traverse and report number of elements. |
-o XSLoutfile |
Specifies output file of XSLT processor. |
-p |
Print document and DTD structures after parse. |
-P |
Pretty print from root element. |
-PE encoding |
Specifies encoding for -P or -PP output. |
-PP |
Pretty print from root node (DOC); includes XMLDecl. |
-PX |
Include XMLDecl in output always. |
-r |
Do not ignore <xsl:output> instruction in XSLT processing. |
-s stylesheet |
Specifies the XSLT stylesheet. |
-v |
Version - display parser version then exit. |
-V var value |
Test top-level variables in C XSLT. |
-w |
Whitespace - preserve all whitespace. |
-W |
Warning - stop parsing after a warning. |
| -x | Exercise SAX interface and print document. |
XML Parser for C can also be invoked by writing code to use the supplied APIs. The code must be compiled using the headers in the include/ subdirectory and linked against the libraries in the lib/ subdirectory. Please see the Makefile in the demo/c/ subdirectory for full details of how to build your program.
The $ORACLE_HOME/xdk/demo/c/ directory contains several XML applications to illustrate how to use the XML Parser for C with the DOM and SAX interfaces.
To build the sample programs, change directories to the sample directory ($ORACLE_HOME/xdk/demo/c/ on UNIX) and read the README file. This file explains how to build the sample programs.
Table 14-5 lists the sample files:
Table 14-5 XML Parser for C Sample Files
| Sample File Name | Description |
|---|---|
|
|
Source for DOMNamespace program. |
|
|
Expected output from DOMNamespace. |
|
|
Source for DOMSample program. |
|
|
Expected output from DOMSample. |
|
|
Sample usage of DOM interface. |
|
|
Expected output from FullDOM. |
|
|
Batch file for building sample programs. |
|
|
Sample XML file using namespaces. |
|
|
Source for SAXNamespace program. |
|
|
Expected output from SAXNamespace. |
|
|
Source for SAXSample program. |
|
|
Expected output from SAXSample. |
|
|
Source for XSLSample program. |
|
|
Expected output from XSLSample. |
|
|
Source for XVMSample program. |
|
|
Expected output from XVMSample. |
|
|
Source for XSLXPathSample program. |
|
|
Expected output from XSLXPathSample program. |
|
|
Source for XVMXPathSample program. |
|
|
Expected output from XVMXPathSample program. |
|
|
XML file that may be used with XSLSample. |
|
|
Stylesheet that may be used with XSLSample. |
|
|
The Tragedy of Antony and Cleopatra, XML version of Shakespeare's play. |
Table 14-6 lists the programs built by the sample files:
Table 14-6 XML Parser for C: Sample Built Programs
| Built Program | Description |
|---|---|
|
|
A sample application using DOM APIs (shows an outline of Cleopatra, that is, the XML elements ACT and SCENE). |
|
|
A sample application using SAX APIs. Given a word, shows all lines in the play Cleopatra containing that word. If no word is specified, 'death' is used. |
|
|
Same as SAXNamespace, except using DOM interface. |
|
|
A sample application using Namespace extensions to SAX API; prints out all elements and attributes of NSExample.xml along with full namespace information. |
|
|
Sample usage of full DOM interface. Exercises all the calls. |
|
|
Sample usage of XSL processor. It takes two file names as input, the XML file and XSL stylesheet |
|
|
Sample usage of the XSLT Virtual Machine and Compiler. It takes two files as input - the XML file and the XSL stylesheet. |
|
|
Sample usage of XSL/XPath processor. It takes an XML file and an XPath expression as input. Generates the result of the evaluated XPath expression. |
|
|
Sample usage of the XSLT Virtual Machine and Compiler. It takes an XML file and an XPath expression as input. Generates the result of the evaluated XPath expression. |
|
 Copyright © 2001, 2003 Oracle Corporation All Rights Reserved. |
|